





На протяжении всей этой серии блогов следите за путешествием Seasalt.ai по созданию всестороннего опыта современных встреч, начиная с его скромных начинаний, до оптимизации нашего сервиса на различном оборудовании и моделях, до интеграции самых современных систем НЛП и, наконец, до полной реализации SeaMeet, наших совместных современных решений для встреч.
За пределами транскрипции
Все предыдущие препятствия, с которыми мы столкнулись, преподали нам важный урок: мы могли бы сделать все это лучше сами. Поэтому команда Seasalt.ai приступила к обучению наших собственных акустических и языковых моделей, чтобы конкурировать с возможностями разговорного транскрибатора Azure. Microsoft провела потрясающую презентацию на MS Build 2019, продемонстрировав речевые службы Azure как высокопроизводительный, но в то же время очень доступный продукт. После того, как мы были поражены, мы вынуждены задать вопрос: куда нам двигаться дальше? Как мы можем расширить этот уже имеющийся инструментальный продукт? Современные встречи продемонстрировали надежный потенциал преобразования речи в текст, но на этом все и заканчивается. Мы знаем, что Azure может нас слушать, но что, если мы заставим его думать за нас? При наличии только транскрипций, хотя продукт и впечатляет, его применение несколько ограничено.
Интегрируя существующую технологию преобразования речи в текст с системами, которые могут извлекать информацию из транскрипций, мы можем предоставить продукт, который превосходит ожидания и предвосхищает потребности пользователей. Мы решили включить три системы для повышения общей ценности наших транскрипций SeaMeet: резюмирование, абстрагирование тем и извлечение элементов действий. Каждая из них была выбрана для облегчения конкретных проблем пользователей.
Для демонстрации мы покажем результат работы систем резюмирования, тем и действий на следующем коротком отрывке:
Ким: «Спасибо, Сюйчэнь, у вас отключен звук, потому что на этом звонке много людей. Нажмите звездочку 6, чтобы включить звук».
Сюйчэнь: «Хорошо, я думал, это просто плохой прием».
Ким: «Да».
Сэм: «Я только что отправил отдельный файл с речевыми данными на вторники до 30 дней. У вас, ребята, должны быть обновленные версии».
Ким: «Так что определенно будут крайние случаи, когда это не сработает. Я уже нашел пару, как в этом примере. Он как бы вынимает глагол и говорит, что говорящий является исполнителем, хотя на самом деле исполнителем является Кэрол. Но это тот же шаблон, что и во втором случае, когда вы действительно хотите, чтобы я был исполнителем, потому что они не назначают Джейсона, они назначают себя, чтобы сказать Джейсону».
Сэм: «Понял».
Сюйчэнь: «Так что недостатком этого является то, что вам нужно писать для этого правила. Да, преимуществом является то, что это уже обученная модель. Вы можете обучать ее дальше, но нам не нужно вкладывать в это массу данных».
Ким: «Хотя он не выполняет классификацию, которая дала бы нам информацию о том, является ли это действием или чем-то другим?»
Сюйчэнь: «Итак, хитрость здесь в том, что мы хотим, чтобы вспомогательный глагол присутствовал, но мы также хотим, чтобы были и имена людей».
Сэм: «Правильно, иначе может быть, потому что».
Сюйчэнь: «Да, если есть предложение с, знаете ли, множеством случаев с очевидными словами. Однако не многие из них помогут в действиях».Резюмирование
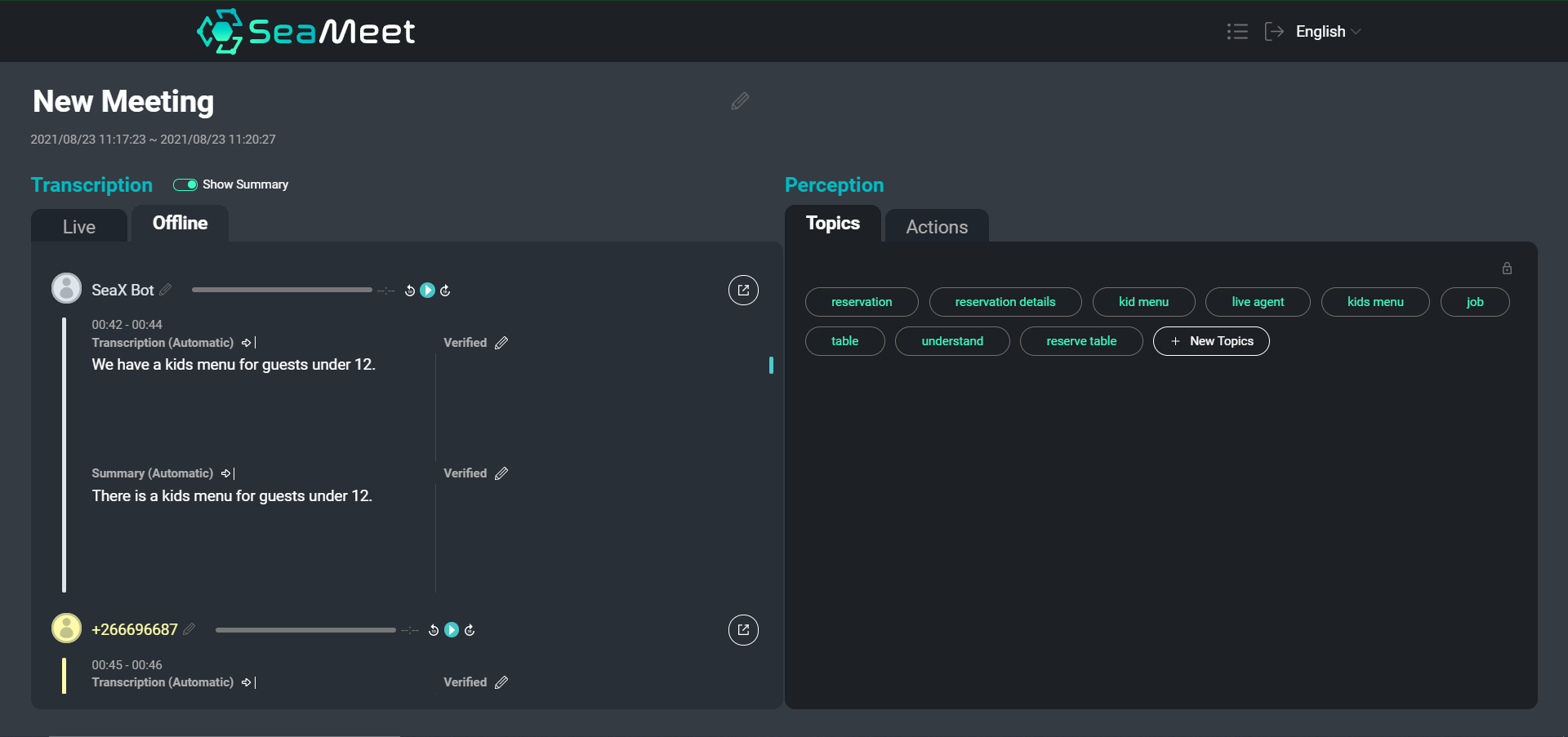
Обзор нашего интерфейса SeaMeet, показывающий высказывания пользователей с их краткими резюме слева
Хотя навигация по текстовой транскрипции, безусловно, проще, чем копаться в часах записанного аудио, для особенно длинных встреч все же может потребоваться много времени, чтобы найти определенный контент или получить общее представление о разговоре в целом. Мы решили предоставить два типа резюме в дополнение к полной транскрипции.
Резюме на уровне отдельных высказываний предоставляют более краткие и легко читаемые сегменты. Кроме того, краткие резюме помогают нормализовать текст, удаляя семантически пустые сегменты и выполняя разрешение анафор и кореференций. Затем мы можем передать обобщенные сегменты в последующие приложения (например, для абстрагирования тем), чтобы улучшить конечные результаты.
В дополнение к кратким резюме мы также решили предоставить одно длинное резюме, целью которого является создание очень общего обзора всей встречи. Это резюме функционирует как аннотация к встрече, охватывая только основные моменты обсуждения и выводы.
Ниже приведен пример кратких резюме, где мы пропустили каждый сегмент исходной транскрипции через суммаризатор:
Ким: «У Сюйчэня отключен звук, потому что на звонке много людей».
Сюйчэнь: «Это просто плохой прием».
Сэм: «Я отправил отдельный файл с речевыми данными на вторники до 30 дней».
Ким: «Будут крайние случаи, когда это не сработает».
Сюйчэнь: «Недостатком обучения уже обученной модели является то, что для нее нужно писать правила».
Ким: «Классификация не выполняет классификацию, которая дала бы им действие».
Сюйчэнь: «Хитрость здесь в том, что они хотят, чтобы вспомогательный глагол присутствовал, но они также хотят, чтобы были и имена людей».
Сюйчэнь: «Если есть предложение со словами, не многие из них помогут в действиях».И этот пример показывает всю встречу, обобщенную в одном абзаце:
«У Сюйчэня отключен звук, потому что на звонке много людей. Сэм отправил отдельный файл с речевыми данными на вторники до 30 дней. Сюйчэнь нашел несколько крайних случаев, когда говорящий является исполнителем».В основе как коротких, так и длинных компонентов резюмирования лежит модель резюмирования на основе трансформера. Мы дообучаем модель на диалоговом наборе данных для абстрактного резюмирования. Данные содержат текстовые выдержки различной длины, каждая из которых сопряжена с рукописным резюме. Для многоязычного резюмирования мы используем ту же парадигму, но используем многоязычную базовую модель, дообученную на переведенной версии набора данных. Из интерфейса SeaMeet у пользователя также есть возможность проверить сгенерированное машиной резюме или предоставить свое собственное. Затем мы можем собрать эти введенные пользователем резюме и добавить их обратно в наш обучающий набор, чтобы постоянно улучшать наши модели.
Абстрагирование тем
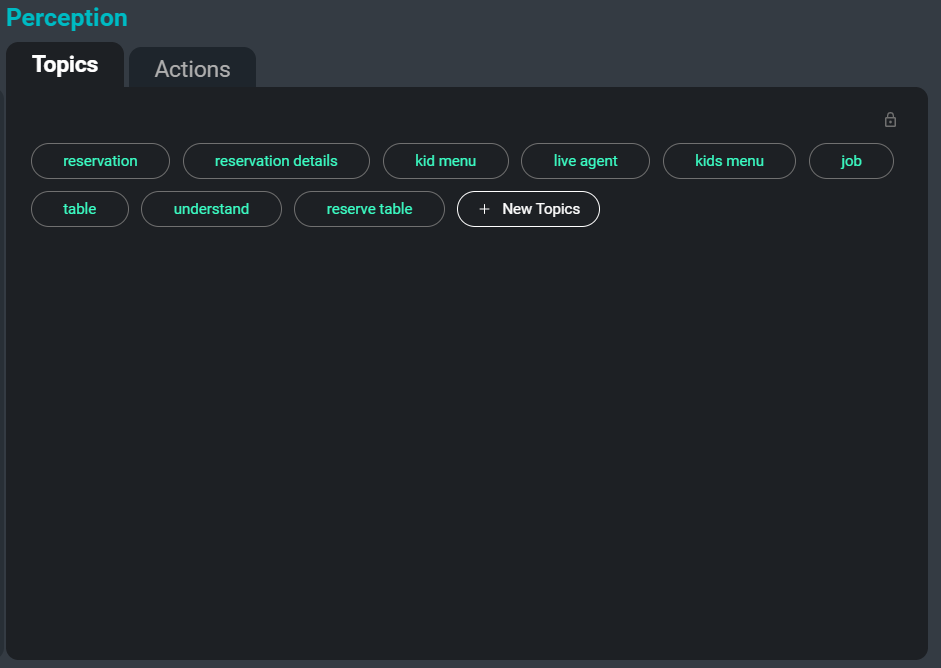
Интерфейс SeaMeet, сфокусированный на вкладке «Темы» с правой стороны
Еще одна проблема при работе с большими коллекциями транскрипций — это их организация, категоризация и поиск. Автоматически абстрагируя ключевые слова и темы из транскрипции, мы можем предоставить пользователям простой способ отслеживать определенные встречи или даже определенные разделы встреч, где обсуждается соответствующая тема. Кроме того, эти темы служат еще одним методом обобщения самой важной и запоминающейся информации в транскрипции.
Вот пример ключевых слов, которые будут извлечены из образца транскрипции:
вспомогательный глагол
говорящий
речевые данные
отдельный файл
обновленные версии
имена людей
обученная модель
писать правилаЗадача извлечения тем использует комбинацию абстрактных и экстрактивных подходов. Абстрактный относится к подходу к классификации текста, где каждый ввод классифицируется в набор меток, увиденных во время обучения. Для этого метода мы использовали нейронную архитектуру, обученную на документах, сопряженных со списком релевантных тем. Экстрактивный относится к подходу поиска ключевых фраз, где релевантные ключевые фразы извлекаются из предоставленного текста и возвращаются в качестве тем. Для этого подхода мы используем комбинацию метрик сходства, таких как косинусное сходство и TF-IDF, в дополнение к информации о совместном появлении слов для извлечения наиболее релевантных ключевых слов и фраз.
И абстрактные, и экстрактивные методы имеют свои плюсы и минусы, но, используя их вместе, мы можем воспользоваться сильными сторонами каждого из них. Абстрактная модель отлично справляется со сбором различных, но связанных деталей и нахождением немного более общей темы, которая подходит для всех из них. Однако она никогда не сможет предсказать тему, которую не видела во время обучения, и невозможно обучить ее всем мыслимым темам, которые могут возникнуть в разговоре! С другой стороны, экстрактивные модели могут извлекать ключевые слова и темы непосредственно из текста, что означает, что они не зависят от домена и могут извлекать темы, которые они никогда раньше не видели. Недостатком этого подхода является то, что иногда темы слишком похожи или слишком специфичны. Используя оба, мы нашли золотую середину между обобщаемым и специфичным для домена.
Извлечение элементов действий
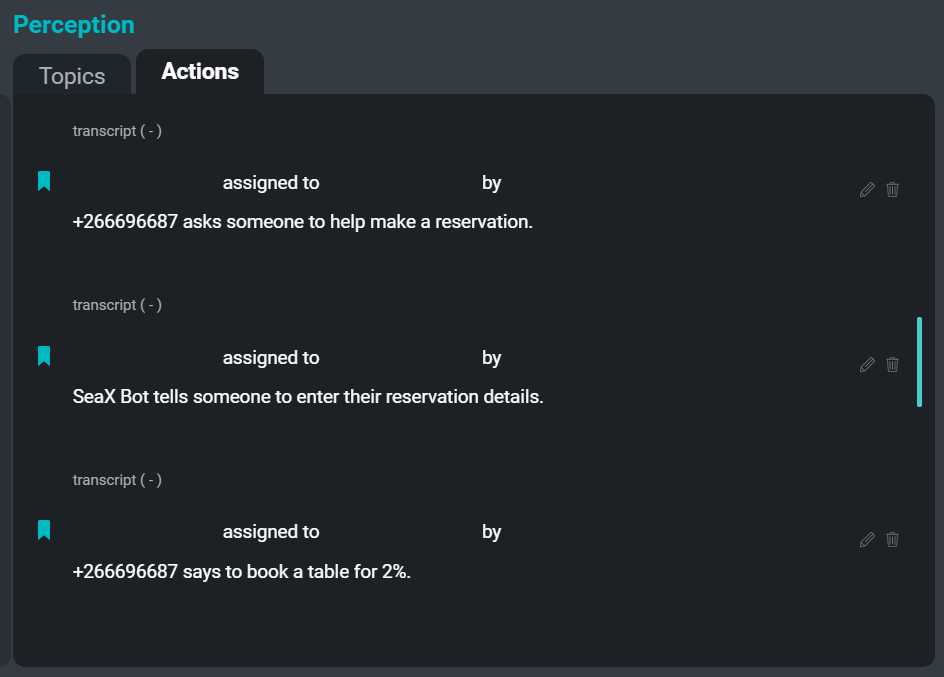
Пользовательский интерфейс SeaMeet, сфокусированный на вкладке «Действия» с правой стороны
Последняя проблема, которую мы решили облегчить для пользователей, — это задача записи элементов действий. Запись элементов действий — очень распространенная задача, которая поручается сотруднику во время встречи. Запись того, «кто кому что и когда сказал сделать», может быть чрезвычайно трудоемкой и может привести к тому, что пишущий будет отвлекаться и не сможет в полной мере участвовать во встрече. Автоматизируя этот процесс, мы надеемся снять часть этой ответственности с пользователя, чтобы каждый мог полностью посвятить свое внимание участию во встрече.
Ниже приведен пример некоторых элементов действий, которые можно извлечь из образца транскрипции:
предложение: «Сэм говорит, что у команды должны быть обновленные версии».
утверждение: «Ким говорит, что определенно будут крайние случаи, когда это не сработает».
императив: «Сюйчэнь говорит, что кто-то должен написать для этого правила».
желание: «Сюйчэнь говорит, что команда хочет, чтобы вспомогательный глагол присутствовал, но также хочет, чтобы были и имена людей».Целью системы извлечения действий является создание кратких абстрактных резюме элементов действий, извлеченных из транскрипций встреч. Результатом работы извлекателя действий над транскрипцией встречи является список команд, предложений, заявлений о намерениях и других действенных сегментов, которые могут быть представлены в виде задач или последующих действий для участников встречи. В будущем извлекатель также будет фиксировать имена исполнителей и поручителей, а также сроки выполнения, связанные с каждым элементом действия.
Конвейер извлечения действий имеет два основных компонента: классификатор и суммаризатор. Во-первых, каждый сегмент передается в многоклассовый классификатор и получает одну из следующих меток:
- Вопрос
- Императив
- Предложение
- Желание
- Утверждение
- Недейственный
Если сегмент получает любую метку, кроме «недейственный», он отправляется в компонент резюмирования вместе с двумя предыдущими сегментами в транскрипции, которые предоставляют больше контекста для резюмирования. Шаг резюмирования по существу такой же, как и автономный компонент резюмирования, однако модель обучается на специальном наборе данных, созданном специально для резюмирования элементов действий с желаемым форматом вывода.
SeaMeet обретает мозг
Это был большой шаг к созданию нашего собственного уникального продукта: обучение моделей резюмирования, а также извлечения тем и действий, чтобы продвинуть наш продукт еще дальше, и разработка красивого интерфейса, чтобы связать все воедино в потрясающий пакет. Это история на данный момент, начало пути Seasalt.ai по предоставлению лучших бизнес-решений на быстро развивающемся рынке и предоставлению миру SeaMeet: будущего современных встреч.


