





Sa buong serye ng blog na ito, sundan ang paglalakbay ng Seasalt.ai sa paglikha ng isang mahusay na karanasan sa Modern Meetings, simula sa mga hamak na simula nito, hanggang sa pag-optimize ng aming serbisyo sa iba’t ibang hardware at modelo, hanggang sa pagsasama ng mga makabagong sistema ng NLP at sa wakas ay nagtatapos sa buong pagsasakatuparan ng SeaMeet, ang aming mga solusyon sa modernong pagpupulong na nakikipagtulungan.
Higit pa sa Transkripsyon
Ang lahat ng mga nakaraang hadlang na aming hinarap ay nagturo sa amin ng isang mahalagang aral: na magagawa namin ang lahat ng ito nang mas mahusay sa aming sarili. Kaya’t ang mga tauhan dito sa Seasalt.ai ay nagsimulang sanayin ang aming sariling mga modelo ng acoustic at wika upang makipagkumpitensya sa mga kakayahan ng conversational transcriber ng Azure. Nagpakita ang Microsoft ng isang kamangha-manghang presentasyon sa MS Build 2019, na ipinapakita ang Speech Services ng Azure bilang isang napakahusay ngunit napakadaling ma-access na produkto. Matapos mamangha, napilitan kaming magtanong, saan tayo pupunta mula rito? Paano natin mapapalawak ang produktong ito na napakahalaga na? Ipinakita ng Modern Meetings ang matatag na potensyal ng speech to text, ngunit doon ito humihinto. Alam natin na maaaring makinig sa atin ang Azure, ngunit paano kung magagawa natin itong mag-isip para sa atin? Sa mga transkripsyon lamang, habang ang produkto ay kahanga-hanga, ang mga aplikasyon ay medyo limitado.
Sa pamamagitan ng pagsasama ng umiiral na teknolohiya ng speech-to-text sa mga system na maaaring makabuo ng mga pananaw mula sa mga transkripsyon, maaari kaming maghatid ng isang produkto na lumalampas sa mga inaasahan at inaasahan ang mga pangangailangan ng gumagamit. Nagpasya kaming isama ang tatlong mga sistema upang mapabuti ang pangkalahatang halaga ng aming mga transkripsyon sa SeaMeet: pagbubuod, pag-abstract ng paksa, at pagkuha ng item ng pagkilos. Ang bawat isa sa mga ito ay pinili upang maibsan ang mga partikular na punto ng sakit ng gumagamit.
Upang ipakita, ipapakita namin ang resulta ng pagpapatakbo ng mga sistema ng pagbubuod, mga paksa, at mga pagkilos sa sumusunod na maikling transcript:
Kim: "Salamat, Xuchen naka-mute ka dahil maraming tao sa tawag na ito. Pindutin ang Star 6 para i-unmute."
Xuchen: "OK akala ko masama lang ang reception."
Kim: "Oo."
Sam: "Nagpadala lang ako ng hiwalay na file na may data ng pagsasalita para sa Martes hanggang 30 araw. Dapat mayroon na kayong mga na-update na bersyon."
Kim: "Kaya tiyak na magkakaroon ng mga edge case kung saan hindi ito gagana. Nakakita na ako ng ilan tulad sa halimbawang ito. Kinukuha nito ang pandiwa doon at sinasabing ang nagsasalita ang assignee kapag sa totoo lang si Carol ang assignee doon. Ngunit pareho itong pattern sa isang bagay tulad ng pangalawa kung saan gusto mo talagang ako ang assignee dahil hindi nila itinalaga si Jason, itinalaga nila ang kanilang sarili na sabihin kay Jason."
Sam: "Nakuha ko."
Xuchen: "Kaya ang downside nito ay kailangan mong magsulat ng mga panuntunan para dito. Oo, ang upside ay isa na itong sinanay na modelo. Maaari mo itong sanayin pa ngunit hindi natin kailangang magtapon ng isang toneladang data dito."
Kim: "Bagaman hindi nito ginagawa ang pag-uuri na magbibigay sa atin ng Ito ba ay isang aksyon o ito ba ay iba pa?"
Xuchen: "Kaya, ang trick dito ay gusto natin na naroroon ang auxiliary verb, ngunit gusto rin natin ng ilang pangalan ng tao."
Sam: "Tama kung hindi man ay dahil."
Xuchen: "Oo, kung mayroong isang pangungusap na may, alam mo, maraming mga pagkakataon na may mga halatang salita. Gayunpaman, hindi marami sa kanila ang makakatulong sa mga aksyon."Pagbubuod
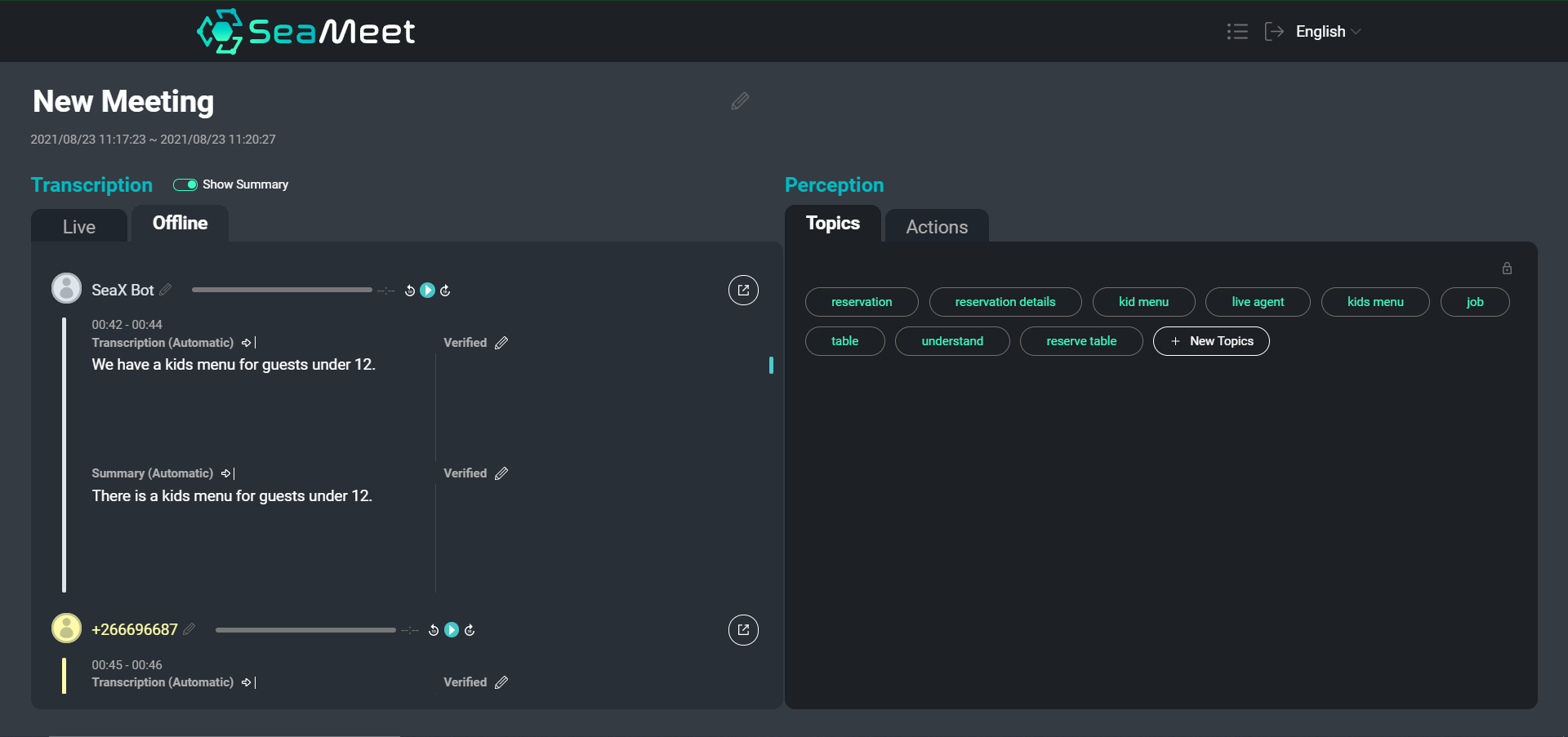
Isang pangkalahatang-ideya ng aming interface ng SeaMeet, na nagtatampok ng mga sinabi ng gumagamit kasama ang kanilang mga maikling buod sa kaliwa
Habang ang pag-navigate sa isang transkripsyon ng teksto ay tiyak na mas madali kaysa sa paghuhukay sa mga oras ng naitala na audio, para sa mga partikular na mahabang pagpupulong maaari pa ring maging matagal upang makahanap ng partikular na nilalaman o makakuha ng isang pangkalahatang-ideya ng pag-uusap sa kabuuan. Pinili naming magbigay ng dalawang uri ng mga buod bilang karagdagan sa buong transkripsyon.
Ang mga buod sa antas ng indibidwal na pagsasalita ay nagbibigay ng mas maigsi, madaling basahin na mga segment. Bilang karagdagan, ang mga maikling buod ay nakakatulong na i-normalize ang teksto sa pamamagitan ng pag-alis ng mga semantically empty na segment at pagsasagawa ng anaphora at co-reference resolution. Maaari naming pagkatapos ay i-feed ang mga summarized na segment sa mga downstream na application (tulad ng topic abstraction) upang mapabuti ang mga resulta sa dulo.
Bilang karagdagan sa mga maikling buod, pinili din naming magbigay ng isang solong mahabang buod na naglalayong lumikha ng isang napaka-pangkalahatang pangkalahatang-ideya ng buong pagpupulong. Ang buod na ito ay gumagana tulad ng isang abstract para sa pagpupulong, na sumasaklaw lamang sa mga pangunahing punto ng pakikipag-usap at mga konklusyon.
Ang sumusunod ay isang halimbawa ng mga maikling buod, kung saan ipinasa namin ang bawat segment sa orihinal na transcript sa pamamagitan ng summarizer:
Kim: "Naka-mute si Xuchen dahil maraming tao sa tawag."
Xuchen: "Masama lang ang reception."
Sam: "Nagpadala ako ng hiwalay na file na may data ng pagsasalita para sa Martes hanggang 30 araw."
Kim: "Magkakaroon ng mga edge case kung saan hindi ito gagana."
Xuchen: "Ang downside ng pagsasanay sa isang sinanay na modelo ay kailangan mong magsulat ng mga panuntunan para dito."
Kim: "Ang pag-uuri ay hindi gumagawa ng pag-uuri na magbibigay sa kanila ng isang aksyon."
Xuchen: "Ang trick dito ay gusto nila na naroroon ang auxiliary verb, ngunit gusto rin nila ng ilang pangalan ng tao."
Xuchen: "Kung mayroong isang pangungusap na may mga salita, hindi marami sa kanila ang makakatulong sa mga aksyon."At ipinapakita ng halimbawang ito ang buong pagpupulong na binuod sa isang solong talata:
"Naka-mute si Xuchen dahil maraming tao sa tawag. Nagpadala si Sam ng hiwalay na file na may data ng pagsasalita para sa Martes hanggang 30 araw. Nakahanap si Xuchen ng ilang mga edge case kung saan ang nagsasalita ang assignee."Sa core ng parehong maikli at mahabang mga bahagi ng pagbubuod ay isang modelo ng pagbubuod na batay sa transpormer. Pinipino namin ang modelo sa isang dataset ng diyalogo para sa abstractive summarization. Naglalaman ang data ng mga textual excerpt ng iba’t ibang haba na bawat isa ay ipinares sa isang sulat-kamay na buod. Para sa multilingual summarization, ginagamit namin ang parehong paradigma, ngunit gumagamit kami ng isang multilingual base model na pinino sa isang isinalin na bersyon ng dataset. Mula sa interface ng SeaMeet, mayroon ding pagpipilian ang gumagamit na i-verify ang isang buod na ginawa ng makina, o magbigay ng kanilang sarili. Maaari naming pagkatapos ay kolektahin ang mga buod na ito na inilagay ng gumagamit at idagdag ang mga ito pabalik sa aming training set upang patuloy na mapabuti ang aming mga modelo.
Pag-abstract ng Paksa
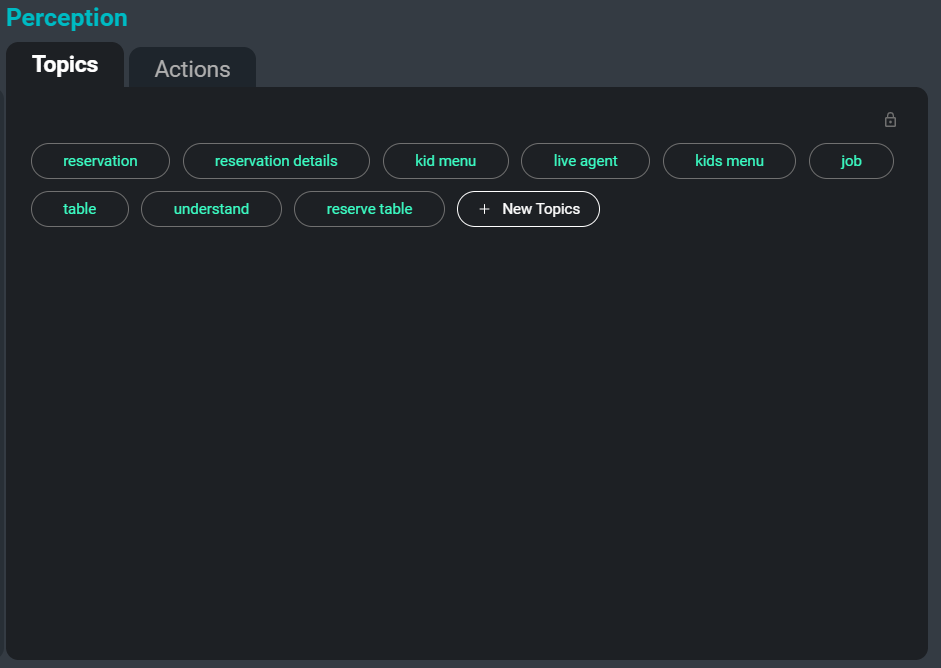
Ang interface ng SeaMeet, na nakatuon sa tab na ‘Mga Paksa’ sa kanang bahagi
Ang isa pang problema kapag nakikipag-usap sa malalaking koleksyon ng mga transkripsyon ay ang pag-oorganisa, pagkakategorya, at paghahanap sa kanila. Sa pamamagitan ng awtomatikong pag-abstract ng mga keyword at paksa mula sa transcript, maaari naming bigyan ang mga gumagamit ng isang madaling paraan upang masubaybayan ang ilang mga pagpupulong, o kahit na mga partikular na seksyon ng mga pagpupulong kung saan tinatalakay ang isang nauugnay na paksa. Bilang karagdagan, ang mga paksang ito ay nagsisilbing isa pang paraan ng pagbubuod ng pinakamahalaga at di malilimutang impormasyon sa isang transcript.
Narito ang isang halimbawa ng mga keyword na kukunin mula sa sample transcript:
auxiliary verb
speaker
speech data
hiwalay na file
na-update na mga bersyon
pangalan ng tao
sinanay na modelo
sumulat ng mga panuntunanAng gawain sa pagkuha ng paksa ay gumagamit ng isang kumbinasyon ng mga abstractive at extractive na diskarte. Ang abstractive ay tumutukoy sa isang diskarte sa pag-uuri ng teksto, kung saan ang bawat input ay inuri sa isang hanay ng mga label na nakita sa panahon ng pagsasanay. Para sa pamamaraang ito gumamit kami ng isang neural architecture na sinanay sa mga dokumento na ipinares sa isang listahan ng mga nauugnay na paksa. Ang extractive ay tumutukoy sa isang diskarte sa paghahanap ng keyphrase kung saan ang mga nauugnay na keyphrase ay kinukuha mula sa ibinigay na teksto at ibinabalik bilang mga paksa. Para sa diskarteng ito, gumagamit kami ng isang kumbinasyon ng mga sukatan ng pagkakatulad tulad ng cosine similarity at TF-IDF bilang karagdagan sa impormasyon ng co-occurrence ng salita upang makuha ang pinaka-kaugnay na mga keyword at parirala.
Ang parehong abstractive at extractive na mga diskarte ay may mga kalamangan at kahinaan, ngunit sa pamamagitan ng paggamit ng mga ito nang magkasama maaari nating samantalahin ang mga lakas ng bawat isa. Ang abstractive na modelo ay mahusay sa pagkolekta ng mga natatanging, ngunit nauugnay na mga detalye at paghahanap ng isang bahagyang mas pangkalahatang paksa na nababagay sa kanilang lahat. Gayunpaman, hindi nito mahuhulaan ang isang paksa na hindi pa nito nakikita sa panahon ng pagsasanay, at imposibleng sanayin sa bawat maiisip na paksa na maaaring lumabas sa isang pag-uusap! Ang mga extractive na modelo, sa kabilang banda, ay maaaring kumuha ng mga keyword at paksa nang direkta mula sa teksto, na nangangahulugang ito ay independiyente sa domain, at maaaring kumuha ng mga paksa na hindi pa nito nakikita dati. Ang downside sa diskarteng ito ay kung minsan ang mga paksa ay masyadong magkatulad o masyadong tiyak. Sa pamamagitan ng paggamit ng pareho, nakahanap kami ng isang masayang medium sa pagitan ng pangkalahatan at partikular sa domain.
Pagkuha ng Item ng Pagkilos
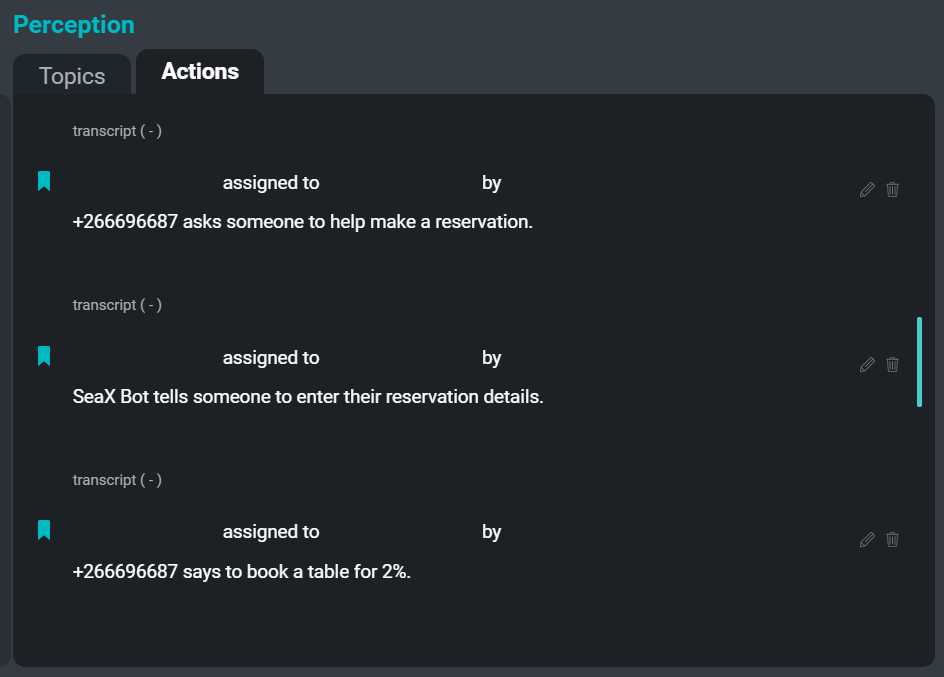
Ang UI ng SeaMeet, na nakatuon sa tab na ‘Mga Aksyon’ sa kanang bahagi
Ang huling punto ng sakit na itinakda naming alisin para sa mga gumagamit ay ang gawain ng pagtatala ng mga item ng pagkilos. Ang pagtatala ng mga item ng pagkilos ay isang napaka-pangkaraniwang gawain na itinalaga sa isang empleyado na gawin sa panahon ng isang pagpupulong. Ang pagsusulat ng ‘sino ang nagsabi sa kanino na gawin kung ano kailan’ ay maaaring maging napakatagal, at maaaring maging sanhi ng pagkagambala ng manunulat at hindi makilahok nang buo sa pagpupulong. Sa pamamagitan ng pag-automate ng prosesong ito, inaasahan naming maibsan ang ilan sa responsibilidad na iyon mula sa gumagamit upang ang lahat ay makapaglaan ng kanilang buong pansin sa pakikilahok sa pagpupulong.
Ang sumusunod ay isang halimbawa ng ilang mga item ng pagkilos na maaaring makuha mula sa halimbawang transcript:
suhestiyon: "Sabi ni Sam dapat magkaroon ng ilang na-update na bersyon ang team."
pahayag: "Sabi ni Kim tiyak na magkakaroon ng mga edge case kung saan hindi ito gagana."
imperatibo: "Sabi ni Xuchen kailangang may magsulat ng mga panuntunan para dito."
hangarin: "Sabi ni Xuchen gusto ng team na naroroon ang auxiliary verb, ngunit gusto rin ng ilang pangalan ng tao."Ang layunin ng sistema ng Action Extractor ay lumikha ng mga maikling abstractive na buod ng mga item ng pagkilos na nakuha mula sa mga transkripsyon ng pagpupulong. Ang resulta ng pagpapatakbo ng Action Extractor sa isang transkripsyon ng pagpupulong ay isang listahan ng mga utos, mungkahi, pahayag ng layunin, at iba pang mga segment na maaaring gawin na maaaring iharap bilang mga dapat gawin o mga follow-up para sa mga kalahok sa pagpupulong. Sa hinaharap, kukunin din ng extractor ang mga pangalan ng mga assignee at assigner pati na rin ang mga takdang petsa na nakatali sa bawat item ng pagkilos.
Ang pipeline ng pagkuha ng aksyon ay may dalawang pangunahing bahagi: isang classifier at isang summarizer. Una, ang bawat segment ay ipinapasa sa isang multi-class classifier at tumatanggap ng isa sa mga sumusunod na label:
- Tanong
- Imperatibo
- Suhestiyon
- Hangarin
- Pahayag
- Hindi maaaring gawin
Kung ang segment ay tumatanggap ng anumang label maliban sa ‘hindi maaaring gawin’, ipinapadala ito sa bahagi ng pagbubuod kasama ang dalawang nakaraang mga segment sa transcript, na nagbibigay ng higit pang konteksto para sa pagbubuod. Ang hakbang sa pagbubuod ay mahalagang pareho sa stand-alone na bahagi ng pagbubuod, gayunpaman ang modelo ay sinanay sa isang pasadyang dataset na partikular na binuo para sa pagbubuod ng mga item ng pagkilos na may nais na format ng output.
Nagkaroon ng Utak ang SeaMeet
Ito ay isang malaking hakbang tungo sa paglikha ng aming sariling natatanging produkto: pagsasanay sa pagbubuod kasama ang mga modelo ng pagkuha ng paksa at pagkilos upang higit pang dalhin ang aming produkto, at pagdidisenyo ng isang magandang interface upang pagsamahin ang lahat sa isang nakamamanghang pakete. Ito ang kwento sa ngayon, ang simula ng paglalakbay ng Seasalt.ai upang dalhin ang pinakamahusay na mga solusyon sa negosyo sa isang mabilis na umuunlad na merkado at ihatid sa mundo, ang SeaMeet: Ang Kinabukasan ng mga Modernong Pagpupulong.


