





Sepanjang siri blog ini, ikuti perjalanan Seasalt.ai untuk mencipta Pengalaman Mesyuarat Moden yang menyeluruh, bermula dari permulaannya yang sederhana, kepada mengoptimumkan perkhidmatan kami pada perkakasan dan model yang berbeza, kepada mengintegrasikan sistem NLP yang canggih dan akhirnya berakhir dengan realisasi penuh SeaMeet, penyelesaian mesyuarat moden kolaboratif kami.
Melangkaui Transkripsi
Semua halangan sebelumnya yang kami hadapi mengajar kami pelajaran penting: bahawa kami boleh melakukan semua ini dengan lebih baik sendiri. Jadi, krew di Seasalt.ai mula melatih model akustik dan bahasa kami sendiri untuk menyaingi keupayaan transkripsi perbualan Azure. Microsoft mengadakan persembahan yang menakjubkan di MS Build 2019, mempamerkan Perkhidmatan Pertuturan Azure sebagai produk yang sangat berkebolehan namun sangat mudah diakses. Selepas kagum, kami terpaksa bertanya soalan, ke mana kita pergi dari sini? Bagaimanakah kita boleh mengembangkan produk yang sedia ada ini? Mesyuarat Moden menunjukkan potensi pertuturan ke teks yang mantap, tetapi di situlah ia berhenti. Kami tahu Azure boleh mendengar kami, tetapi bagaimana jika kami boleh membuatnya berfikir untuk kami? Dengan hanya transkripsi, walaupun produknya mengagumkan, aplikasinya agak terhad.
Dengan mengintegrasikan teknologi pertuturan-ke-teks sedia ada dengan sistem yang boleh menghasilkan pandangan daripada transkripsi, kami boleh menyampaikan produk yang melebihi jangkaan dan menjangka keperluan pengguna. Kami memutuskan untuk menggabungkan tiga sistem untuk meningkatkan nilai keseluruhan transkripsi SeaMeet kami: ringkasan, abstraksi topik, dan pengekstrakan item tindakan. Setiap satu daripadanya dipilih untuk mengurangkan titik kesakitan pengguna tertentu.
Untuk menunjukkan, kami akan menunjukkan hasil menjalankan sistem ringkasan, topik, dan tindakan pada transkrip pendek berikut:
Kim: "Terima kasih, Xuchen anda diredamkan kerana ramai orang dalam panggilan ini. Tekan Bintang 6 untuk menyahredam."
Xuchen: "OK saya fikir ia hanya penerimaan yang teruk.",
Kim: "Ya.",
Sam: "Saya baru sahaja menghantar fail berasingan dengan data pertuturan untuk hari Selasa sehingga 30 hari. Anda semua sepatutnya mempunyai beberapa versi yang dikemas kini.",
Kim: "Jadi pasti akan ada kes terpencil di mana ini tidak berfungsi. Saya sudah menemui beberapa seperti dalam contoh ini. Ia mengambil seperti daripada kata kerja di sana dan mengatakan penceramah adalah penerima tugas apabila sebenarnya lebih kepada Carol adalah penerima tugas di sana. tetapi ia adalah corak yang sama seperti sesuatu seperti yang kedua di mana anda benar-benar mahu saya menjadi penerima tugas kerana mereka tidak menugaskan Jason mereka menugaskan diri mereka untuk memberitahu Jason.",
Sam: "Faham.",
Xuchen: "Jadi kelemahan ini ialah anda perlu menulis peraturan untuknya. Ya, kelebihannya ialah ia adalah model yang sudah dilatih. Anda boleh melatihnya lebih lanjut tetapi kami tidak perlu membuang banyak data pada ini.",
Kim: "Walaupun ia tidak melakukan klasifikasi yang akan memberi kita Adakah ini tindakan atau ini yang lain?",
Xuchen: "Jadi, helahnya di sini ialah kita mahu kata kerja bantu hadir, tetapi kita juga mahu beberapa nama orang.",
Sam: "Betul jika tidak mungkin kerana.",
Xuchen: "Ya, jika ada ayat dengan anda tahu ada banyak contoh dengan perkataan yang jelas. Walau bagaimanapun, tidak banyak daripadanya akan membantu tindakan."Ringkasan
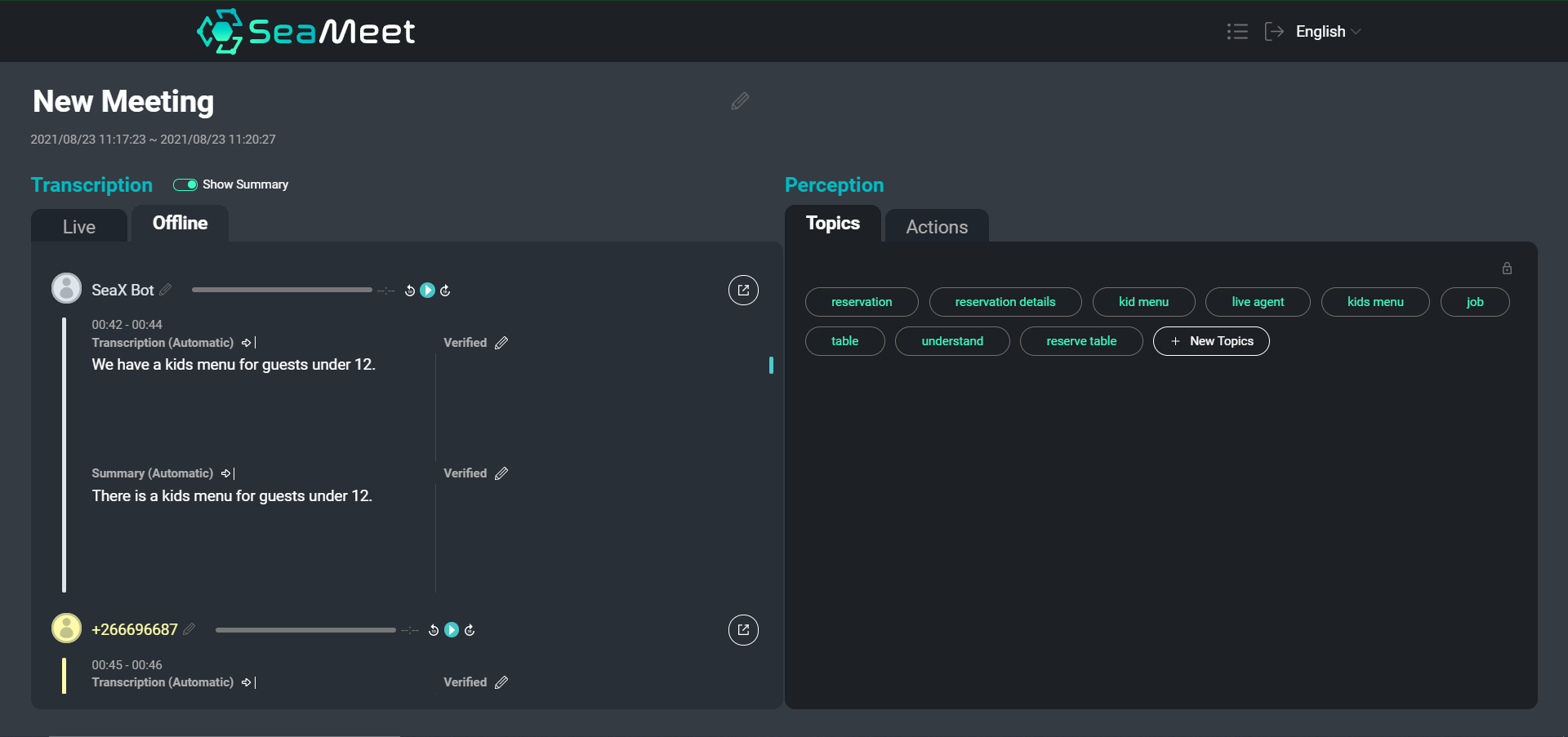
Gambaran keseluruhan antara muka SeaMeet kami, menampilkan ujaran pengguna dengan ringkasan pendeknya di sebelah kiri
Walaupun menavigasi transkripsi teks pastinya lebih mudah daripada menggali berjam-jam audio yang dirakam, untuk mesyuarat yang sangat panjang ia masih boleh memakan masa untuk mencari kandungan tertentu atau mendapatkan gambaran keseluruhan perbualan secara keseluruhan. Kami memilih untuk menyediakan dua jenis ringkasan sebagai tambahan kepada transkripsi penuh.
Ringkasan pada peringkat ujaran individu menyediakan segmen yang lebih ringkas dan mudah dibaca. Selain itu, ringkasan pendek membantu menormalkan teks dengan membuang segmen kosong semantik dan melakukan resolusi anafora & rujukan bersama. Kami kemudiannya boleh memasukkan segmen yang diringkaskan ke dalam aplikasi hiliran (seperti abstraksi topik) untuk meningkatkan hasil akhir.
Selain ringkasan pendek, kami juga memilih untuk menyediakan satu ringkasan panjang yang bertujuan untuk mencipta gambaran keseluruhan yang sangat umum bagi keseluruhan mesyuarat. Ringkasan ini berfungsi seperti abstrak untuk mesyuarat, hanya merangkumi perkara perbincangan utama dan kesimpulan.
Berikut ialah contoh ringkasan pendek, di mana kami memasukkan setiap segmen dalam transkrip asal melalui peringkas:
Kim: "Xuchen diredamkan kerana ramai orang dalam panggilan."
Xuchen: "Ia hanya penerimaan yang teruk."
Sam: "Saya menghantar fail berasingan dengan data pertuturan untuk hari Selasa sehingga 30 hari."
Kim: "Akan ada kes terpencil di mana ini tidak berfungsi."
Xuchen: "Kelemahan melatih model yang sudah dilatih ialah anda perlu menulis peraturan untuknya."
Kim: "Klasifikasi tidak melakukan klasifikasi yang akan memberi mereka tindakan."
Xuchen: "Helahnya di sini ialah mereka mahu kata kerja bantu hadir, tetapi mereka juga mahu beberapa nama orang."
Xuchen: "Jika ada ayat dengan perkataan, tidak banyak daripadanya akan membantu tindakan."Dan contoh ini menunjukkan keseluruhan mesyuarat diringkaskan dalam satu perenggan:
"Xuchen diredamkan kerana ramai orang dalam panggilan. Sam menghantar fail berasingan dengan data pertuturan untuk hari Selasa sehingga 30 hari. Xuchen telah menemui beberapa kes terpencil di mana penceramah adalah penerima tugas."Di tengah-tengah kedua-dua komponen ringkasan pendek dan panjang ialah model ringkasan berasaskan pengubah. Kami memperhalusi model pada set data dialog untuk ringkasan abstrak. Data tersebut mengandungi petikan teks pelbagai panjang setiap satu dipasangkan dengan ringkasan tulisan tangan. Untuk ringkasan berbilang bahasa, kami menggunakan paradigma yang sama, tetapi menggunakan model asas berbilang bahasa yang diperhalusi pada versi terjemahan set data. Daripada antara muka SeaMeet, pengguna juga mempunyai pilihan untuk mengesahkan ringkasan yang dihasilkan oleh mesin, atau menyediakan ringkasan mereka sendiri. Kami kemudiannya boleh mengumpul ringkasan yang dimasukkan oleh pengguna ini dan menambahkannya kembali ke set latihan kami untuk terus meningkatkan model kami.
Abstraksi Topik
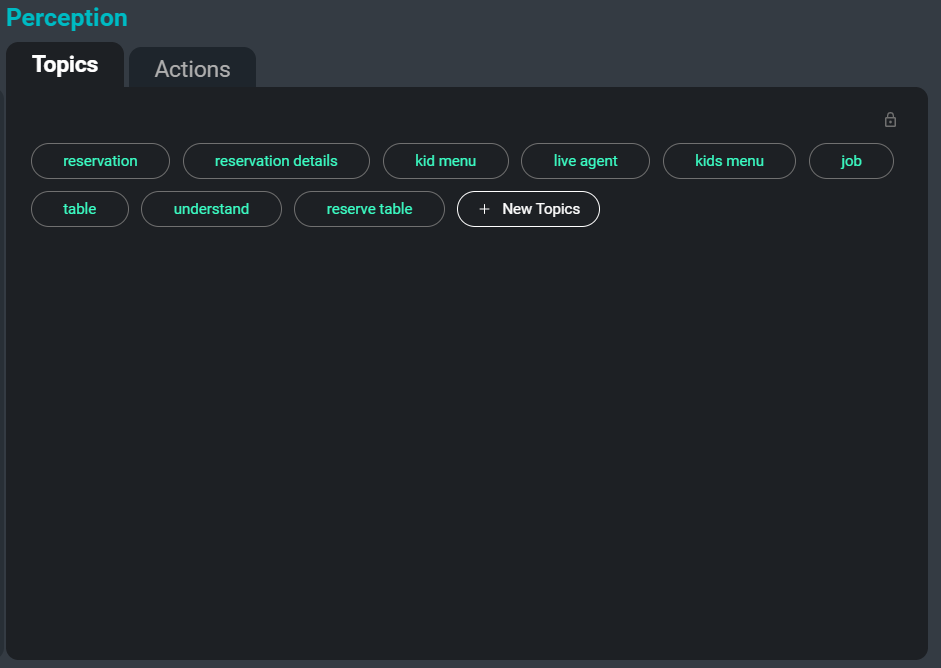
Antara muka SeaMeet, memfokuskan pada tab ‘Topik’ di sebelah kanan
Satu lagi masalah apabila berurusan dengan koleksi transkripsi yang besar ialah menyusun, mengkategorikan, dan mencarinya. Dengan mengabstrak kata kunci dan topik secara automatik daripada transkrip, kami boleh menyediakan pengguna cara yang mudah untuk menjejaki mesyuarat tertentu, atau bahkan bahagian tertentu mesyuarat di mana topik yang berkaitan sedang dibincangkan. Selain itu, topik-topik ini berfungsi sebagai satu lagi kaedah untuk meringkaskan maklumat yang paling penting dan diingati dalam transkrip.
Berikut ialah contoh kata kunci yang akan diekstrak daripada transkrip sampel:
kata kerja bantu
penceramah
data pertuturan
fail berasingan
versi yang dikemas kini
nama orang
model terlatih
tulis peraturanTugas pengekstrakan topik menggunakan gabungan pendekatan abstrak dan ekstraktif. Abstraktif merujuk kepada pendekatan klasifikasi teks, di mana setiap input diklasifikasikan ke dalam satu set label yang dilihat semasa latihan. Untuk kaedah ini kami menggunakan seni bina neural yang dilatih pada dokumen yang dipasangkan dengan senarai topik yang berkaitan. Ekstraktif merujuk kepada pendekatan carian frasa kunci di mana frasa kunci yang berkaitan diekstrak daripada teks yang disediakan dan dikembalikan sebagai topik. Untuk pendekatan ini, kami menggunakan gabungan metrik kesamaan seperti kesamaan kosinus & TF-IDF sebagai tambahan kepada maklumat kejadian bersama perkataan untuk mengekstrak kata kunci dan frasa yang paling relevan.
Kedua-dua teknik abstrak dan ekstraktif mempunyai kebaikan dan keburukan, tetapi dengan menggunakannya bersama-sama kita boleh memanfaatkan kekuatan masing-masing. Model abstrak sangat bagus untuk mengumpul butiran yang berbeza, tetapi berkaitan dan mencari topik yang sedikit lebih generik yang sesuai dengan semuanya. Walau bagaimanapun, ia tidak boleh meramalkan topik yang belum dilihatnya semasa latihan, dan adalah mustahil untuk melatih setiap topik yang boleh difikirkan yang mungkin timbul dalam perbualan! Model ekstraktif, sebaliknya, boleh menarik kata kunci dan topik terus dari teks, yang bermaksud ia bebas domain, dan boleh mengekstrak topik yang belum pernah dilihatnya sebelum ini. Kelemahan pendekatan ini ialah kadangkala topik terlalu serupa atau terlalu spesifik. Dengan menggunakan kedua-duanya, kami telah menemui jalan tengah yang gembira antara yang boleh digeneralisasikan dan khusus domain.
Pengekstrakan Item Tindakan
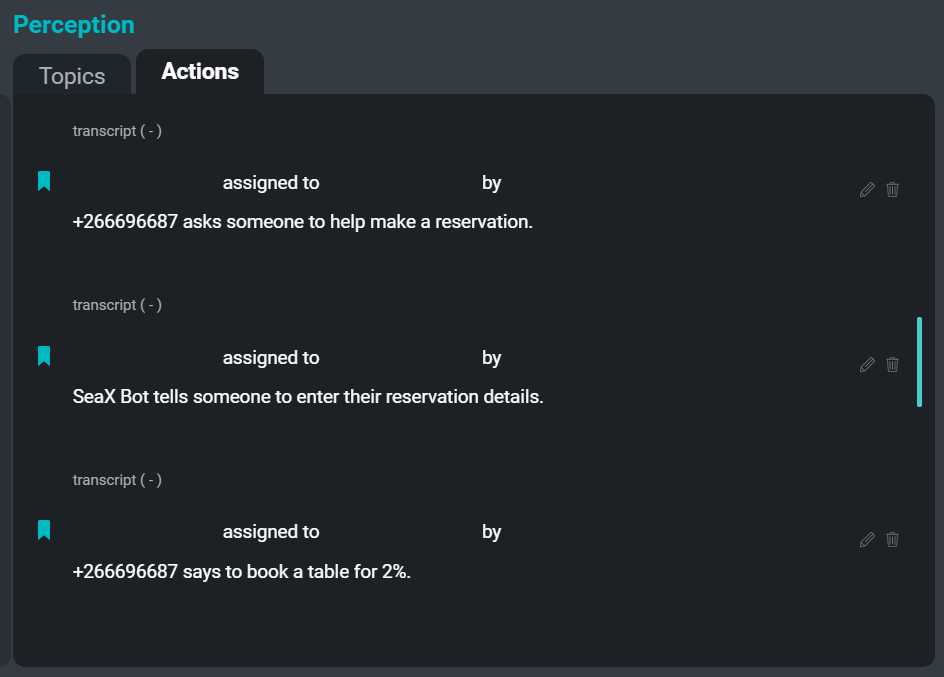
UI SeaMeet, memfokuskan pada tab ‘Tindakan’ di sebelah kanan
Titik kesakitan terakhir yang kami berhasrat untuk kurangkan untuk pengguna ialah tugas merekod item tindakan. Merekod item tindakan ialah tugas yang sangat biasa yang ditugaskan kepada seorang pekerja untuk dilakukan semasa mesyuarat. Menulis ‘siapa memberitahu siapa untuk melakukan apa bila’ boleh memakan masa yang sangat lama, dan boleh menyebabkan penulis terganggu dan tidak dapat mengambil bahagian sepenuhnya dalam mesyuarat. Dengan mengautomasikan proses ini, kami berharap dapat mengurangkan sebahagian daripada tanggungjawab itu daripada pengguna supaya semua orang dapat menumpukan perhatian sepenuhnya untuk mengambil bahagian dalam mesyuarat.
Berikut ialah contoh beberapa item tindakan yang boleh diekstrak daripada transkrip contoh:
cadangan: "Sam berkata pasukan itu sepatutnya mempunyai beberapa versi yang dikemas kini."
penyataan: "Kim berkata pasti akan ada kes terpencil di mana ini tidak berfungsi."
perintah: "Xuchen berkata seseorang perlu menulis peraturan untuknya."
keinginan: "Xuchen berkata pasukan itu mahu kata kerja bantu hadir, tetapi juga mahu beberapa nama orang."Tujuan sistem Pengekstrak Tindakan adalah untuk mencipta ringkasan abstrak pendek item tindakan yang diekstrak daripada transkripsi mesyuarat. Hasil menjalankan Pengekstrak Tindakan ke atas transkripsi mesyuarat ialah senarai arahan, cadangan, penyataan niat, dan segmen lain yang boleh diambil tindakan yang boleh dibentangkan sebagai tugasan atau susulan untuk peserta mesyuarat. Pada masa hadapan, pengekstrak juga akan menangkap nama penerima tugas & pemberi tugas serta tarikh akhir yang terikat pada setiap item tindakan.
Saluran paip pengekstrakan tindakan mempunyai dua komponen utama: pengelas dan peringkas. Pertama, setiap segmen dihantar ke dalam pengelas berbilang kelas dan menerima salah satu label berikut:
- Soalan
- Perintah
- Cadangan
- Keinginan
- Penyataan
- Tidak boleh diambil tindakan
Jika segmen menerima sebarang label selain daripada ‘tidak boleh diambil tindakan’, ia dihantar ke komponen ringkasan bersama-sama dengan dua segmen sebelumnya dalam transkrip, yang memberikan lebih banyak konteks untuk ringkasan. Langkah ringkasan pada asasnya adalah sama dengan komponen ringkasan yang berdiri sendiri, namun model dilatih pada set data yang ditempah khas yang dibina khusus untuk meringkaskan item tindakan dengan format output yang diingini.
SeaMeet Mendapat Otak
Ini telah menjadi satu langkah besar ke arah mencipta produk unik kami sendiri: melatih model ringkasan serta pengekstrakan topik dan tindakan untuk membawa produk kami lebih jauh, dan mereka bentuk antara muka yang indah untuk mengikat semuanya bersama-sama dalam pakej yang menakjubkan. Inilah kisahnya setakat ini, permulaan perjalanan Seasalt.ai untuk membawa penyelesaian perniagaan terbaik ke pasaran yang pesat berkembang dan menyampaikan kepada dunia, SeaMeet: Masa Depan Mesyuarat Moden.


