





A lo largo de esta serie de blogs, sigue el viaje de Seasalt.ai para crear una experiencia de reuniones modernas completa, comenzando con sus humildes comienzos, hasta la optimización de nuestro servicio en diferentes hardware y modelos, hasta la integración de sistemas de PNL de última generación y finalmente terminando en la realización completa de SeaMeet, nuestras soluciones colaborativas de reuniones modernas.
Más allá de la transcripción
Todos los obstáculos anteriores a los que nos enfrentamos nos enseñaron una lección importante: que podíamos hacer todo esto mejor por nosotros mismos. Así que el equipo de Seasalt.ai se dispuso a entrenar nuestros propios modelos acústicos y de lenguaje para competir con las capacidades del transcriptor conversacional de Azure. Microsoft hizo una presentación increíble en MS Build 2019, mostrando los Servicios de Voz de Azure como un producto muy capaz y a la vez muy accesible. Después de quedar impresionados, nos vemos obligados a hacernos la pregunta, ¿hacia dónde vamos desde aquí? ¿Cómo podemos expandir este producto ya instrumental? Las reuniones modernas demostraron un sólido potencial de conversión de voz a texto, pero ahí es donde se detiene. Sabemos que Azure puede escucharnos, pero ¿y si pudiéramos hacer que piense por nosotros? Con solo transcripciones, aunque el producto es impresionante, las aplicaciones son algo limitadas.
Al integrar la tecnología de conversión de voz a texto existente con sistemas que pueden producir información a partir de las transcripciones, podemos ofrecer un producto que supera las expectativas y anticipa las necesidades del usuario. Decidimos incorporar tres sistemas para mejorar el valor general de nuestras transcripciones de SeaMeet: resumen, abstracción de temas y extracción de elementos de acción. Cada uno de estos fue elegido para aliviar los puntos débiles específicos del usuario.
Para demostrarlo, mostraremos el resultado de ejecutar los sistemas de resúmenes, temas y acciones en la siguiente transcripción corta:
Kim: "Gracias, Xuchen, estás silenciado porque hay mucha gente en esta llamada. Presiona asterisco 6 para quitar el silencio."
Xuchen: "OK, pensé que era solo mala recepción."
Kim: "Sí."
Sam: "Acabo de enviar un archivo separado con datos de voz para los martes hasta dentro de 30 días. Deberían tener algunas versiones actualizadas."
Kim: "Así que definitivamente habrá casos extremos en los que esto no funcione. Ya encontré un par como en este ejemplo. Toma como si fuera el verbo y dice que el hablante es el asignado cuando en realidad es más bien Carol la asignada allí. Pero es el mismo patrón que algo como el segundo donde realmente quieres que yo sea el asignado porque no están asignando a Jason, se están asignando a sí mismos para decirle a Jason."
Sam: "Entendido."
Xuchen: "Así que la desventaja de esto es que tienes que escribir reglas para ello. Sí, la ventaja es que es un modelo ya entrenado. Puedes entrenarlo más, pero no tenemos que lanzarle una tonelada de datos a esto."
Kim: "Aunque no hace la clasificación que nos daría ¿Es esto una acción o es otra cosa?"
Xuchen: "Entonces, el truco aquí es que queremos que el verbo auxiliar esté presente, pero también queremos algunos nombres de personas."
Sam: "Correcto, de lo contrario podría ser porque."
Xuchen: "Sí, si hay una oración con, ya sabes, muchas instancias con palabras obvias. Sin embargo, no muchas de ellas ayudarían a las acciones."Resumen
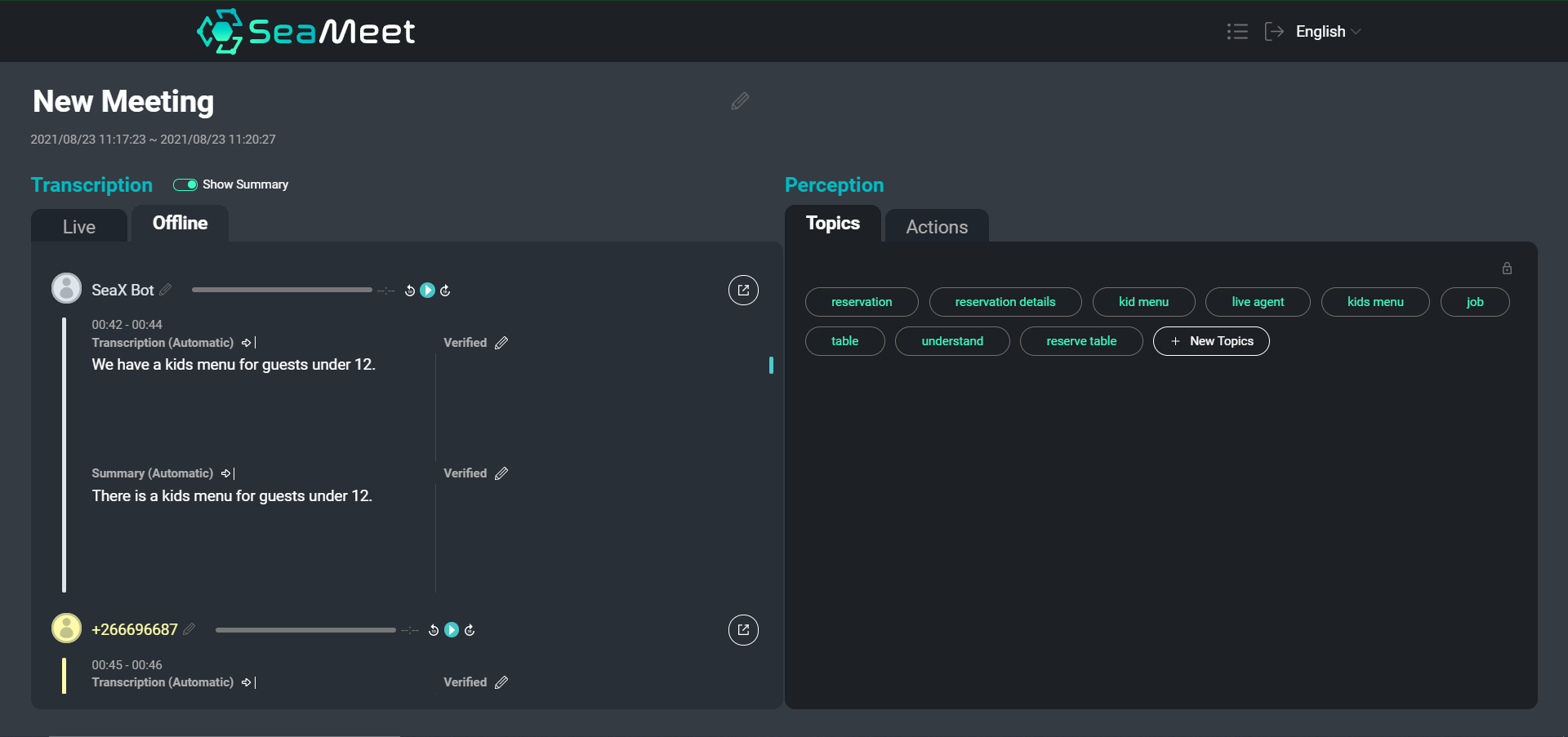
Una descripción general de nuestra interfaz SeaMeet, que muestra las expresiones de los usuarios con sus breves resúmenes a la izquierda
Si bien navegar por una transcripción de texto es ciertamente más fácil que buscar en horas de audio grabado, para reuniones particularmente largas todavía puede llevar mucho tiempo encontrar contenido específico u obtener una visión general de la conversación en su conjunto. Elegimos proporcionar dos tipos de resúmenes además de la transcripción completa.
Los resúmenes a nivel de expresión individual proporcionan segmentos más concisos y fáciles de leer. Además, los resúmenes breves ayudan a normalizar el texto eliminando segmentos semánticamente vacíos y realizando la resolución de anáforas y correferencias. Luego podemos alimentar los segmentos resumidos en aplicaciones posteriores (como la abstracción de temas) para mejorar los resultados finales.
Además de los resúmenes breves, también elegimos proporcionar un único resumen largo que tiene como objetivo crear una visión general muy general de toda la reunión. Este resumen funciona como un resumen de la reunión, cubriendo solo los puntos principales de conversación y las conclusiones.
El siguiente es un ejemplo de los resúmenes breves, donde pasamos cada segmento de la transcripción original a través del resumidor:
Kim: "Xuchen está silenciado porque hay mucha gente en la llamada."
Xuchen: "Es solo mala recepción."
Sam: "Envié un archivo separado con datos de voz para los martes hasta dentro de 30 días."
Kim: "Habrá casos extremos en los que esto no funcione."
Xuchen: "La desventaja de entrenar un modelo ya entrenado es que tienes que escribir reglas para ello."
Kim: "La clasificación no hace la clasificación que les daría una acción."
Xuchen: "El truco aquí es que quieren que el verbo auxiliar esté presente, pero también quieren algunos nombres de personas."
Xuchen: "Si hay una oración con palabras, no muchas de ellas ayudarían a las acciones."Y este ejemplo muestra toda la reunión resumida en un solo párrafo:
"Xuchen está silenciado porque hay mucha gente en la llamada. Sam envió un archivo separado con datos de voz para los martes hasta dentro de 30 días. Xuchen ha encontrado algunos casos extremos en los que el hablante es el asignado."En el núcleo de ambos componentes de resumen, el corto y el largo, se encuentra un modelo de resumen basado en transformadores. Afirmamos el modelo en un conjunto de datos de diálogo para el resumen abstracto. Los datos contienen extractos textuales de varias longitudes, cada uno emparejado con un resumen escrito a mano. Para el resumen multilingüe, utilizamos el mismo paradigma, pero utilizamos un modelo base multilingüe afinado en una versión traducida del conjunto de datos. Desde la interfaz de SeaMeet, el usuario también tiene la opción de verificar un resumen producido por la máquina o proporcionar el suyo propio. Luego podemos recopilar estos resúmenes ingresados por el usuario y agregarlos nuevamente a nuestro conjunto de entrenamiento para mejorar continuamente nuestros modelos.
Abstracción de temas
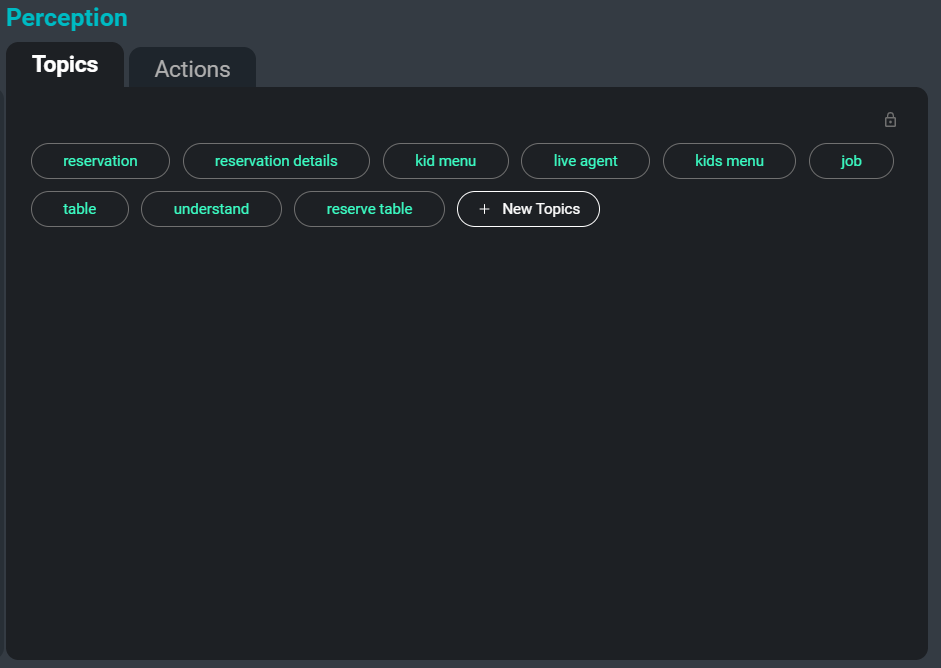
La interfaz de SeaMeet, centrada en la pestaña ‘Temas’ en el lado derecho
Otro problema al tratar con grandes colecciones de transcripciones es organizarlas, categorizarlas y buscarlas. Al abstraer automáticamente palabras clave y temas de la transcripción, podemos proporcionar a los usuarios una forma sencilla de rastrear ciertas reuniones, o incluso secciones específicas de reuniones donde se está discutiendo un tema relevante. Además, estos temas sirven como otro método para resumir la información más importante y memorable de una transcripción.
A continuación se muestra un ejemplo de palabras clave que se extraerían de la transcripción de ejemplo:
verbo auxiliar
hablante
datos de voz
archivo separado
versiones actualizadas
nombres de personas
modelo entrenado
escribir reglasLa tarea de extracción de temas utiliza una combinación de enfoques abstractos y extractivos. Abstractivo se refiere a un enfoque de clasificación de texto, donde cada entrada se clasifica en un conjunto de etiquetas vistas durante el entrenamiento. Para este método utilizamos una arquitectura neuronal entrenada en documentos emparejados con una lista de temas relevantes. Extractivo se refiere a un enfoque de búsqueda de frases clave donde se extraen frases clave relevantes del texto proporcionado y se devuelven como temas. Para este enfoque, utilizamos una combinación de métricas de similitud como la similitud del coseno y TF-IDF además de la información de co-ocurrencia de palabras para extraer las palabras clave y frases más relevantes.
Tanto las técnicas abstractas como las extractivas tienen pros y contras, pero al usarlas juntas podemos aprovechar las fortalezas de cada una. El modelo abstracto es excelente para recopilar detalles distintos pero relacionados y encontrar un tema un poco más genérico que se adapte a todos ellos. Sin embargo, nunca puede predecir un tema que no ha visto durante el entrenamiento, ¡y es imposible entrenar en todos los temas imaginables que puedan surgir en una conversación! Los modelos extractivos, por otro lado, pueden extraer palabras clave y temas directamente del texto, lo que significa que es independiente del dominio y puede extraer temas que nunca antes ha visto. La desventaja de este enfoque es que a veces los temas son demasiado similares o demasiado específicos. Al usar ambos, hemos encontrado un punto medio feliz entre generalizable y específico del dominio.
Extracción de elementos de acción
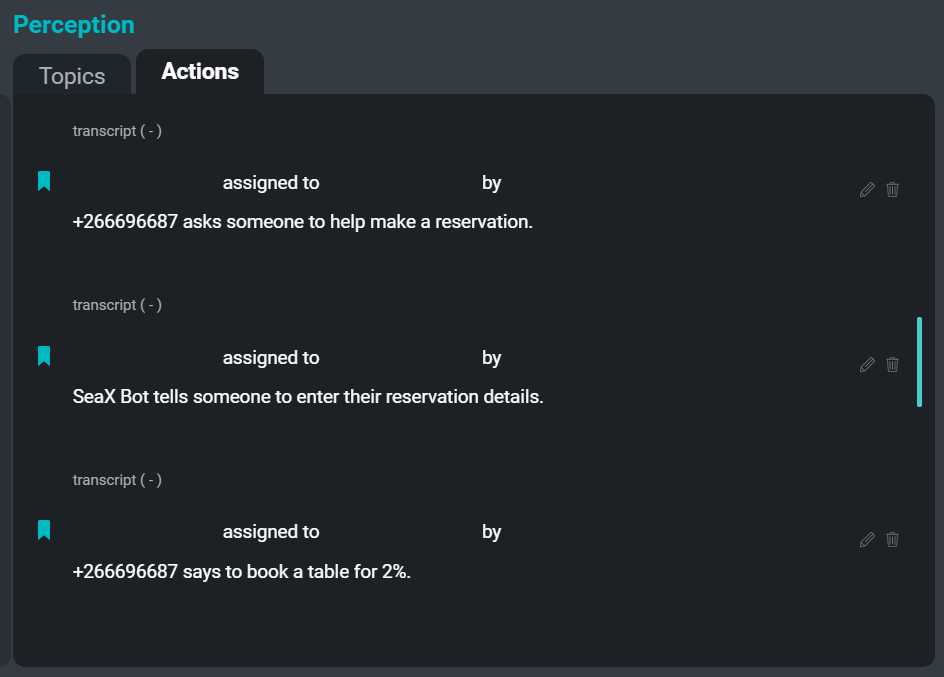
La interfaz de usuario de SeaMeet, centrada en la pestaña ‘Acciones’ en el lado derecho
El último punto débil que nos propusimos aliviar para los usuarios es la tarea de registrar los elementos de acción. Registrar los elementos de acción es una tarea muy común que se le asigna a un empleado para que la realice durante una reunión. Escribir ‘quién le dijo a quién que hiciera qué y cuándo’ puede llevar mucho tiempo y puede hacer que el escritor se distraiga y no pueda participar plenamente en la reunión. Al automatizar este proceso, esperamos aliviar parte de esa responsabilidad del usuario para que todos puedan dedicar toda su atención a participar en la reunión.
A continuación se muestra un ejemplo de algunos elementos de acción que podrían extraerse de la transcripción de ejemplo:
sugerencia: "Sam dice que el equipo debería tener algunas versiones actualizadas."
declaración: "Kim dice que definitivamente habrá casos extremos en los que esto no funcione."
imperativo: "Xuchen dice que alguien tiene que escribir reglas para ello."
deseo: "Xuchen dice que el equipo quiere que el verbo auxiliar esté presente, pero también quiere algunos nombres de personas."El propósito del sistema Extractor de Acciones es crear breves resúmenes abstractos de los elementos de acción extraídos de las transcripciones de las reuniones. El resultado de ejecutar el Extractor de Acciones sobre una transcripción de una reunión es una lista de comandos, sugerencias, declaraciones de intenciones y otros segmentos procesables que se pueden presentar como tareas pendientes o seguimientos para los participantes de la reunión. En el futuro, el extractor también capturará los nombres de los asignados y asignadores, así como las fechas de vencimiento vinculadas a cada elemento de acción.
El pipeline de extracción de acciones tiene dos componentes principales: un clasificador y un resumidor. Primero, cada segmento se pasa a un clasificador de clases múltiples y recibe una de las siguientes etiquetas:
- Pregunta
- Imperativo
- Sugerencia
- Deseo
- Declaración
- No procesable
Si el segmento recibe alguna etiqueta que no sea ‘no procesable’, se envía al componente de resumen junto con los dos segmentos anteriores en la transcripción, que proporcionan más contexto para el resumen. El paso de resumen es esencialmente el mismo que el componente de resumen independiente, sin embargo, el modelo se entrena en un conjunto de datos a medida construido específicamente para resumir elementos de acción con un formato de salida deseado.
SeaMeet tiene cerebro
Este ha sido un gran paso hacia la creación de nuestro propio producto único: entrenar modelos de resumen más extracción de temas y acciones para llevar nuestro producto aún más lejos, y diseñar una hermosa interfaz para unir todo en un paquete impresionante. Esta es la historia hasta ahora, el comienzo del viaje de Seasalt.ai para llevar las mejores soluciones comerciales a un mercado en rápida evolución y entregar al mundo, SeaMeet: El futuro de las reuniones modernas.


