





在本系列博客中,跟隨 Seasalt.ai 打造全面的現代會議體驗的旅程,從其卑微的開端,到在不同硬件和模型上優化我們的服務,再到集成最先進的自然語言處理系統,最終完全實現我們的協作式現代會議解決方案 SeaMeet。
超越轉錄
我們之前面臨的所有障礙都給了我們一個重要的教訓:我們可以自己把這一切做得更好。 因此,Seasalt.ai 的團隊開始訓練我們自己的聲學和語言模型,以與 Azure 的對話轉錄器相媲美。 微軟在 2019 年的 MS Build 大會上做了一場精彩的演講,展示了 Azure 的語音服務,它既是一個功能強大又非常易於使用的產品。 在驚嘆之餘,我們不得不問自己一個問題:我們從這裡該何去何從? 我們如何才能擴展這個已經很有用的產品呢?現代會議展示了強大的語音轉文本潛力,但僅此而已。 我們知道 Azure 可以傾聽我們的聲音,但如果我們能讓它為我們思考呢? 僅有轉錄稿,雖然產品令人印象深刻,但應用卻有些有限。
通過將現有的語音轉文本技術與能夠從轉錄稿中產生見解的系統相結合,我們可以提供超出預期並預測用戶需求的產品。 我們決定整合三個系統來提高我們 SeaMeet 轉錄稿的整體價值:摘要、主題抽象和行動項提取。 選擇這些系統都是為了減輕用戶的特定痛點。
為了演示,我們將展示在以下簡短的轉錄稿上運行摘要、主題和行動系統的結果:
金:“謝謝你,旭晨,你被靜音了,因為這次通話有很多人。按星號 6 取消靜音。”
旭晨:“好的,我以為只是信號不好。”
金:“是的。”
薩姆:“我剛剛發送了一個單獨的文件,其中包含週二到 30 天的語音數據。你們應該會有一些更新的版本。”
金:“所以肯定會有一些邊緣情況這個方法行不通。我已經在這個例子中發現了一些。它把動詞從那裡拿出來,說說話人是受讓人,而實際上卡羅爾才是受讓人。但這和第二個例子是同樣的模式,你真的希望我是受讓人,因為他們沒有指派傑森,他們是指派自己去告訴傑SON。”
薩姆:“明白了。”
旭晨:“所以這個方法的缺點是你得為它編寫規則。是的,優點是它是一個已經訓練好的模型。你可以進一步訓練它,但我們不必為此投入大量數據。”
金:“雖然它沒有做分類,但它能告訴我們這是一個行動還是其他什麼嗎?”
旭晨:“所以,這裡的訣竅是我們希望助動詞存在,但我們也希望有一些人名。”
薩姆:“對,否則可能是因為。”
旭晨:“是的,如果一個句子中有很多明顯帶有單詞的實例。然而,它們中沒有多少能幫助行動。”摘要
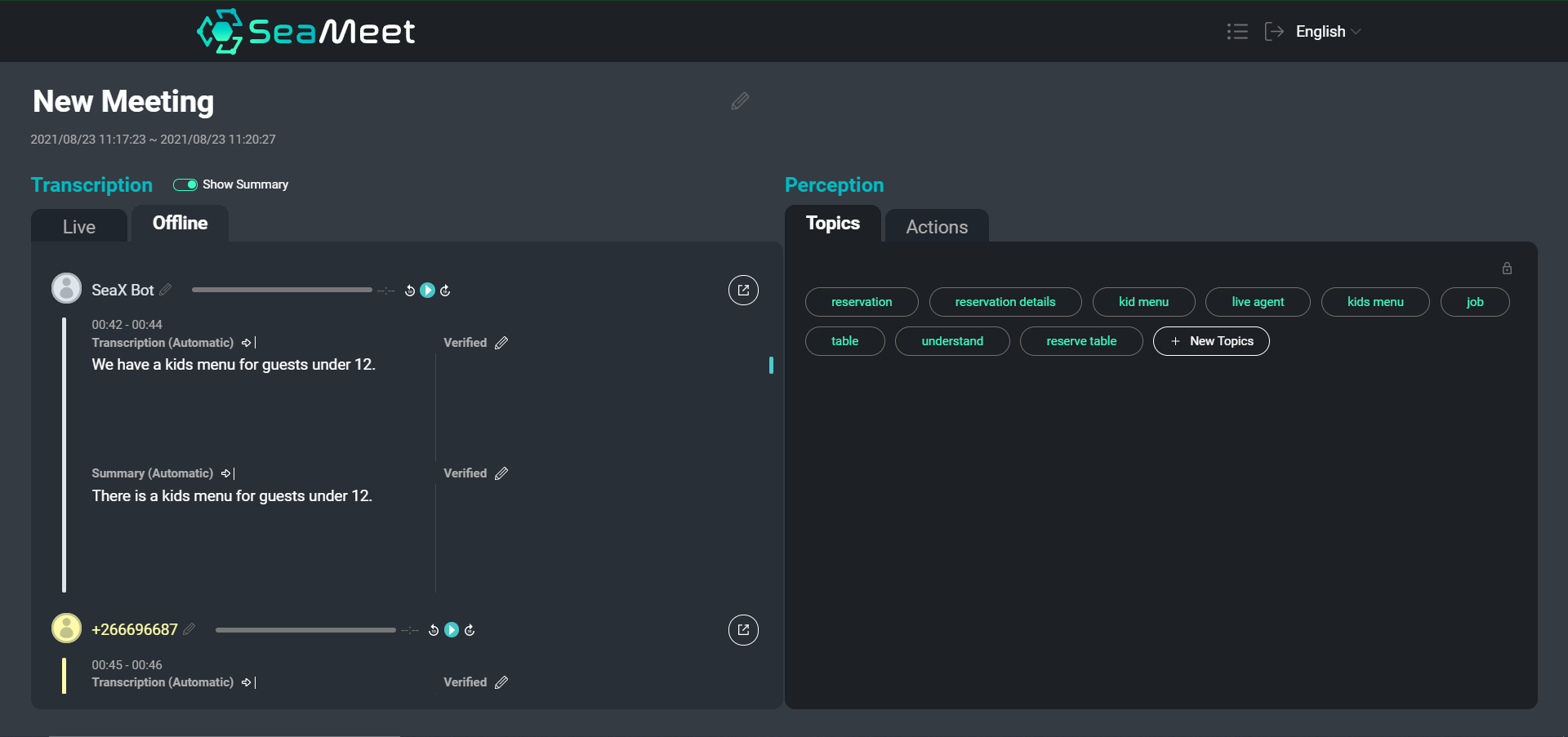
我們的 SeaMeet 界面概覽,左側是用戶的發言及其簡短摘要
雖然瀏覽文本轉錄稿肯定比翻閱數小時的錄音要容易,但對於特別長的會議來說,要找到特定的內容或了解整個對話的概況仍然很耗時。 我們選擇在完整轉錄稿之外提供兩種類型的摘要。
個人發言級別的摘要提供了更簡潔、更易於閱讀的片段。 此外,簡短的摘要通過刪除語義上空洞的片段並執行照應和共指消解來幫助規範化文本。 然後,我們可以將摘要後的片段輸入下游應用程序(例如主題抽象)以改善最終結果。
除了簡短的摘要,我們還選擇提供一個單一的長摘要,旨在創建整個會議的非常籠統的概述。 該摘要的功能類似於會議的摘要,僅涵蓋主要的談話要點和結論。
以下是簡短摘要的示例,我們將原始轉錄稿中的每個片段都通過摘要器進行了處理:
金:“旭晨被靜音了,因為通話中有很多人。”
旭晨:“只是信號不好。”
薩姆:“我發送了一個單獨的文件,其中包含週二到 30 天的語音數據。”
金:“會有一些邊緣情況這個方法行不通。”
旭晨:“訓練一個已經訓練好的模型的缺點是你必須為它編寫規則。”
金:“分類並沒有做那種能給他們一個行動的分類。”
旭晨:“這裡的訣竅是他們希望助動詞存在,但他們也希望有一些人名。”
旭晨:“如果一個句子中有很多單詞,它們中沒有多少能幫助行動。”這個例子顯示了整個會議被總結成一個段落:
“旭晨被靜音了,因為通話中有很多人。薩姆發送了一個單獨的文件,其中包含週二到 30 天的語音數據。旭晨發現了一些說話人是受讓人的邊緣情況。”短摘要和長摘要組件的核心都是一個基於 Transformer 的摘要模型。 我們針對抽象式摘要在對話數據集上對模型進行了微調。 數據包含各種長度的文本摘錄,每個摘錄都配有手寫的摘要。 對於多語言摘要,我們使用相同的範例,但在數據集的翻譯版本上使用經過微調的多語言基礎模型。 在 SeaMeet 界面中,用戶還可以選擇驗證機器生成的摘要,或提供自己的摘要。 然後,我們可以收集這些用戶輸入的摘要,並將它們添加回我們的訓練集,以不斷改進我們的模型。
主題抽象
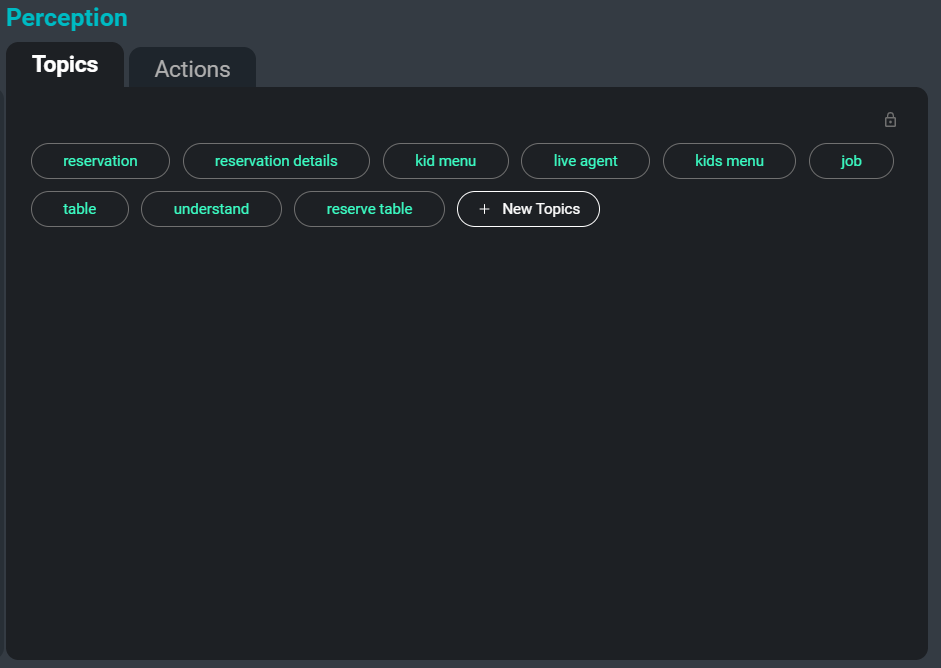
SeaMeet 界面,重點關注右側的“主題”選項卡
處理大量轉錄稿時的另一個問題是組織、分類和搜索它們。 通過自動從轉錄稿中抽象出關鍵詞和主題,我們可以為用戶提供一種輕鬆的方式來追踪某些會議,甚至是正在討論相關主題的會議的特定部分。 此外,這些主題還可以作為另一種方法來總結轉錄稿中最重要和最令人難忘的信息。
以下是從示例轉錄稿中提取的關鍵詞示例:
助動詞
說話人
語音數據
單獨的文件
更新的版本
人名
訓練好的模型
編寫規則主題提取任務結合了抽象式和抽取式方法。 抽象式是指一種文本分類方法,其中每個輸入都被分類到訓練期間看到的一組標籤中。 對於這種方法,我們使用了一個在與相關主題列表配對的文檔上訓練的神經架構。 抽取式是指一種關鍵詞搜索方法,其中從提供的文本中提取相關的關鍵詞並作為主題返回。 對於這種方法,我們結合使用餘弦相似度和 TF-IDF 等相似性度量以及詞共現信息來提取最相關的關鍵詞和短語。
抽象式和抽取式技術各有優缺點,但通過將它們結合使用,我們可以利用各自的優勢。 抽象模型非常擅長收集不同但相關的細節,並找到一個稍微更通用的主題來適應所有這些細節。 然而,它永遠無法預測它在訓練期間沒有見過的主題,而且不可能對對話中可能出現的每一個可以想像的主題進行訓練! 另一方面,抽取式模型可以直接從文本中提取關鍵詞和主題,這意味著它與領域無關,並且可以提取它以前從未見過的主題。 這種方法的缺點是,有時主題過於相似或過於具體。 通過同時使用這兩種方法,我們在通用性和領域特異性之間找到了一個愉快的中間地帶。
行動項提取
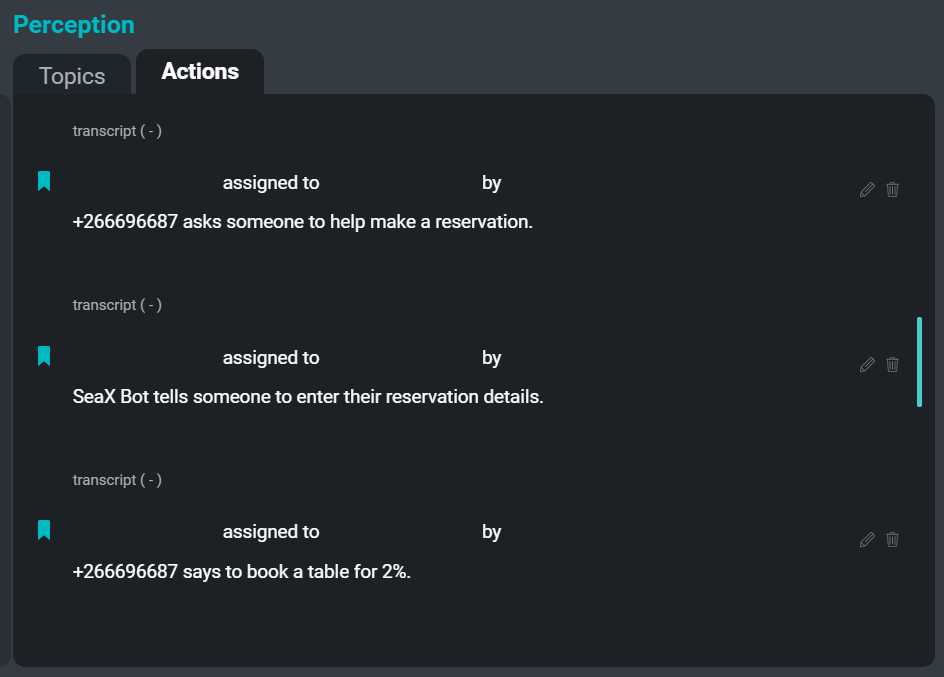
SeaMeet 用戶界面,重點關注右側的“行動”選項卡
我們著手為用戶減輕的最後一個痛點是記錄行動項的任務。 記錄行動項是在會議期間分配給員工的一項非常常見的任務。 寫下“誰告訴誰在什麼時候做什麼”可能非常耗時,並可能導致作者分心,無法完全參與會議。 通過自動化這個過程,我們希望減輕用戶的部分責任,以便每個人都能全身心地投入到會議中。
以下是從示例轉錄稿中可以提取的一些行動項的示例:
建議:“薩姆說團隊應該有一些更新的版本。”
聲明:“金說肯定會有一些邊緣情況這個方法行不通。”
命令:“旭晨說有人必須為它編寫規則。”
願望:“旭晨說團隊希望助動詞存在,但也希望有一些人名。”行動提取器系統的目的是從會議轉錄稿中提取的行動項創建簡短的抽象摘要。 在會議轉錄稿上運行行動提取器的結果是一個命令、建議、意向聲明和其他可操作片段的列表,可以作為會議參與者的待辦事項或後續行動呈現。 將來,提取器還將捕獲受讓人和分配人的姓名以及與每個行動項相關的截止日期。
行動提取管道有兩個主要組件:一個分類器和一個摘要器。 首先,每個片段都被傳遞到一個多類分類器中,並接收以下標籤之一:
- 問題
- 命令
- 建議
- 願望
- 聲明
- 不可操作
如果片段收到除“不可操作”之外的任何標籤,它將與轉錄稿中的前兩個片段一起發送到摘要組件,這為摘要提供了更多上下文。 摘要步驟與獨立的摘要組件基本相同,但是,該模型是在專門為以所需輸出格式總結行動項而構建的定制數據集上進行訓練的。
SeaMeet 有了大腦
這是朝著創造我們自己獨特產品邁出的一大步:訓練摘要以及主題和行動提取模型,以進一步推動我們的產品,並設計一個漂亮的界面,將所有東西都融入一個令人驚嘆的包中。 這就是迄今為止的故事,Seasalt.ai 為快速發展的市場帶來最佳業務解决方案並向世界交付 SeaMeet:現代會議的未來的旅程的開始。