





このブログシリーズを通して、Seasalt.aiが、その謙虚な始まりから、さまざまなハードウェアとモデルでサービスを最適化し、最先端のNLPシステムを統合し、最終的に共同の最新の会議ソリューションであるSeaMeetの完全な実現に至るまでの、バランスの取れた最新の会議体験を作成するまでの道のりを追ってください。
文字起こしを超えて
私たちが直面したこれまでのすべての障害は、私たちに重要な教訓を教えてくれました。それは、これらすべてを自分たちでより良く行うことができるということです。 そこで、ここSeasalt.aiのスタッフは、Azureの会話型文字起こし機能に対抗するために、独自の音響モデルと言語モデルのトレーニングに着手しました。 MicrosoftはMS Build 2019で素晴らしいプレゼンテーションを行い、Azureの音声サービスを非常に有能でありながら非常にアクセスしやすい製品として紹介しました。 感銘を受けた後、私たちは「ここからどこへ向かうのか?」という問いを投げかけざるを得ません。 このすでに重要な製品をどのように拡張できるでしょうか?最新の会議は堅牢な音声テキスト変換の可能性を示しましたが、そこで止まります。 Azureが私たちの話を聞くことができることはわかっていますが、もし私たちがAzureに私たちのために考えてもらうことができたらどうでしょうか? 文字起こしだけでは、製品は印象的ですが、アプリケーションはやや限定的です。
既存の音声テキスト変換技術を、文字起こしから洞察を生み出すことができるシステムと統合することで、期待を超え、ユーザーのニーズを予測する製品を提供できます。 SeaMeetの文字起こしの全体的な価値を向上させるために、要約、トピックの抽象化、アクションアイテムの抽出という3つのシステムを組み込むことにしました。 これらのそれぞれは、特定のユーザーのペインポイントを軽減するために選択されました。
デモンストレーションとして、次の短いトランスクリプトで要約、トピック、アクションシステムを実行した結果を示します。
キム:「ありがとう、Xuchen。この通話には多くの人が参加しているので、ミュートになっています。ミュートを解除するには、スター6を押してください。」
Xuchen:「OK、受信が悪いだけだと思いました。」
キム:「ええ。」
サム:「火曜日から30日間までの音声データを含む別のファイルを送信しました。更新されたバージョンがあるはずです。」
キム:「ですから、これが機能しないエッジケースが間違いなくあります。この例のように、いくつか見つけました。動詞から「like」を取り除き、話者が担当者であると言いますが、実際にはキャロルが担当者です。しかし、2番目の例のように、ジェイソンを割り当てるのではなく、ジェイソンに伝えるように自分自身を割り当てるので、私が担当者になりたいと思うのと同じパターンです。」
サム:「わかりました。」
Xuchen:「ですから、これの欠点は、そのためのルールを作成する必要があるということです。ええ、利点は、すでにトレーニング済みのモデルであるということです。さらにトレーニングすることもできますが、これに大量のデータを投入する必要はありません。」
キム:「しかし、これがアクションなのか、それとも他のものなのかを判断するための分類は行いません。」
Xuchen:「ですから、ここでの秘訣は、助動詞を存在させたいということですが、人名もいくつか欲しいということです。」
サム:「そうですね、そうでなければ、なぜなら。」
Xuchen:「ええ、ご存知のように、明らかに単語を含むインスタンスがたくさんある文がある場合。しかし、それらの多くはアクションの助けにはなりません。」要約
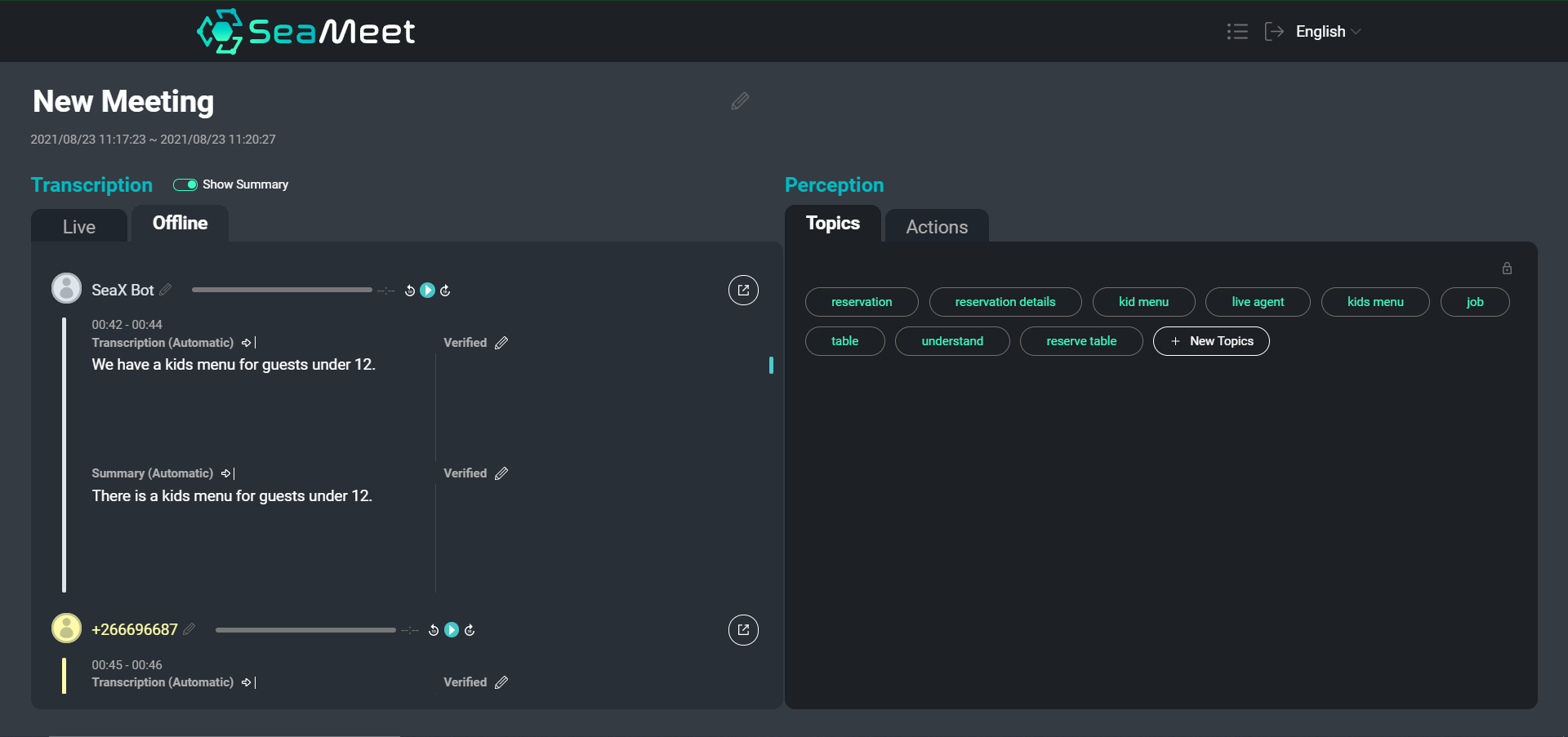
ユーザーの発話と左側に短い要約が表示されたSeaMeetインターフェースの概要
テキストの文字起こしをナビゲートすることは、何時間もの録音された音声を掘り下げるよりも確かに簡単ですが、特に長い会議の場合、特定のコンテンツを見つけたり、会話全体の概要を把握したりするのに時間がかかることがあります。 完全な文字起こしに加えて、2種類の要約を提供することにしました。
個々の発話レベルでの要約は、より簡潔で読みやすいセグメントを提供します。 さらに、短い要約は、意味的に空のセグメントを削除し、照応解析と共参照解決を実行することで、テキストを正規化するのに役立ちます。 その後、要約されたセグメントを下流のアプリケーション(トピックの抽象化など)にフィードして、最終結果を向上させることができます。
短い要約に加えて、会議全体の非常に一般的な概要を作成することを目的とした単一の長い要約も提供することにしました。 この要約は、会議の要旨のように機能し、主要な議題と結論のみをカバーします。
以下は、元のトランスクリプトの各セグメントを要約ジェネレーターに通した短い要約の例です。
キム:「Xuchenは、通話に多くの人が参加しているため、ミュートになっています。」
Xuchen:「受信が悪いだけです。」
サム:「火曜日から30日間までの音声データを含む別のファイルを送信しました。」
キム:「これが機能しないエッジケースがあります。」
Xuchen:「すでにトレーニング済みのモデルをトレーニングすることの欠点は、そのためのルールを作成する必要があることです。」
キム:「分類は、アクションを与える分類を行いません。」
Xuchen:「ここでの秘訣は、助動詞を存在させたいということですが、人名もいくつか欲しいということです。」
Xuchen:「単語を含む文がある場合、それらの多くはアクションの助けにはなりません。」そして、この例は、会議全体が1つの段落に要約されていることを示しています。
「Xuchenは、通話に多くの人が参加しているため、ミュートになっています。サムは、火曜日から30日間までの音声データを含む別のファイルを送信しました。Xuchenは、話者が担当者であるいくつかのエッジケースを見つけました。」短い要約コンポーネントと長い要約コンポーネントの両方の中核にあるのは、トランスフォーマーベースの要約モデルです。 抽象的な要約のために、対話データセットでモデルを微調整します。 データには、手書きの要約とペアになったさまざまな長さのテキストの抜粋が含まれています。 多言語要約には、同じパラダイムを使用しますが、データセットの翻訳版で微調整された多言語ベースモデルを利用します。 SeaMeetインターフェースから、ユーザーは機械で生成された要約を検証したり、独自の要約を提供したりするオプションもあります。 その後、これらのユーザー入力の要約を収集し、トレーニングセットに追加して、モデルを継続的に改善できます。
トピックの抽象化
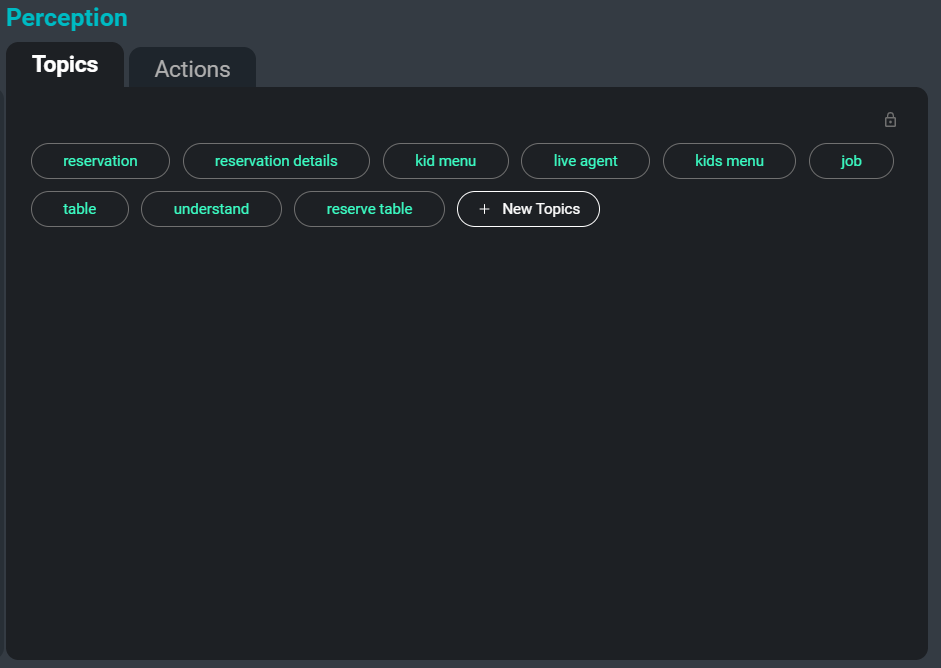
右側の「トピック」タブに焦点を当てたSeaMeetインターフェース
文字起こしの膨大なコレクションを扱う際のもう1つの問題は、それらを整理、分類、検索することです。 トランスクリプトからキーワードとトピックを自動的に抽象化することで、ユーザーは特定の会議、または関連するトピックが議論されている会議の特定のセクションを簡単に追跡する方法を提供できます。 さらに、これらのトピックは、トランスクリプトで最も重要で記憶に残る情報を要約する別の方法としても機能します。
以下は、サンプル文字起こしから抽出されるキーワードの例です。
助動詞
話者
音声データ
別のファイル
更新されたバージョン
人名
トレーニング済みモデル
ルールを作成するトピック抽出タスクでは、抽象的アプローチと抽出的アプローチを組み合わせて使用します。 抽象的とは、各入力をトレーニング中に見られたラベルのセットに分類するテキスト分類アプローチを指します。 この方法では、関連するトピックのリストとペアになったドキュメントでトレーニングされたニューラルアーキテクチャを使用しました。 抽出的とは、提供されたテキストから関連するキーフレーズを抽出し、トピックとして返すキーフレーズ検索アプローチを指します。 このアプローチでは、コサイン類似度やTF-IDFなどの類似性メトリックと、単語の共起情報を組み合わせて使用し、最も関連性の高いキーワードとフレーズを抽出します。
抽象的技術と抽出的技術の両方に長所と短所がありますが、それらを一緒に使用することで、それぞれの長所を活用できます。 抽象モデルは、明確で関連性のある詳細を収集し、それらすべてに適した少し一般的なトピックを見つけるのに優れています。 ただし、トレーニング中に見たことのないトピックを予測することはできず、会話で発生する可能性のあるすべての考えられるトピックについてトレーニングすることは不可能です。 一方、抽出的モデルは、テキストから直接キーワードとトピックを抽出できます。つまり、ドメインに依存せず、これまで見たことのないトピックを抽出できます。 このアプローチの欠点は、トピックが類似しすぎたり、具体的すぎたりすることがあることです。 両方を使用することで、一般化可能とドメイン固有の間の幸せな中間点を見つけました。
アクションアイテムの抽出
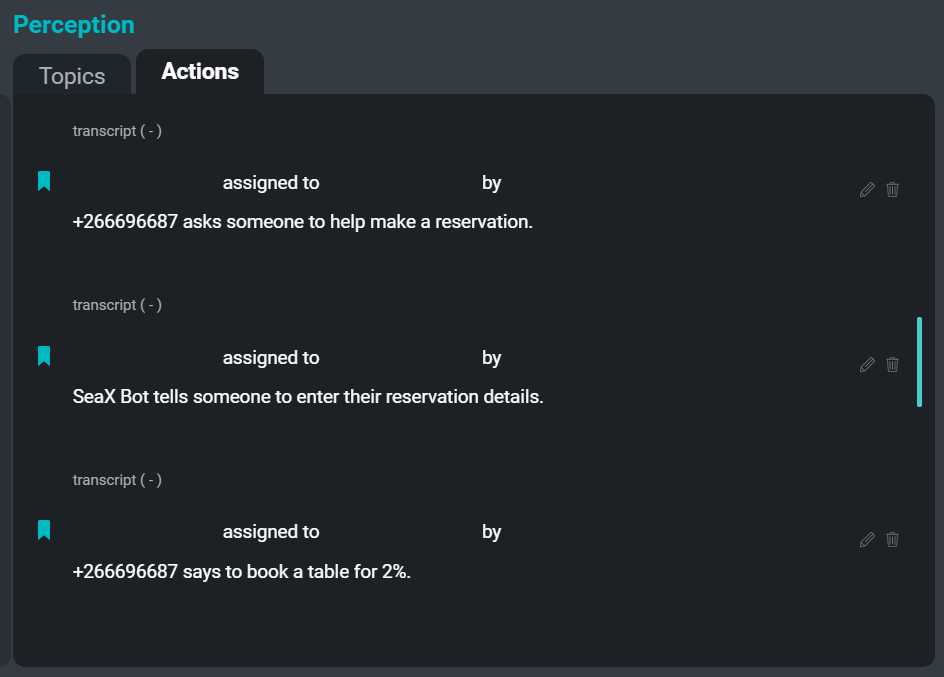
右側の「アクション」タブに焦点を当てたSeaMeet UI
ユーザーのために軽減しようと着手した最後のペインポイントは、アクションアイテムを記録するタスクです。 アクションアイテムの記録は、会議中に従業員に割り当てられる非常に一般的なタスクです。 「誰が誰にいつ何をするように言ったか」を書き留めることは、非常に時間がかかり、筆記者が気を取られて会議に完全に参加できなくなる可能性があります。 このプロセスを自動化することで、ユーザーからその責任の一部を軽減し、誰もが会議への参加に全神経を集中できるようにしたいと考えています。
以下は、サンプル文字起こしから抽出できるアクションアイテムの例です。
提案:「サムは、チームがいくつかの更新されたバージョンを持つべきだと言っています。」
声明:「キムは、これが機能しないエッジケースが間違いなくあると言っています。」
命令:「Xuchenは、誰かがそのためのルールを作成する必要があると言っています。」
希望:「Xuchenは、チームが助動詞を存在させたいだけでなく、人名もいくつか欲しいと言っています。」アクション抽出システムの目的は、会議の文字起こしから抽出されたアクションアイテムの短い抽象的な要約を作成することです。 会議の文字起こしに対してアクション抽出システムを実行した結果は、会議の参加者のためのToDoまたはフォローアップとして提示できるコマンド、提案、意図の表明、およびその他の実行可能なセグメントのリストです。 将来的には、抽出システムは、各アクションアイテムに関連付けられた担当者と依頼者の名前、および期日もキャプチャします。
アクション抽出パイプラインには、分類器と要約ジェネレーターという2つの主要なコンポーネントがあります。 まず、各セグメントは多クラス分類器に渡され、次のいずれかのラベルを受け取ります。
- 質問
- 命令
- 提案
- 希望
- 声明
- 実行不可能
セグメントが「実行不可能」以外のラベルを受け取った場合、トランスクリプトの前の2つのセグメントとともに要約コンポーネントに送信されます。これにより、要約のコンテキストがさらに提供されます。 要約ステップは、スタンドアロンの要約コンポーネントと基本的に同じですが、モデルは、目的の出力形式でアクションアイテムを要約するために特別に構築された特注のデータセットでトレーニングされます。
SeaMeetが頭脳を得る
これは、独自の製品を作成するための大きな一歩でした。要約、トピック、アクション抽出モデルをトレーニングして製品をさらに進化させ、すべてを素晴らしいパッケージにまとめる美しいインターフェースを設計しました。 これがこれまでの話であり、急速に進化する市場に最高のビジネスソリューションをもたらし、世界にSeaMeet(最新の会議の未来)を提供するというSeasalt.aiの旅の始まりです。


