





在本系列博客中,跟随 Seasalt.ai 打造全面的现代会议体验的旅程,从其卑微的开端,到在不同硬件和模型上优化我们的服务,再到集成最先进的自然语言处理系统,最终完全实现我们的协作式现代会议解决方案 SeaMeet。
超越转录
我们之前面临的所有障碍都给了我们一个重要的教训:我们可以自己把这一切做得更好。 因此,Seasalt.ai 的团队开始训练我们自己的声学和语言模型,以与 Azure 的对话转录器相媲美。 微软在 2019 年的 MS Build 大会上做了一场精彩的演讲,展示了 Azure 的语音服务,它既是一个功能强大又非常易于使用的产品。 在惊叹之余,我们不得不问自己一个问题:我们从这里该何去何从? 我们如何才能扩展这个已经很有用的产品呢?现代会议展示了强大的语音转文本潜力,但仅此而已。 我们知道 Azure 可以倾听我们的声音,但如果我们能让它为我们思考呢? 仅有转录稿,虽然产品令人印象深刻,但应用却有些有限。
通过将现有的语音转文本技术与能够从转录稿中产生见解的系统相结合,我们可以提供超出预期并预测用户需求的产品。 我们决定整合三个系统来提高我们 SeaMeet 转录稿的整体价值:摘要、主题抽象和行动项提取。 选择这些系统都是为了减轻用户的特定痛点。
为了演示,我们将展示在以下简短的转录稿上运行摘要、主题和行动系统的结果:
金:“谢谢你,旭晨,你被静音了,因为这次通话有很多人。按星号 6 取消静音。”
旭晨:“好的,我以为只是信号不好。”
金:“是的。”
萨姆:“我刚刚发送了一个单独的文件,其中包含周二到 30 天的语音数据。你们应该会有一些更新的版本。”
金:“所以肯定会有一些边缘情况这个方法行不通。我已经在这个例子中发现了一些。它把动词从那里拿出来,说说话人是受让人,而实际上卡罗尔才是受让人。但这和第二个例子是同样的模式,你真的希望我是受让人,因为他们没有指派杰森,他们是指派自己去告诉杰SON。”
萨姆:“明白了。”
旭晨:“所以这个方法的缺点是你得为它编写规则。是的,优点是它是一个已经训练好的模型。你可以进一步训练它,但我们不必为此投入大量数据。”
金:“虽然它没有做分类,但它能告诉我们这是一个行动还是其他什么吗?”
旭晨:“所以,这里的诀窍是我们希望助动词存在,但我们也希望有一些人名。”
萨姆:“对,否则可能是因为。”
旭晨:“是的,如果一个句子中有很多明显带有单词的实例。然而,它们中没有多少能帮助行动。”摘要
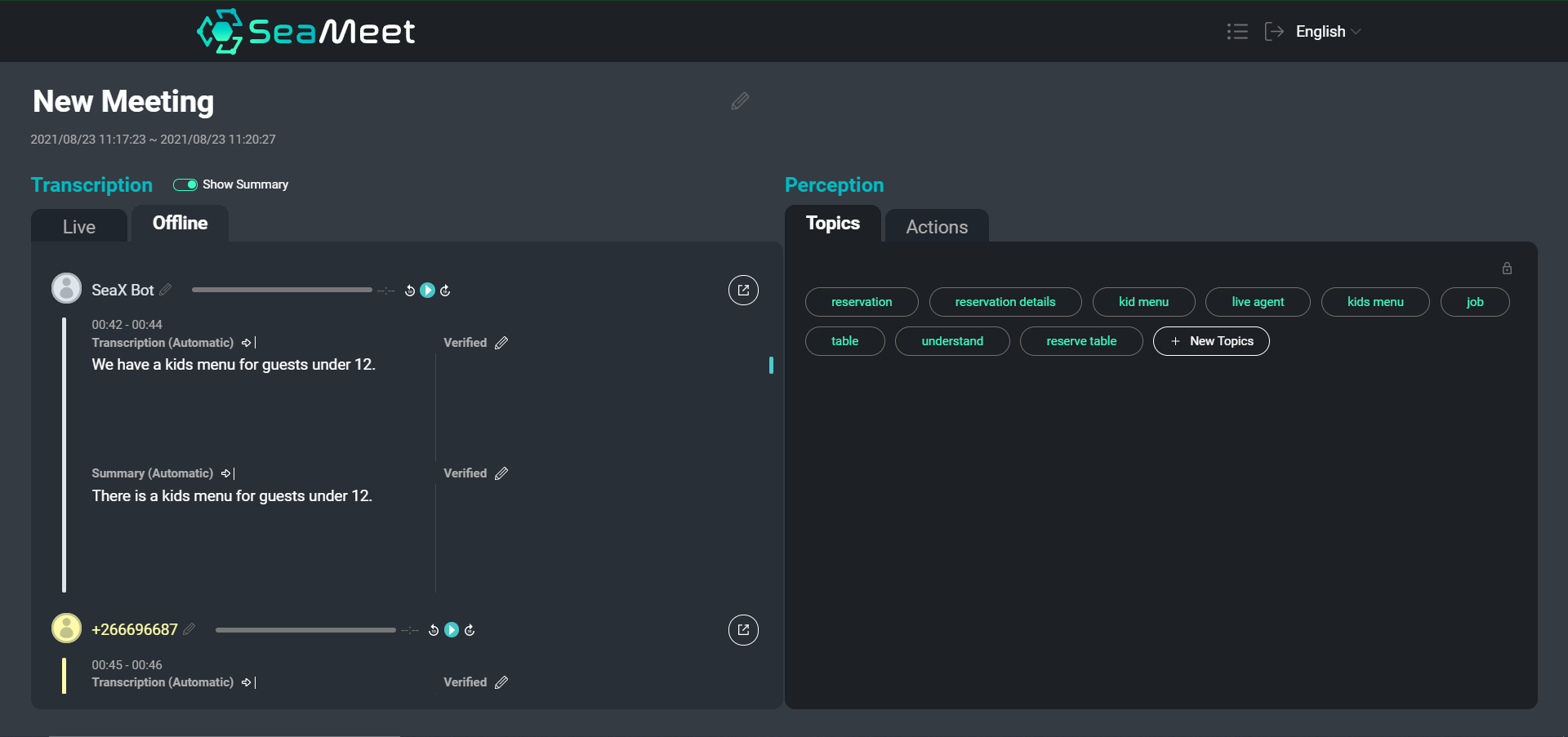
我们的 SeaMeet 界面概览,左侧是用户的发言及其简短摘要
虽然浏览文本转录稿肯定比翻阅数小时的录音要容易,但对于特别长的会议来说,要找到特定的内容或了解整个对话的概况仍然很耗时。 我们选择在完整转录稿之外提供两种类型的摘要。
个人发言级别的摘要提供了更简洁、更易于阅读的片段。 此外,简短的摘要通过删除语义上空洞的片段并执行照应和共指消解来帮助规范化文本。 然后,我们可以将摘要后的片段输入下游应用程序(例如主题抽象)以改善最终结果。
除了简短的摘要,我们还选择提供一个单一的长摘要,旨在创建整个会议的非常笼统的概述。 该摘要的功能类似于会议的摘要,仅涵盖主要的谈话要点和结论。
以下是简短摘要的示例,我们将原始转录稿中的每个片段都通过摘要器进行了处理:
金:“旭晨被静音了,因为通话中有很多人。”
旭晨:“只是信号不好。”
萨姆:“我发送了一个单独的文件,其中包含周二到 30 天的语音数据。”
金:“会有一些边缘情况这个方法行不通。”
旭晨:“训练一个已经训练好的模型的缺点是你必须为它编写规则。”
金:“分类并没有做那种能给他们一个行动的分类。”
旭晨:“这里的诀窍是他们希望助动词存在,但他们也希望有一些人名。”
旭晨:“如果一个句子中有很多单词,它们中没有多少能帮助行动。”这个例子显示了整个会议被总结成一个段落:
“旭晨被静音了,因为通话中有很多人。萨姆发送了一个单独的文件,其中包含周二到 30 天的语音数据。旭晨发现了一些说话人是受让人的边缘情况。”短摘要和长摘要组件的核心都是一个基于 Transformer 的摘要模型。 我们针对抽象式摘要在对话数据集上对模型进行了微调。 数据包含各种长度的文本摘录,每个摘录都配有手写的摘要。 对于多语言摘要,我们使用相同的范例,但在数据集的翻译版本上使用经过微调的多语言基础模型。 在 SeaMeet 界面中,用户还可以选择验证机器生成的摘要,或提供自己的摘要。 然后,我们可以收集这些用户输入的摘要,并将它们添加回我们的训练集,以不断改进我们的模型。
主题抽象
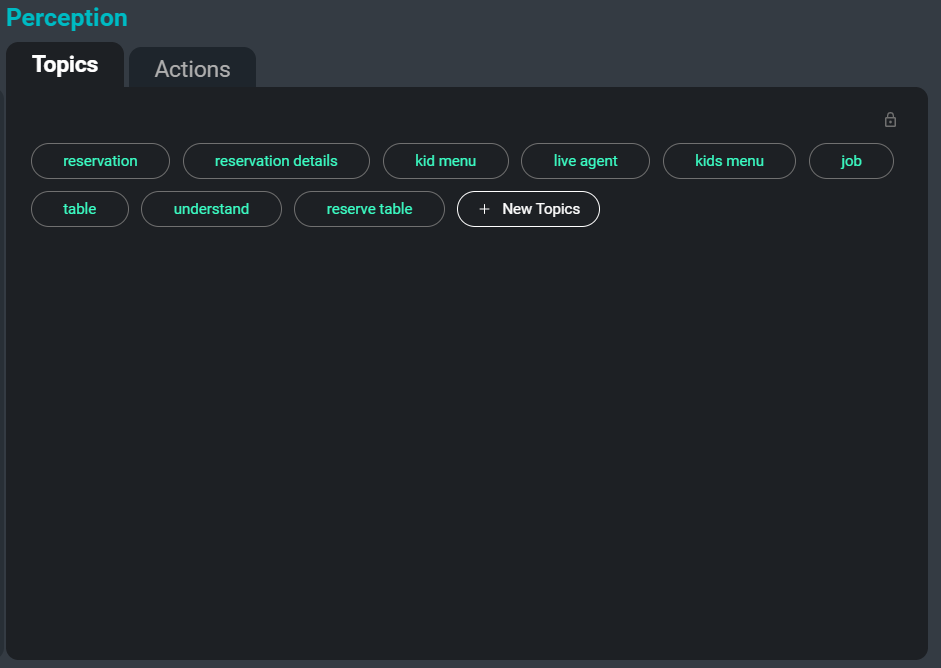
SeaMeet 界面,重点关注右侧的“主题”选项卡
处理大量转录稿时的另一个问题是组织、分类和搜索它们。 通过自动从转录稿中抽象出关键词和主题,我们可以为用户提供一种轻松的方式来追踪某些会议,甚至是正在讨论相关主题的会议的特定部分。 此外,这些主题还可以作为另一种方法来总结转录稿中最重要和最令人难忘的信息。
以下是从示例转录稿中提取的关键词示例:
助动词
说话人
语音数据
单独的文件
更新的版本
人名
训练好的模型
编写规则主题提取任务结合了抽象式和抽取式方法。 抽象式是指一种文本分类方法,其中每个输入都被分类到训练期间看到的一组标签中。 对于这种方法,我们使用了一个在与相关主题列表配对的文档上训练的神经架构。 抽取式是指一种关键词搜索方法,其中从提供的文本中提取相关的关键词并作为主题返回。 对于这种方法,我们结合使用余弦相似度和 TF-IDF 等相似性度量以及词共现信息来提取最相关的关键词和短语。
抽象式和抽取式技术各有优缺点,但通过将它们结合使用,我们可以利用各自的优势。 抽象模型非常擅长收集不同但相关的细节,并找到一个稍微更通用的主题来适应所有这些细节。 然而,它永远无法预测它在训练期间没有见过的主题,而且不可能对对话中可能出现的每一个可以想象的主题进行训练! 另一方面,抽取式模型可以直接从文本中提取关键词和主题,这意味着它与领域无关,并且可以提取它以前从未见过的主题。 这种方法的缺点是,有时主题过于相似或过于具体。 通过同时使用这两种方法,我们在通用性和领域特异性之间找到了一个愉快的中间地带。
行动项提取
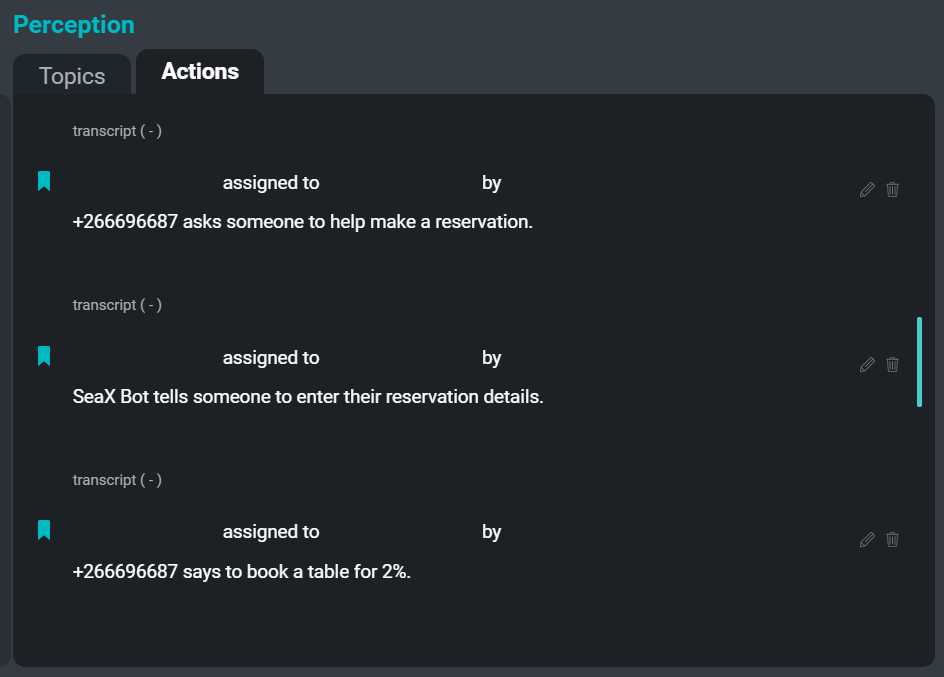
SeaMeet 用户界面,重点关注右侧的“行动”选项卡
我们着手为用户减轻的最后一个痛点是记录行动项的任务。 记录行动项是在会议期间分配给员工的一项非常常见的任务。 写下“谁告诉谁在什么时候做什么”可能非常耗时,并可能导致作者分心,无法完全参与会议。 通过自动化这个过程,我们希望减轻用户的部分责任,以便每个人都能全身心地投入到会议中。
以下是从示例转录稿中可以提取的一些行动项的示例:
建议:“萨姆说团队应该有一些更新的版本。”
声明:“金说肯定会有一些边缘情况这个方法行不通。”
命令:“旭晨说有人必须为它编写规则。”
愿望:“旭晨说团队希望助动词存在,但也希望有一些人名。”行动提取器系统的目的是从会议转录稿中提取的行动项创建简短的抽象摘要。 在会议转录稿上运行行动提取器的结果是一个命令、建议、意向声明和其他可操作片段的列表,可以作为会议参与者的待办事项或后续行动呈现。 将来,提取器还将捕获受让人和分配人的姓名以及与每个行动项相关的截止日期。
行动提取管道有两个主要组件:一个分类器和一个摘要器。 首先,每个片段都被传递到一个多类分类器中,并接收以下标签之一:
- 问题
- 命令
- 建议
- 愿望
- 声明
- 不可操作
如果片段收到除“不可操作”之外的任何标签,它将与转录稿中的前两个片段一起发送到摘要组件,这为摘要提供了更多上下文。 摘要步骤与独立的摘要组件基本相同,但是,该模型是在专门为以所需输出格式总结行动项而构建的定制数据集上进行训练的。
SeaMeet 有了大脑
这是朝着创造我们自己独特产品迈出的一大步:训练摘要以及主题和行动提取模型,以进一步推动我们的产品,并设计一个漂亮的界面,将所有东西都融入一个令人惊叹的包中。 这就是迄今为止的故事,Seasalt.ai 为快速发展的市场带来最佳业务解决方案并向世界交付 SeaMeet:现代会议的未来的旅程的开始。