





Di seluruh seri blog ini, ikuti perjalanan Seasalt.ai dalam menciptakan Pengalaman Rapat Modern yang menyeluruh, mulai dari awal yang sederhana, hingga mengoptimalkan layanan kami pada perangkat keras dan model yang berbeda, hingga mengintegrasikan sistem NLP canggih dan akhirnya berakhir pada realisasi penuh SeaMeet, solusi rapat modern kolaboratif kami.
Melampaui Transkripsi
Semua rintangan sebelumnya yang kami hadapi mengajarkan kami pelajaran penting: bahwa kami dapat melakukan semua ini dengan lebih baik sendiri. Jadi, para kru di Seasalt.ai mulai melatih model akustik dan bahasa kami sendiri untuk menyaingi kemampuan transkripsi percakapan Azure. Microsoft menampilkan presentasi yang luar biasa di MS Build 2019, menampilkan Layanan Pidato Azure sebagai produk yang sangat mumpuni namun sangat mudah diakses. Setelah dibuat kagum, kami terpaksa mengajukan pertanyaan, ke mana kita akan melangkah dari sini? Bagaimana kita bisa memperluas produk yang sudah sangat berperan ini? Rapat Modern menunjukkan potensi pidato ke teks yang kuat, tetapi di situlah ia berhenti. Kita tahu Azure dapat mendengarkan kita, tetapi bagaimana jika kita bisa membuatnya berpikir untuk kita? Dengan hanya transkripsi, meskipun produknya mengesankan, aplikasinya agak terbatas.
Dengan mengintegrasikan teknologi pidato-ke-teks yang ada dengan sistem yang dapat menghasilkan wawasan dari transkripsi, kami dapat memberikan produk yang melebihi harapan dan mengantisipasi kebutuhan pengguna. Kami memutuskan untuk memasukkan tiga sistem untuk meningkatkan nilai keseluruhan transkripsi SeaMeet kami: peringkasan, abstraksi topik, dan ekstraksi item tindakan. Masing-masing dipilih untuk meringankan titik-titik nyeri pengguna tertentu.
Untuk mendemonstrasikan, kami akan menunjukkan hasil dari menjalankan sistem peringkasan, topik, dan tindakan pada transkrip singkat berikut:
Kim: "Terima kasih, Xuchen, Anda dibisukan karena banyak orang di panggilan ini. Tekan Bintang 6 untuk membunyikan."
Xuchen: "OK, saya pikir itu hanya penerimaan yang buruk."
Kim: "Ya."
Sam: "Saya baru saja mengirimkan file terpisah dengan data pidato untuk hari Selasa hingga 30 hari. Kalian seharusnya sudah memiliki beberapa versi yang diperbarui."
Kim: "Jadi pasti akan ada kasus-kasus tepi di mana ini tidak berhasil. Saya sudah menemukan beberapa seperti dalam contoh ini. Dibutuhkan seperti kata kerja di sana dan mengatakan pembicara adalah penerima tugas padahal sebenarnya lebih banyak Carol yang menjadi penerima tugas di sana. Tapi itu pola yang sama seperti sesuatu seperti yang kedua di mana Anda benar-benar ingin saya menjadi penerima tugas karena mereka tidak menugaskan Jason, mereka menugaskan diri mereka sendiri untuk memberi tahu Jason."
Sam: "Mengerti."
Xuchen: "Jadi kelemahan dari ini adalah Anda harus menulis aturan untuk itu. Ya, keuntungannya adalah itu sudah menjadi model yang terlatih. Anda dapat melatihnya lebih lanjut tetapi kita tidak perlu membuang banyak data untuk ini."
Kim: "Meskipun tidak melakukan klasifikasi yang akan memberi kita Apakah ini tindakan atau ini yang lain?"
Xuchen: "Jadi, triknya di sini adalah kita ingin kata kerja bantu hadir, tetapi kita juga ingin beberapa nama orang."
Sam: "Benar, jika tidak, mungkin karena."
Xuchen: "Ya, jika ada kalimat dengan, Anda tahu, banyak contoh dengan kata-kata yang jelas. Namun, tidak banyak dari mereka yang akan membantu tindakan."Peringkasan
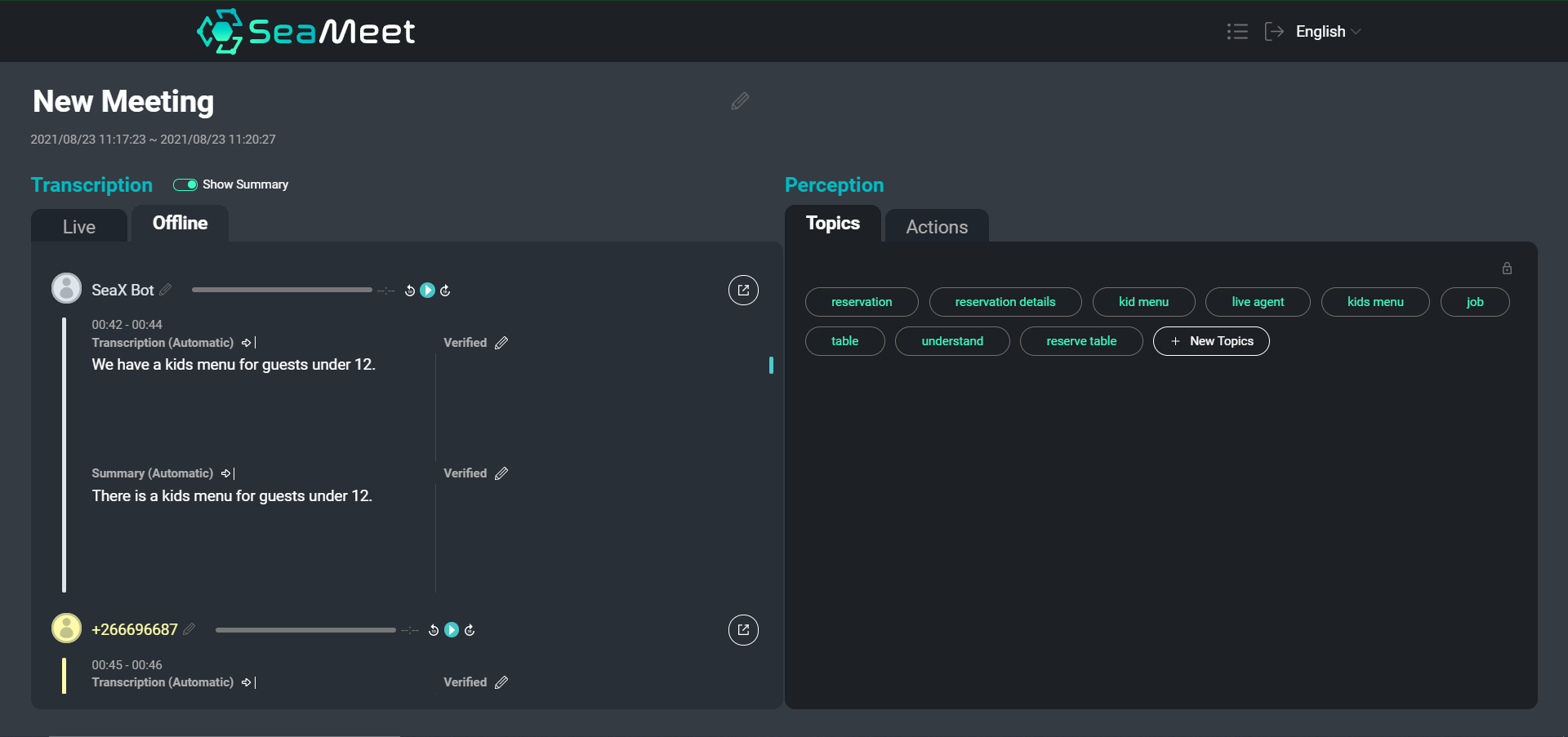
Tinjauan antarmuka SeaMeet kami, menampilkan ucapan pengguna dengan ringkasan singkatnya di sebelah kiri
Meskipun menavigasi transkripsi teks tentu lebih mudah daripada menggali berjam-jam audio yang direkam, untuk rapat yang sangat panjang masih bisa memakan waktu untuk menemukan konten tertentu atau mendapatkan gambaran umum tentang percakapan secara keseluruhan. Kami memilih untuk menyediakan dua jenis ringkasan selain transkripsi lengkap.
Ringkasan di tingkat ucapan individu memberikan segmen yang lebih ringkas dan mudah dibaca. Selain itu, ringkasan singkat membantu menormalkan teks dengan menghapus segmen yang kosong secara semantik dan melakukan resolusi anafora & ko-referensi. Kami kemudian dapat memasukkan segmen yang diringkas ke dalam aplikasi hilir (seperti abstraksi topik) untuk meningkatkan hasil akhir.
Selain ringkasan singkat, kami juga memilih untuk memberikan satu ringkasan panjang yang bertujuan untuk membuat gambaran umum yang sangat umum dari seluruh rapat. Ringkasan ini berfungsi seperti abstrak untuk rapat, hanya mencakup poin-poin pembicaraan utama dan kesimpulan.
Berikut ini adalah contoh ringkasan singkat, di mana kami memasukkan setiap segmen dalam transkrip asli melalui peringkas:
Kim: "Xuchen dibisukan karena banyak orang di panggilan."
Xuchen: "Ini hanya penerimaan yang buruk."
Sam: "Saya mengirim file terpisah dengan data pidato untuk hari Selasa hingga 30 hari."
Kim: "Akan ada kasus-kasus tepi di mana ini tidak berhasil."
Xuchen: "Kelemahan dari melatih model yang sudah terlatih adalah Anda harus menulis aturan untuk itu."
Kim: "Klasifikasi tidak melakukan klasifikasi yang akan memberi mereka tindakan."
Xuchen: "Triknya di sini adalah mereka ingin kata kerja bantu hadir, tetapi mereka juga ingin beberapa nama orang."
Xuchen: "Jika ada kalimat dengan kata-kata, tidak banyak dari mereka yang akan membantu tindakan."Dan contoh ini menunjukkan seluruh rapat yang diringkas menjadi satu paragraf:
"Xuchen dibisukan karena banyak orang di panggilan. Sam mengirim file terpisah dengan data pidato untuk hari Selasa hingga 30 hari. Xuchen telah menemukan beberapa kasus tepi di mana pembicara adalah penerima tugas."Inti dari komponen peringkasan pendek dan panjang adalah model peringkasan berbasis transformator. Kami menyempurnakan model pada kumpulan data dialog untuk peringkasan abstrak. Data berisi kutipan tekstual dengan berbagai panjang yang masing-masing dipasangkan dengan ringkasan tulisan tangan. Untuk peringkasan multibahasa, kami menggunakan paradigma yang sama, tetapi menggunakan model dasar multibahasa yang disempurnakan pada versi terjemahan dari kumpulan data. Dari antarmuka SeaMeet, pengguna juga memiliki opsi untuk memverifikasi ringkasan yang diproduksi mesin, atau memberikan ringkasan mereka sendiri. Kami kemudian dapat mengumpulkan ringkasan yang dimasukkan pengguna ini dan menambahkannya kembali ke set pelatihan kami untuk terus meningkatkan model kami.
Abstraksi Topik
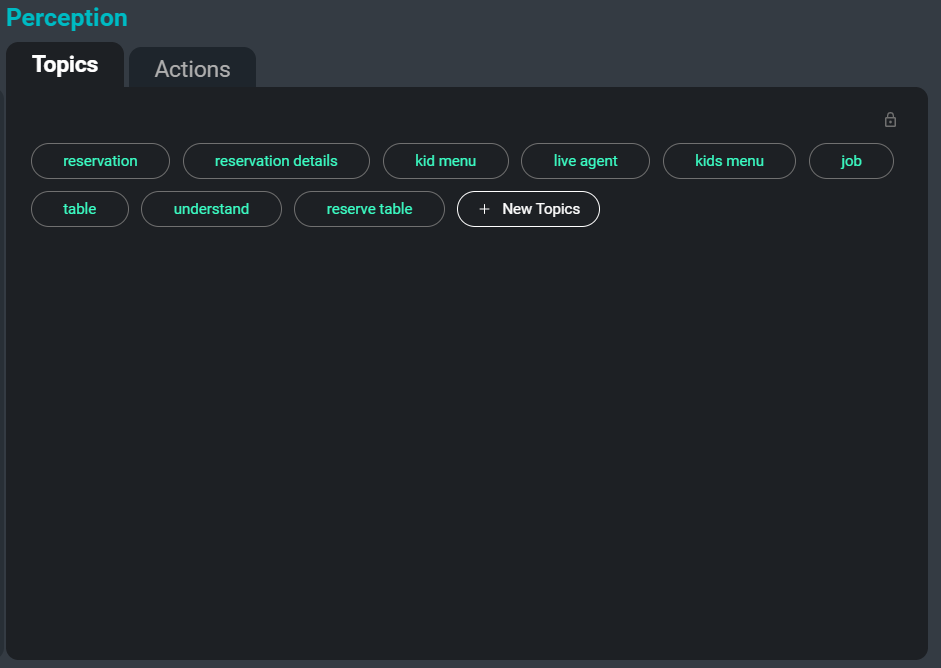
Antarmuka SeaMeet, berfokus pada tab ‘Topik’ di sisi kanan
Masalah lain saat berhadapan dengan banyak koleksi transkripsi adalah mengatur, mengkategorikan, dan mencarinya. Dengan secara otomatis mengabstraksi kata kunci dan topik dari transkrip, kami dapat memberikan cara yang mudah bagi pengguna untuk melacak rapat tertentu, atau bahkan bagian tertentu dari rapat di mana topik yang relevan sedang dibahas. Selain itu, topik-topik ini berfungsi sebagai metode lain untuk meringkas informasi yang paling penting dan mudah diingat dalam sebuah transkrip.
Berikut adalah contoh kata kunci yang akan diekstraksi dari transkrip sampel:
kata kerja bantu
pembicara
data pidato
file terpisah
versi yang diperbarui
nama orang
model terlatih
menulis aturanTugas ekstraksi topik menggunakan kombinasi pendekatan abstrak dan ekstraktif. Abstraktif mengacu pada pendekatan klasifikasi teks, di mana setiap masukan diklasifikasikan ke dalam serangkaian label yang terlihat selama pelatihan. Untuk metode ini kami menggunakan arsitektur saraf yang dilatih pada dokumen yang dipasangkan dengan daftar topik yang relevan. Ekstraktif mengacu pada pendekatan pencarian frasa kunci di mana frasa kunci yang relevan diekstraksi dari teks yang disediakan dan dikembalikan sebagai topik. Untuk pendekatan ini, kami menggunakan kombinasi metrik kesamaan seperti kesamaan kosinus & TF-IDF selain informasi kemunculan bersama kata untuk mengekstrak kata kunci dan frasa yang paling relevan.
Baik teknik abstrak maupun ekstraktif memiliki pro dan kontra, tetapi dengan menggunakannya bersama-sama kita dapat memanfaatkan kekuatan masing-masing. Model abstrak sangat bagus dalam mengumpulkan detail yang berbeda, tetapi terkait dan menemukan topik yang sedikit lebih umum yang cocok untuk semuanya. Namun, ia tidak pernah dapat memprediksi topik yang belum pernah dilihatnya selama pelatihan, dan tidak mungkin untuk melatih setiap topik yang mungkin muncul dalam percakapan! Model ekstraktif, di sisi lain, dapat menarik kata kunci dan topik langsung dari teks, yang berarti independen dari domain, dan dapat mengekstrak topik yang belum pernah dilihatnya sebelumnya. Kelemahan dari pendekatan ini adalah terkadang topiknya terlalu mirip atau terlalu spesifik. Dengan menggunakan keduanya, kami telah menemukan jalan tengah yang membahagiakan antara yang dapat digeneralisasi dan yang spesifik domain.
Ekstraksi Item Tindakan
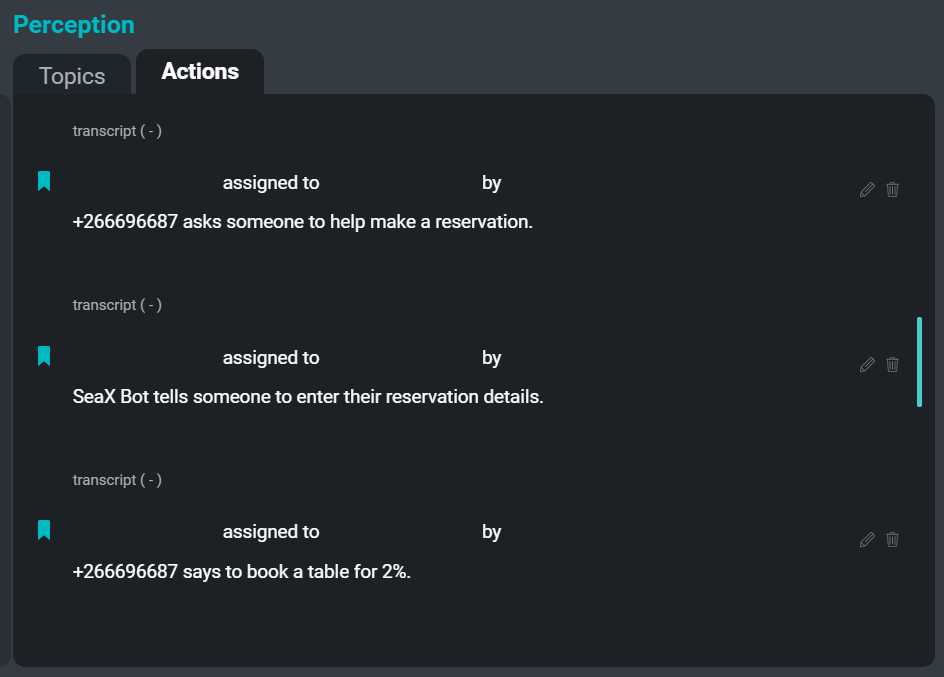
UI SeaMeet, berfokus pada tab ‘Tindakan’ di sisi kanan
Titik sakit terakhir yang kami coba ringankan bagi pengguna adalah tugas mencatat item tindakan. Mencatat item tindakan adalah tugas yang sangat umum yang ditugaskan kepada seorang karyawan untuk dilakukan selama rapat. Menulis ‘siapa yang menyuruh siapa untuk melakukan apa kapan’ bisa sangat memakan waktu, dan dapat menyebabkan penulis terganggu dan tidak dapat berpartisipasi penuh dalam rapat. Dengan mengotomatiskan proses ini, kami berharap dapat meringankan sebagian dari tanggung jawab itu dari pengguna sehingga semua orang dapat mencurahkan perhatian penuh mereka untuk berpartisipasi dalam rapat.
Berikut ini adalah contoh beberapa item tindakan yang dapat diekstraksi dari transkrip contoh:
saran: "Sam mengatakan tim harus memiliki beberapa versi yang diperbarui."
pernyataan: "Kim mengatakan pasti akan ada kasus-kasus tepi di mana ini tidak berhasil."
perintah: "Xuchen mengatakan seseorang harus menulis aturan untuk itu."
keinginan: "Xuchen mengatakan tim ingin kata kerja bantu hadir, tetapi juga ingin beberapa nama orang."Tujuan dari sistem Pengekstrak Tindakan adalah untuk membuat ringkasan abstrak singkat dari item tindakan yang diekstraksi dari transkripsi rapat. Hasil dari menjalankan Pengekstrak Tindakan pada transkripsi rapat adalah daftar perintah, saran, pernyataan niat, dan segmen lain yang dapat ditindaklanjuti yang dapat disajikan sebagai tugas atau tindak lanjut bagi peserta rapat. Di masa mendatang, pengekstrak juga akan menangkap nama-nama penerima tugas & pemberi tugas serta tanggal jatuh tempo yang terkait dengan setiap item tindakan.
Pipa ekstraksi tindakan memiliki dua komponen utama: pengklasifikasi dan peringkas. Pertama, setiap segmen dilewatkan ke pengklasifikasi multi-kelas dan menerima salah satu label berikut:
- Pertanyaan
- Perintah
- Saran
- Keinginan
- Pernyataan
- Tidak dapat ditindaklanjuti
Jika segmen menerima label apa pun selain ‘tidak dapat ditindaklanjuti’, segmen tersebut dikirim ke komponen peringkasan bersama dengan dua segmen sebelumnya dalam transkrip, yang memberikan lebih banyak konteks untuk peringkasan. Langkah peringkasan pada dasarnya sama dengan komponen peringkasan yang berdiri sendiri, namun model dilatih pada kumpulan data pesanan yang dibuat khusus untuk meringkas item tindakan dengan format keluaran yang diinginkan.
SeaMeet Mendapat Otak
Ini telah menjadi langkah besar menuju penciptaan produk unik kami sendiri: melatih model peringkasan plus ekstraksi topik dan tindakan untuk membawa produk kami lebih jauh, dan merancang antarmuka yang indah untuk menyatukan semuanya dalam satu paket yang menakjubkan. Ini adalah ceritanya sejauh ini, awal dari perjalanan Seasalt.ai untuk membawa solusi bisnis terbaik ke pasar yang berkembang pesat dan memberikan kepada dunia, SeaMeet: Masa Depan Rapat Modern.


