





Tout au long de cette série de blogs, suivez le parcours de Seasalt.ai pour créer une expérience de réunions modernes complète, de ses humbles débuts à l’optimisation de notre service sur différents matériels et modèles, en passant par l’intégration de systèmes de PNL de pointe et enfin la réalisation complète de SeaMeet, nos solutions de réunions modernes et collaboratives.
Au-delà de la transcription
Tous les obstacles que nous avons rencontrés nous ont appris une leçon importante : nous pouvions faire tout cela mieux par nous-mêmes. L’équipe de Seasalt.ai a donc entrepris de former ses propres modèles acoustiques et linguistiques pour rivaliser avec les capacités du transcripteur conversationnel d’Azure. Microsoft a fait une présentation étonnante lors de la MS Build 2019, présentant les services vocaux d’Azure comme un produit à la fois très performant et très accessible. Après avoir été impressionnés, nous sommes obligés de nous poser la question : où allons-nous à partir de maintenant ? Comment pouvons-nous développer ce produit déjà très utile ? Les réunions modernes ont démontré un potentiel de synthèse vocale robuste, mais c’est là que ça s’arrête. Nous savons qu’Azure peut nous écouter, mais que se passerait-il si nous pouvions le faire penser pour nous ? Avec de simples transcriptions, bien que le produit soit impressionnant, les applications sont quelque peu limitées.
En intégrant la technologie de synthèse vocale existante à des systèmes capables de produire des informations à partir des transcriptions, nous pouvons fournir un produit qui dépasse les attentes et anticipe les besoins des utilisateurs. Nous avons décidé d’intégrer three systèmes pour améliorer la valeur globale de nos transcriptions SeaMeet : le résumé, l’abstraction de sujets et l’extraction d’éléments d’action. Chacun d’entre eux a été choisi pour soulager les points de douleur spécifiques des utilisateurs.
Pour le démontrer, nous allons montrer le résultat de l’exécution des systèmes de résumés, de sujets et d’actions sur la courte transcription suivante :
Kim : « Merci, Xuchen, vous êtes en sourdine parce que beaucoup de gens sont sur cet appel. Appuyez sur étoile 6 pour réactiver le son. »
Xuchen : « OK, je pensais que c'était juste une mauvaise réception. »
Kim : « Ouais. »
Sam : « Je viens d'envoyer un fichier séparé avec des données vocales pour les mardis jusqu'à 30 jours. Vous devriez avoir des versions mises à jour. »
Kim : « Il y aura donc certainement des cas limites où cela ne fonctionnera pas. J'en ai déjà trouvé quelques-uns comme dans cet exemple. Il prend le verbe et dit que l'orateur est le cessionnaire alors que c'est vraiment plus Carol qui est le cessionnaire. Mais c'est le même schéma que quelque chose comme le second où vous voulez vraiment que je sois le cessionnaire parce qu'ils n'assignent pas Jason, ils s'assignent eux-mêmes pour le dire à Jason. »
Sam : « Compris. »
Xuchen : « Donc, l'inconvénient de cela, c'est qu'il faut en quelque sorte écrire des règles pour cela. Oui, l'avantage, c'est que c'est un modèle déjà entraîné. Vous pouvez l'entraîner davantage, mais nous n'avons pas à y jeter une tonne de données. »
Kim : « Bien qu'il ne fasse pas la classification qui nous donnerait Est-ce une action ou est-ce autre chose ? »
Xuchen : « Donc, l'astuce ici, c'est que nous voulons que le verbe auxiliaire soit présent, mais nous voulons aussi des noms de personnes. »
Sam : « C'est vrai, sinon, c'est peut-être parce que. »
Xuchen : « Oui, s'il y a une phrase avec, vous savez, beaucoup d'instances avec des mots évidents. Cependant, peu d'entre eux aideraient les actions. »Résumé
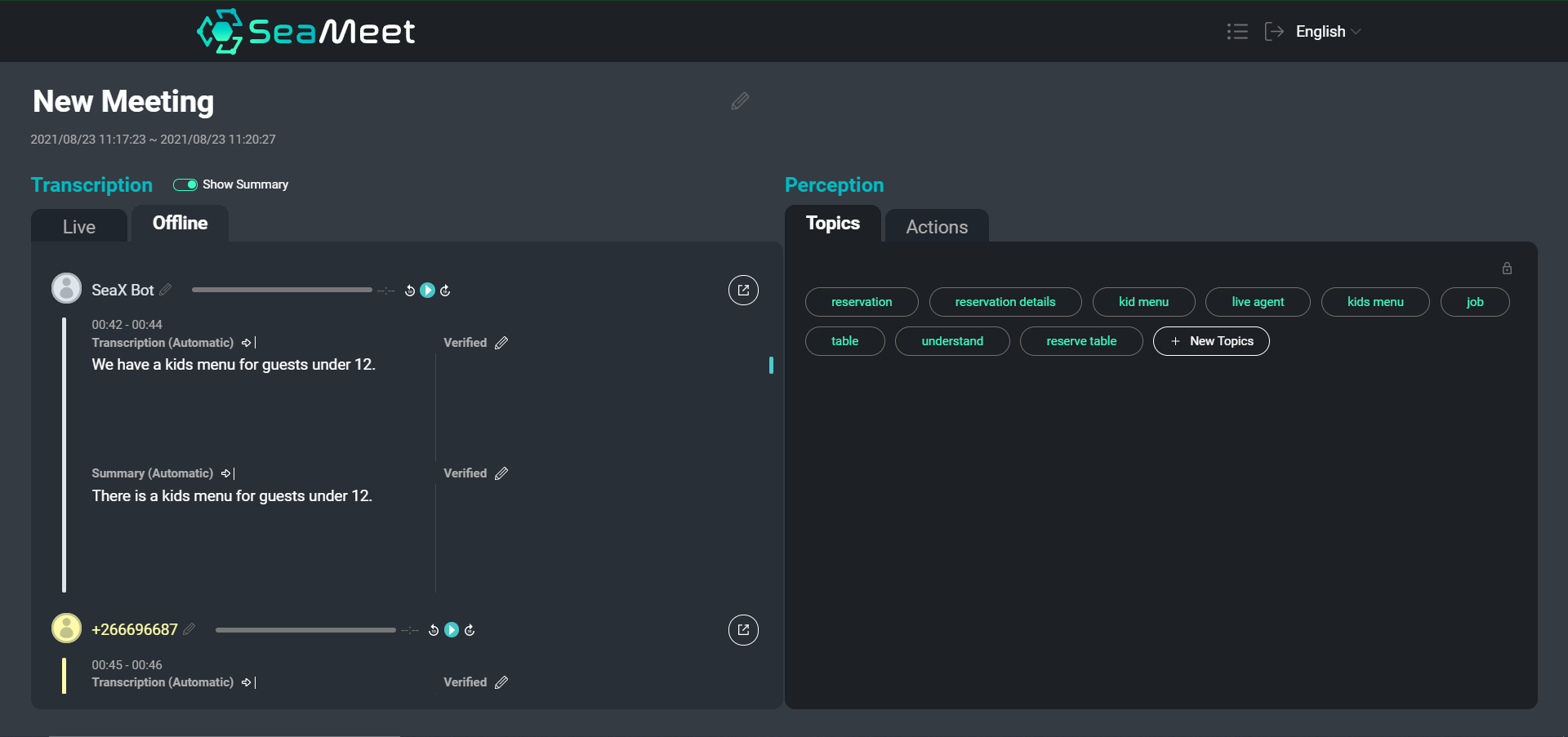
Un aperçu de notre interface SeaMeet, présentant les énoncés des utilisateurs avec leurs courts résumés à gauche
Bien que la navigation dans une transcription textuelle soit certainement plus facile que de fouiller dans des heures d’audio enregistré, pour des réunions particulièrement longues, il peut encore être long de trouver un contenu spécifique ou d’obtenir un aperçu de la conversation dans son ensemble. Nous avons choisi de fournir deux types de résumés en plus de la transcription complète.
Les résumés au niveau de l’énoncé individuel fournissent des segments plus concis et plus faciles à lire. De plus, les résumés courts aident à normaliser le texte en supprimant les segments sémantiquement vides et en effectuant une résolution d’anaphores et de coréférences. Nous pouvons ensuite alimenter les segments résumés dans des applications en aval (telles que l’abstraction de sujets) pour améliorer les résultats finaux.
En plus des résumés courts, nous avons également choisi de fournir un seul résumé long qui vise à créer un aperçu très général de l’ensemble de la réunion. Ce résumé fonctionne comme un résumé de la réunion, ne couvrant que les principaux points de discussion et conclusions.
Voici un exemple de résumés courts, où nous avons passé chaque segment de la transcription originale dans le résumeur :
Kim : « Xuchen est en sourdine parce que beaucoup de gens sont sur l'appel. »
Xuchen : « C'est juste une mauvaise réception. »
Sam : « J'ai envoyé un fichier séparé avec des données vocales pour les mardis jusqu'à 30 jours. »
Kim : « Il y aura des cas limites où cela ne fonctionnera pas. »
Xuchen : « L'inconvénient d'entraîner un modèle déjà entraîné est qu'il faut écrire des règles pour cela. »
Kim : « La classification ne fait pas la classification qui leur donnerait une action. »
Xuchen : « L'astuce ici est qu'ils veulent que le verbe auxiliaire soit présent, mais ils veulent aussi des noms de personnes. »
Xuchen : « S'il y a une phrase avec des mots, peu d'entre eux aideraient les actions. »Et cet exemple montre l’ensemble de la réunion résumée en un seul paragraphe :
« Xuchen est en sourdine parce que beaucoup de gens sont sur l'appel. Sam a envoyé un fichier séparé avec des données vocales pour les mardis jusqu'à 30 jours. Xuchen a trouvé des cas limites où l'orateur est le cessionnaire. »Au cœur des deux composants de résumé, le court et le long, se trouve un modèle de résumé basé sur un transformateur. Nous affinons le modèle sur un ensemble de données de dialogue pour le résumé abstractif. Les données contiennent des extraits de texte de différentes longueurs, chacun associé à un résumé manuscrit. Pour le résumé multilingue, nous utilisons le même paradigme, mais nous utilisons un modèle de base multilingue affiné sur une version traduite de l’ensemble de données. Depuis l’interface SeaMeet, l’utilisateur a également la possibilité de vérifier un résumé produit par la machine ou de fournir le sien. Nous pouvons ensuite collecter ces résumés saisis par l’utilisateur et les rajouter à notre ensemble d’entraînement pour améliorer continuellement nos modèles.
Abstraction de sujets
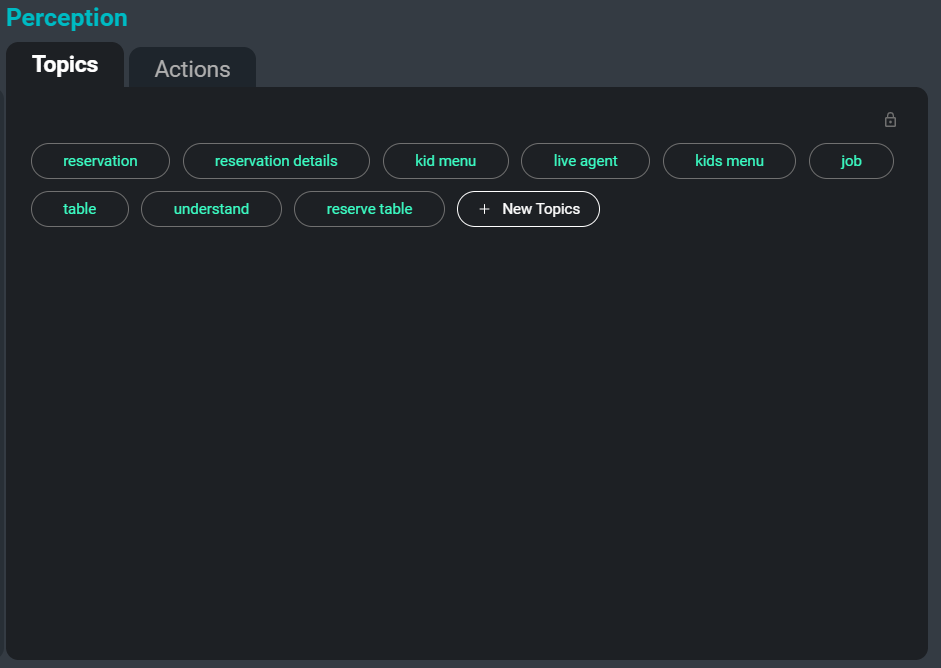
L’interface SeaMeet, axée sur l’onglet « Sujets » sur le côté droit
Un autre problème lors du traitement de grandes collections de transcriptions est de les organiser, de les catégoriser et de les rechercher. En extrayant automatiquement des mots-clés et des sujets de la transcription, nous pouvons offrir aux utilisateurs un moyen simple de retrouver certaines réunions, ou même des sections spécifiques de réunions où un sujet pertinent est en discussion. De plus, ces sujets servent de méthode supplémentaire pour résumer les informations les plus importantes et les plus mémorables d’une transcription.
Voici un exemple de mots-clés qui seraient extraits de l’exemple de transcription :
verbe auxiliaire
orateur
données vocales
fichier séparé
versions mises à jour
noms de personnes
modèle entraîné
écrire des règlesLa tâche d’extraction de sujets utilise une combinaison d’approches abstractives et extractives. Abstractif fait référence à une approche de classification de texte, où chaque entrée est classée dans un ensemble d’étiquettes vues pendant l’entraînement. Pour cette méthode, nous avons utilisé une architecture neuronale entraînée sur des documents associés à une liste de sujets pertinents. Extractif fait référence à une approche de recherche de phrases clés où les phrases clés pertinentes sont extraites du texte fourni et renvoyées en tant que sujets. Pour cette approche, nous utilisons une combinaison de mesures de similarité telles que la similarité cosinus et le TF-IDF en plus des informations de co-occurrence de mots pour extraire les mots-clés et les phrases les plus pertinents.
Les techniques abstractives et extractives ont toutes deux des avantages et des inconvénients, mais en les utilisant ensemble, nous pouvons tirer parti des atouts de chacune. Le modèle abstractif est excellent pour collecter des détails distincts mais liés et trouver un sujet légèrement plus générique qui leur convient à tous. Cependant, il ne peut jamais prédire un sujet qu’il n’a pas vu pendant l’entraînement, et il est impossible de s’entraîner sur tous les sujets imaginables qui peuvent survenir dans une conversation ! Les modèles extractifs, en revanche, peuvent extraire des mots-clés et des sujets directement du texte, ce qui signifie qu’ils sont indépendants du domaine et peuvent extraire des sujets qu’ils n’ont jamais vus auparavant. L’inconvénient de cette approche est que les sujets sont parfois trop similaires ou trop spécifiques. En utilisant les deux, nous avons trouvé un juste milieu entre généralisable et spécifique au domaine.
Extraction d’éléments d’action
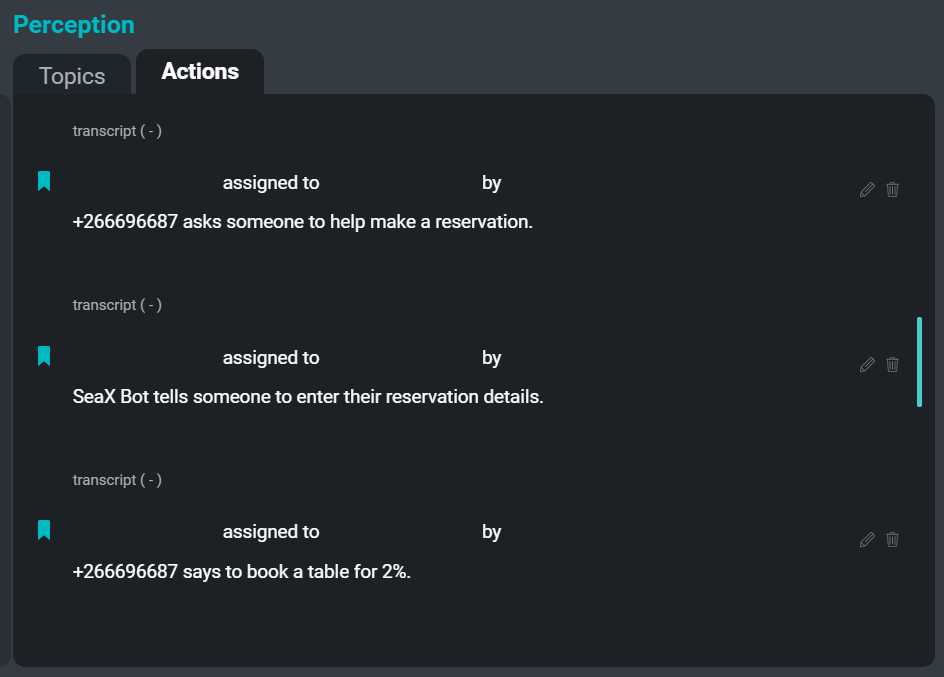
L’interface utilisateur de SeaMeet, axée sur l’onglet « Actions » sur le côté droit
Le dernier point de douleur que nous nous sommes efforcés de soulager pour les utilisateurs est la tâche d’enregistrer les éléments d’action. L’enregistrement des éléments d’action est une tâche très courante qui est assignée à un employé pendant une réunion. Écrire « qui a dit à qui de faire quoi et quand » peut prendre beaucoup de temps et peut distraire l’auteur et l’empêcher de participer pleinement à la réunion. En automatisant ce processus, nous espérons soulager une partie de cette responsabilité de l’utilisateur afin que chacun puisse consacrer toute son attention à la participation à la réunion.
Voici un exemple de quelques éléments d’action qui pourraient être extraits de l’exemple de transcription :
suggestion : « Sam dit que l'équipe devrait avoir des versions mises à jour. »
déclaration : « Kim dit qu'il y aura certainement des cas limites où cela ne fonctionnera pas. »
impératif : « Xuchen dit que quelqu'un doit écrire des règles pour cela. »
désir : « Xuchen dit que l'équipe veut que le verbe auxiliaire soit présent, mais veut aussi des noms de personnes. »Le but du système d’extraction d’actions est de créer de courts résumés abstractifs d’éléments d’action extraits des transcriptions de réunions. Le résultat de l’exécution de l’extracteur d’actions sur une transcription de réunion est une liste de commandes, de suggestions, de déclarations d’intention et d’autres segments exploitables qui peuvent être présentés comme des tâches à faire ou des suivis pour les participants à la réunion. À l’avenir, l’extracteur capturera également les noms des cessionnaires et des cédants ainsi que les dates d’échéance liées à chaque élément d’action.
Le pipeline d’extraction d’actions comporte deux composants principaux : un classificateur et un résumeur. Premièrement, chaque segment est passé dans un classificateur multi-classes et reçoit l’une des étiquettes suivantes :
- Question
- Impératif
- Suggestion
- Désir
- Déclaration
- Non exploitable
Si le segment reçoit une étiquette autre que « non exploitable », il est envoyé au composant de résumé avec les deux segments précédents de la transcription, qui fournissent plus de contexte pour le résumé. L’étape de résumé est essentiellement la même que le composant de résumé autonome, mais le modèle est entraîné sur un ensemble de données sur mesure construit spécifiquement pour résumer les éléments d’action avec un format de sortie souhaité.
SeaMeet se dote d’un cerveau
Cela a été un grand pas vers la création de notre propre produit unique : l’entraînement de modèles de résumé et d’extraction de sujets et d’actions pour faire progresser notre produit, et la conception d’une belle interface pour lier le tout dans un emballage époustouflant. C’est l’histoire jusqu’à présent, le début du parcours de Seasalt.ai pour apporter les meilleures solutions commerciales à un marché en évolution rapide et livrer au monde, SeaMeet : l’avenir des réunions modernes.


