





Ao longo desta série de blogues, acompanhe a jornada da Seasalt.ai para criar uma Experiência de Reuniões Modernas bem-sucedida, desde os seus primórdios humildes, à otimização do nosso serviço em diferentes hardwares e modelos, à integração de sistemas de PNL de última geração e, finalmente, terminando na plena realização do SeaMeet, as nossas soluções colaborativas de reuniões modernas.
Para Além da Transcrição
Todas as obstruções anteriores que enfrentámos ensinaram-nos uma lição importante: que podíamos fazer tudo isto melhor sozinhos. Assim, a equipa da Seasalt.ai começou a treinar os seus próprios modelos acústicos e de linguagem para rivalizar com as capacidades do transcritor de conversas do Azure. A Microsoft fez uma apresentação fantástica na MS Build 2019, mostrando os Serviços de Fala do Azure como um produto altamente capaz e, no entanto, muito acessível. Depois de ficarmos maravilhados, somos forçados a fazer a pergunta: para onde vamos a partir daqui? Como podemos expandir este produto já instrumental? As Reuniões Modernas demonstraram um potencial robusto de conversão de voz em texto, mas é aí que para. Sabemos que o Azure nos pode ouvir, mas e se o pudéssemos fazer pensar por nós? Com apenas transcrições, embora o produto seja impressionante, as aplicações são um tanto limitadas.
Ao integrar a tecnologia de conversão de voz em texto existente com sistemas que podem produzir informações a partir das transcrições, podemos fornecer um produto que excede as expectativas e antecipa as necessidades do utilizador. Decidimos incorporar três sistemas para melhorar o valor geral das nossas transcrições do SeaMeet: resumo, abstração de tópicos e extração de itens de ação. Cada um destes foi escolhido para aliviar pontos de dor específicos do utilizador.
Para demonstrar, mostraremos o resultado da execução dos sistemas de resumos, tópicos e ações na seguinte transcrição curta:
Kim: "Obrigado, Xuchen, está sem som porque há muitas pessoas nesta chamada. Pressione a tecla de asterisco 6 para reativar o som."
Xuchen: "OK, pensei que era apenas má receção."
Kim: "Sim."
Sam: "Acabei de enviar um ficheiro separado com dados de voz para as terças-feiras até 30 dias. Vocês devem ter algumas versões atualizadas."
Kim: "Portanto, haverá definitivamente casos extremos em que isto não funciona. Já encontrei alguns como neste exemplo. Ele tira o verbo e diz que o orador é o cessionário quando, na verdade, é mais a Carol que é a cessionária. Mas é o mesmo padrão de algo como o segundo, em que se quer mesmo que eu seja o cessionário porque eles não estão a atribuir o Jason, estão a atribuir-se a si próprios para dizer ao Jason."
Sam: "Entendido."
Xuchen: "Portanto, a desvantagem disto é que temos de escrever regras para isso. Sim, a vantagem é que já é um modelo treinado. Podemos treiná-lo ainda mais, mas não temos de lhe fornecer uma tonelada de dados."
Kim: "Embora não faça a classificação que nos daria se isto é uma ação ou se é outra coisa?"
Xuchen: "Portanto, o truque aqui é que queremos que o verbo auxiliar esteja presente, mas também queremos alguns nomes de pessoas."
Sam: "Certo, caso contrário, talvez porque."
Xuchen: "Sim, se houver uma frase com, sabe, muitas instâncias com palavras óbvias. No entanto, poucas delas ajudariam nas ações."Resumo
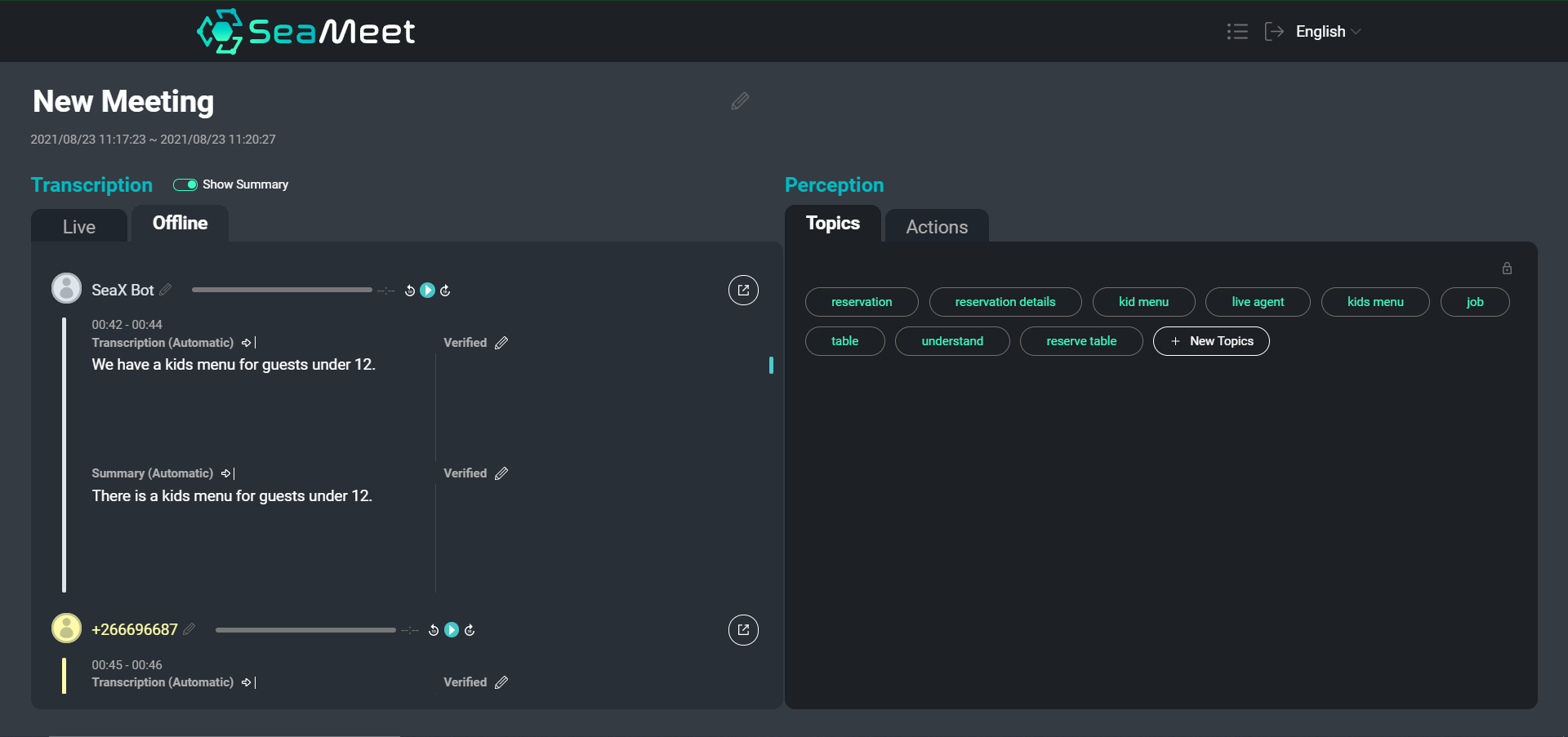
Uma visão geral da nossa interface SeaMeet, com as declarações dos utilizadores e os seus resumos curtos à esquerda
Embora navegar numa transcrição de texto seja certamente mais fácil do que vasculhar horas de áudio gravado, para reuniões particularmente longas ainda pode ser demorado encontrar conteúdo específico ou obter uma visão geral da conversa como um todo. Optámos por fornecer dois tipos de resumos para além da transcrição completa.
Os resumos ao nível da declaração individual fornecem segmentos mais concisos e fáceis de ler. Além disso, os resumos curtos ajudam a normalizar o texto, removendo segmentos semanticamente vazios e realizando a resolução de anáforas e correferências. Podemos então alimentar os segmentos resumidos em aplicações a jusante (como a abstração de tópicos) para melhorar os resultados finais.
Para além dos resumos curtos, também optámos por fornecer um único resumo longo que visa criar uma visão geral muito geral de toda a reunião. Este resumo funciona como um resumo da reunião, cobrindo apenas os principais pontos de discussão e conclusões.
O seguinte é um exemplo dos resumos curtos, onde alimentámos cada segmento da transcrição original através do resumidor:
Kim: "O Xuchen está sem som porque há muitas pessoas na chamada."
Xuchen: "É apenas má receção."
Sam: "Enviei um ficheiro separado com dados de voz para as terças-feiras até 30 dias."
Kim: "Haverá casos extremos em que isto não funciona."
Xuchen: "A desvantagem de treinar um modelo já treinado é que temos de escrever regras para ele."
Kim: "A classificação não faz a classificação que lhes daria uma ação."
Xuchen: "O truque aqui é que eles querem que o verbo auxiliar esteja presente, mas também querem alguns nomes de pessoas."
Xuchen: "Se houver uma frase com palavras, poucas delas ajudariam nas ações."E este exemplo mostra toda a reunião resumida num único parágrafo:
"O Xuchen está sem som porque há muitas pessoas na chamada. O Sam enviou um ficheiro separado com dados de voz para as terças-feiras até 30 dias. O Xuchen encontrou alguns casos extremos em que o orador é o cessionário."No centro de ambos os componentes de resumo, o curto e o longo, está um modelo de resumo baseado em transformadores. Afinamos o modelo num conjunto de dados de diálogo para resumo abstrativo. Os dados contêm excertos textuais de vários comprimentos, cada um emparelhado com um resumo escrito à mão. Para o resumo multilingue, utilizamos o mesmo paradigma, mas utilizamos um modelo de base multilingue afinado numa versão traduzida do conjunto de dados. A partir da interface do SeaMeet, o utilizador também tem a opção de verificar um resumo produzido por máquina ou de fornecer o seu próprio. Podemos então recolher estes resumos introduzidos pelo utilizador e adicioná-los de volta ao nosso conjunto de treino para melhorar continuamente os nossos modelos.
Abstração de Tópicos
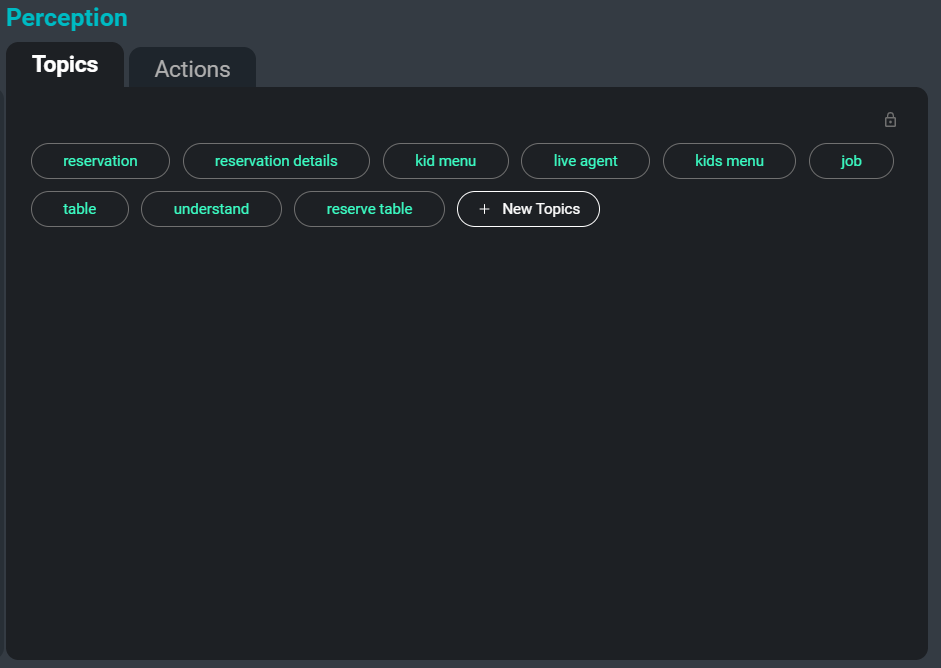
A interface do SeaMeet, focada no separador ‘Tópicos’ do lado direito
Outro problema ao lidar com grandes coleções de transcrições é organizá-las, categorizá-las e pesquisá-las. Ao abstrair automaticamente palavras-chave e tópicos da transcrição, podemos fornecer aos utilizadores uma forma fácil de localizar certas reuniões, ou mesmo secções específicas de reuniões onde um tópico relevante está a ser discutido. Além disso, estes tópicos servem como outro método de resumir as informações mais importantes e memoráveis numa transcrição.
Aqui está um exemplo de palavras-chave que seriam extraídas da transcrição de amostra:
verbo auxiliar
orador
dados de voz
ficheiro separado
versões atualizadas
nomes de pessoas
modelo treinado
escrever regrasA tarefa de extração de tópicos utiliza uma combinação de abordagens abstrativas e extrativas. Abstrativo refere-se a uma abordagem de classificação de texto, onde cada entrada é classificada num conjunto de rótulos vistos durante o treino. Para este método, utilizámos uma arquitetura neural treinada em documentos emparelhados com uma lista de tópicos relevantes. Extrativo refere-se a uma abordagem de pesquisa de frases-chave onde frases-chave relevantes são extraídas do texto fornecido e devolvidas como tópicos. Para esta abordagem, utilizamos uma combinação de métricas de similaridade, como a similaridade de cosseno e TF-IDF, para além de informações de coocorrência de palavras para extrair as palavras-chave e frases mais relevantes.
Tanto as técnicas abstrativas como as extrativas têm prós e contras, mas ao usá-las em conjunto podemos tirar partido dos pontos fortes de cada uma. O modelo abstrativo é ótimo a recolher detalhes distintos, mas relacionados, e a encontrar um tópico ligeiramente mais genérico que se adeque a todos eles. No entanto, nunca consegue prever um tópico que não tenha visto durante o treino, e é impossível treinar em todos os tópicos concebíveis que possam surgir numa conversa! Os modelos extrativos, por outro lado, podem extrair palavras-chave e tópicos diretamente do texto, o que significa que são independentes do domínio e podem extrair tópicos que nunca viram antes. A desvantagem desta abordagem é que, por vezes, os tópicos são demasiado semelhantes ou demasiado específicos. Ao utilizar ambos, encontrámos um meio-termo feliz entre o generalizável e o específico do domínio.
Extração de Itens de Ação
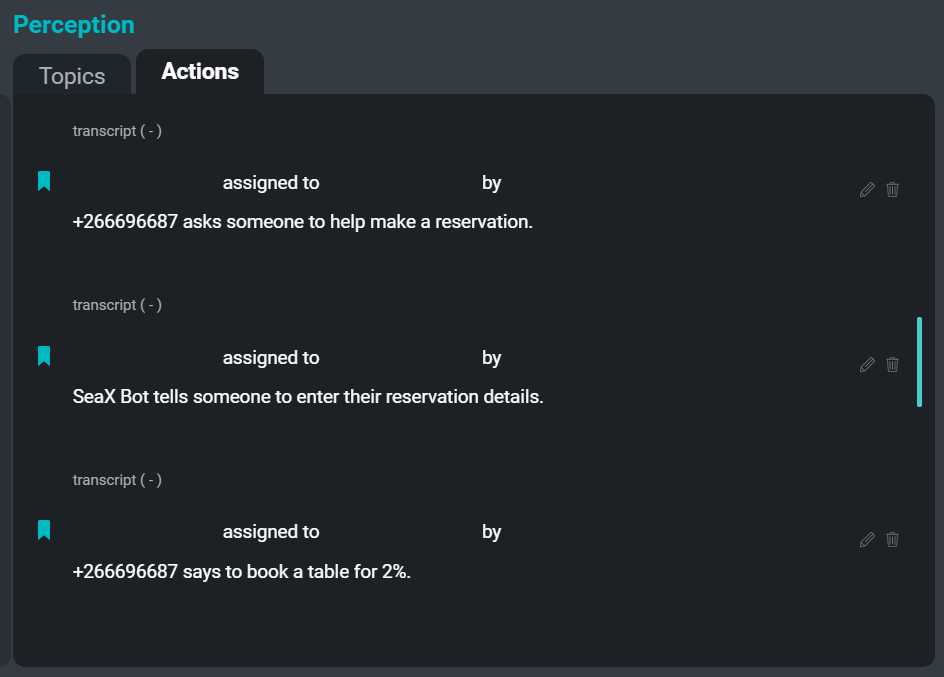
A IU do SeaMeet, focada no separador ‘Ações’ do lado direito
O último ponto de dor que nos propusemos a aliviar para os utilizadores é a tarefa de registar itens de ação. Registar itens de ação é uma tarefa muito comum que é atribuída a um funcionário para fazer durante uma reunião. Escrever ‘quem disse a quem para fazer o quê e quando’ pode ser extremamente demorado e pode fazer com que o escritor se distraia e não consiga participar plenamente na reunião. Ao automatizar este processo, esperamos aliviar alguma dessa responsabilidade do utilizador para que todos possam dedicar toda a sua atenção à participação na reunião.
O seguinte é um exemplo de alguns itens de ação que poderiam ser extraídos da transcrição de exemplo:
sugestão: "O Sam diz que a equipa deve ter algumas versões atualizadas."
declaração: "A Kim diz que haverá definitivamente casos extremos em que isto não funciona."
imperativo: "O Xuchen diz que alguém tem de escrever regras para isso."
desejo: "O Xuchen diz que a equipa quer que o verbo auxiliar esteja presente, mas também quer alguns nomes de pessoas."O objetivo do sistema Extrator de Ações é criar resumos abstrativos curtos de itens de ação extraídos de transcrições de reuniões. O resultado da execução do Extrator de Ações sobre uma transcrição de uma reunião é uma lista de comandos, sugestões, declarações de intenção e outros segmentos acionáveis que podem ser apresentados como tarefas ou acompanhamentos para os participantes da reunião. No futuro, o extrator também capturará os nomes dos cessionários e cedentes, bem como as datas de vencimento associadas a cada item de ação.
O pipeline de extração de ações tem dois componentes principais: um classificador e um resumidor. Primeiro, cada segmento é passado para um classificador de várias classes e recebe um dos seguintes rótulos:
- Pergunta
- Imperativo
- Sugestão
- Desejo
- Declaração
- Não acionável
Se o segmento receber qualquer rótulo que não seja ‘não acionável’, ele é enviado para o componente de resumo juntamente com os dois segmentos anteriores na transcrição, que fornecem mais contexto para o resumo. O passo de resumo é essencialmente o mesmo que o componente de resumo autónomo, no entanto, o modelo é treinado num conjunto de dados personalizado construído especificamente para resumir itens de ação com um formato de saída desejado.
O SeaMeet Ganha um Cérebro
Este foi um grande passo para a criação do nosso próprio produto único: treinar modelos de resumo e de extração de tópicos e ações para levar o nosso produto ainda mais longe, e projetar uma interface bonita para unir tudo num pacote deslumbrante. Esta é a história até agora, o início da jornada da Seasalt.ai para trazer as melhores soluções de negócios para um mercado em rápida evolução e entregar ao mundo, o SeaMeet: O Futuro das Reuniões Modernas.


