





इस ब्लॉग श्रृंखला के दौरान, Seasalt.ai की एक अच्छी तरह से आधुनिक मीटिंग अनुभव बनाने की यात्रा का अनुसरण करें, इसकी विनम्र शुरुआत से लेकर, विभिन्न हार्डवेयर और मॉडलों पर हमारी सेवा का अनुकूलन करने, अत्याधुनिक एनएलपी सिस्टम को एकीकृत करने और अंत में SeaMeet, हमारे सहयोगी आधुनिक मीटिंग समाधानों की पूर्ण प्राप्ति पर समाप्त होने तक।
प्रतिलेखन से परे
पिछली सभी बाधाओं ने हमें एक महत्वपूर्ण सबक सिखाया: कि हम यह सब खुद से बेहतर कर सकते हैं। इसलिए यहां Seasalt.ai के कर्मचारियों ने Azure के संवादी ट्रांसक्राइबर की क्षमताओं को टक्कर देने के लिए अपने स्वयं के ध्वनिक और भाषा मॉडल को प्रशिक्षित करना शुरू कर दिया। Microsoft ने MS बिल्ड 2019 में एक अद्भुत प्रस्तुति दी, जिसमें Azure की स्पीच सेवाओं को एक अत्यधिक सक्षम और बहुत सुलभ उत्पाद के रूप में प्रदर्शित किया गया। वाह-वाह करने के बाद, हम यह सवाल पूछने के लिए मजबूर हैं कि हम यहां से कहां जाएं? हम इस पहले से ही महत्वपूर्ण उत्पाद पर कैसे विस्तार कर सकते हैं? आधुनिक बैठकों ने मजबूत भाषण से पाठ क्षमता का प्रदर्शन किया, लेकिन यह वहीं रुक जाता है। हम जानते हैं कि Azure हमें सुन सकता है, लेकिन क्या होगा अगर हम इसे हमारे लिए सोचने पर मजबूर कर सकें? केवल प्रतिलेखन के साथ, जबकि उत्पाद प्रभावशाली है, अनुप्रयोग कुछ हद तक सीमित हैं।
मौजूदा स्पीच-टू-टेक्स्ट तकनीक को उन प्रणालियों के साथ एकीकृत करके जो प्रतिलेखन से अंतर्दृष्टि उत्पन्न कर सकती हैं, हम एक ऐसा उत्पाद दे सकते हैं जो अपेक्षाओं से अधिक हो और उपयोगकर्ता की जरूरतों का अनुमान लगा सके। हमने अपने SeaMeet प्रतिलेखन के समग्र मूल्य में सुधार के लिए तीन प्रणालियों को शामिल करने का निर्णय लिया: सारांश, विषय अमूर्तता, और कार्रवाई आइटम निष्कर्षण। इनमें से प्रत्येक को विशिष्ट उपयोगकर्ता दर्द बिंदुओं को कम करने के लिए चुना गया था।
यह प्रदर्शित करने के लिए, हम निम्नलिखित लघु प्रतिलेख पर सारांश, विषय और क्रिया प्रणाली चलाने का परिणाम दिखाएंगे:
किम: "धन्यवाद, Xuchen आप म्यूट हैं क्योंकि इस कॉल पर बहुत से लोग हैं। अनम्यूट करने के लिए स्टार 6 दबाएं।"
Xuchen: "ठीक है, मुझे लगा कि यह सिर्फ खराब स्वागत है।"
किम: "हाँ।"
सैम: "मैंने अभी-अभी मंगलवार के लिए 30 दिनों तक के भाषण डेटा के साथ एक अलग फ़ाइल भेजी है। आप लोगों के पास कुछ अद्यतन संस्करण होने चाहिए।"
किम: "तो निश्चित रूप से ऐसे किनारे के मामले होंगे जहां यह काम नहीं करता है। मुझे इस उदाहरण में पहले से ही एक दो मिल गए हैं। यह क्रिया को वहां से बाहर ले जाता है और कहता है कि वक्ता असाइनी है जबकि वास्तव में कैरल वहां असाइनी है। लेकिन यह दूसरे की तरह ही पैटर्न है जहां आप वास्तव में चाहते हैं कि मैं असाइनी बनूं क्योंकि वे जेसन को असाइन नहीं कर रहे हैं, वे खुद को जेसन को बताने के लिए असाइन कर रहे हैं।"
सैम: "समझ गया।"
Xuchen: "तो इसका नकारात्मक पक्ष यह है कि आपको इसके लिए नियम लिखने होंगे। हाँ, इसका सकारात्मक पक्ष यह है कि यह पहले से ही एक प्रशिक्षित मॉडल है। आप इसे और प्रशिक्षित कर सकते हैं लेकिन हमें इस पर एक टन डेटा फेंकने की ज़रूरत नहीं है।"
किम: "हालांकि यह वह वर्गीकरण नहीं करता है जो हमें यह बताएगा कि यह एक क्रिया है या यह अन्य है?"
Xuchen: "तो, यहाँ चाल यह है कि हम चाहते हैं कि सहायक क्रिया मौजूद हो, लेकिन हम कुछ व्यक्ति के नाम भी चाहते हैं।"
सैम: "सही है अन्यथा हो सकता है क्योंकि।"
Xuchen: "हाँ, यदि कोई वाक्य है जिसमें आप जानते हैं, स्पष्ट शब्दों के साथ बहुत सारे उदाहरण हैं। हालाँकि, उनमें से बहुत से कार्यों में मदद नहीं करेंगे।"सारांश
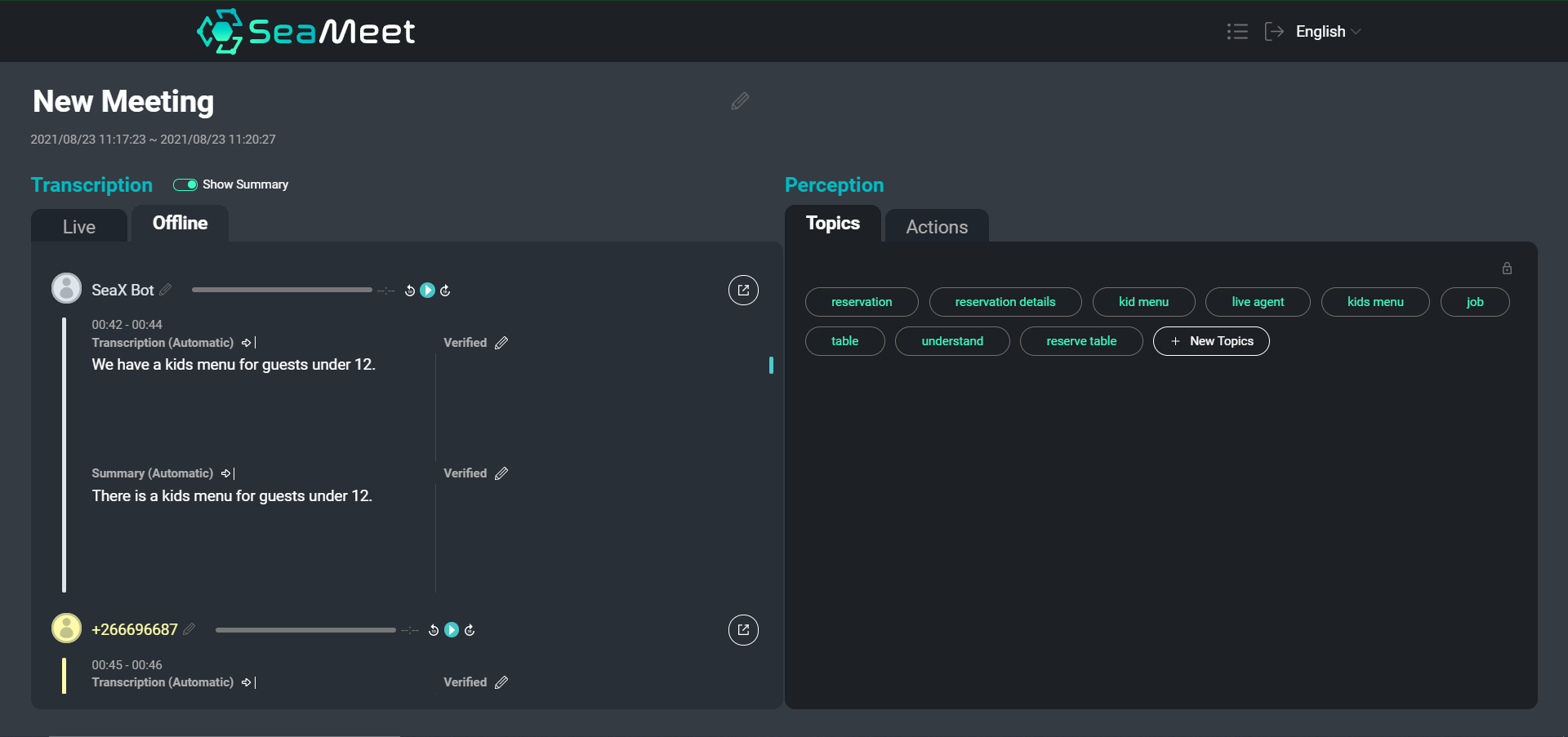
हमारे SeaMeet इंटरफ़ेस का एक सिंहावलोकन, जिसमें उपयोगकर्ता के उच्चारण उनके संक्षिप्त सारांश के साथ बाईं ओर हैं
जबकि एक पाठ प्रतिलेखन को नेविगेट करना निश्चित रूप से घंटों की रिकॉर्ड की गई ऑडियो के माध्यम से खोदने की तुलना में आसान है, विशेष रूप से लंबी बैठकों के लिए विशिष्ट सामग्री खोजने या समग्र रूप से बातचीत का अवलोकन प्राप्त करने में अभी भी समय लग सकता है। हमने पूर्ण प्रतिलेखन के अलावा दो प्रकार के सारांश प्रदान करने का विकल्प चुना।
व्यक्तिगत उच्चारण स्तर पर सारांश अधिक संक्षिप्त, पढ़ने में आसान खंड प्रदान करते हैं। इसके अतिरिक्त, संक्षिप्त सारांश शब्दार्थ रूप से खाली खंडों को हटाकर और एनाफोरा और सह-संदर्भ समाधान करके पाठ को सामान्य बनाने में मदद करते हैं। फिर हम अंतिम परिणामों को बेहतर बनाने के लिए सारांशित खंडों को डाउनस्ट्रीम अनुप्रयोगों (जैसे विषय अमूर्तता) में फीड कर सकते हैं।
संक्षिप्त सारांश के अलावा, हमने एक लंबा सारांश भी प्रदान करने का विकल्प चुना, जिसका उद्देश्य पूरी बैठक का एक बहुत ही सामान्य अवलोकन बनाना है। यह सारांश बैठक के लिए एक सार की तरह काम करता है, जिसमें केवल मुख्य वार्ता बिंदु और निष्कर्ष शामिल होते हैं।
निम्नलिखित संक्षिप्त सारांश का एक उदाहरण है, जहाँ हमने मूल प्रतिलेख में प्रत्येक खंड को सारांशक के माध्यम से फीड किया:
किम: "Xuchen म्यूट है क्योंकि कॉल पर बहुत से लोग हैं।"
Xuchen: "यह सिर्फ खराब स्वागत है।"
सैम: "मैंने मंगलवार के लिए 30 दिनों तक के भाषण डेटा के साथ एक अलग फ़ाइल भेजी।"
किम: "ऐसे किनारे के मामले होंगे जहां यह काम नहीं करता है।"
Xuchen: "पहले से प्रशिक्षित मॉडल को प्रशिक्षित करने का नकारात्मक पक्ष यह है कि आपको इसके लिए नियम लिखने होंगे।"
किम: "वर्गीकरण वह वर्गीकरण नहीं करता है जो उन्हें एक क्रिया देगा।"
Xuchen: "यहाँ चाल यह है कि वे चाहते हैं कि सहायक क्रिया मौजूद हो, लेकिन वे कुछ व्यक्ति के नाम भी चाहते हैं।"
Xuchen: "यदि शब्दों के साथ कोई वाक्य है, तो उनमें से बहुत से कार्यों में मदद नहीं करेंगे।"और यह उदाहरण पूरी बैठक को एक ही पैराग्राफ में सारांशित दिखाता है:
"Xuchen म्यूट है क्योंकि कॉल पर बहुत से लोग हैं। सैम ने मंगलवार के लिए 30 दिनों तक के भाषण डेटा के साथ एक अलग फ़ाइल भेजी। Xuchen को कुछ किनारे के मामले मिले हैं जहाँ वक्ता असाइनी है।"संक्षिप्त और लंबे दोनों सारांश घटकों के मूल में एक ट्रांसफार्मर-आधारित सारांश मॉडल है। हम सार सारांश के लिए एक संवाद डेटासेट पर मॉडल को ठीक करते हैं। डेटा में विभिन्न लंबाई के पाठ्य अंश होते हैं, जिनमें से प्रत्येक को हाथ से लिखे सारांश के साथ जोड़ा जाता है। बहुभाषी सारांश के लिए, हम उसी प्रतिमान का उपयोग करते हैं, लेकिन डेटासेट के अनुवादित संस्करण पर ठीक-ठाक एक बहुभाषी आधार मॉडल का उपयोग करते हैं। SeaMeet इंटरफ़ेस से, उपयोगकर्ता के पास मशीन-निर्मित सारांश को सत्यापित करने, या अपना स्वयं का प्रदान करने का विकल्प भी होता है। फिर हम इन उपयोगकर्ता-इनपुट सारांशों को एकत्र कर सकते हैं और अपने मॉडल को लगातार बेहतर बनाने के लिए उन्हें अपने प्रशिक्षण सेट में वापस जोड़ सकते हैं।
विषय अमूर्तता
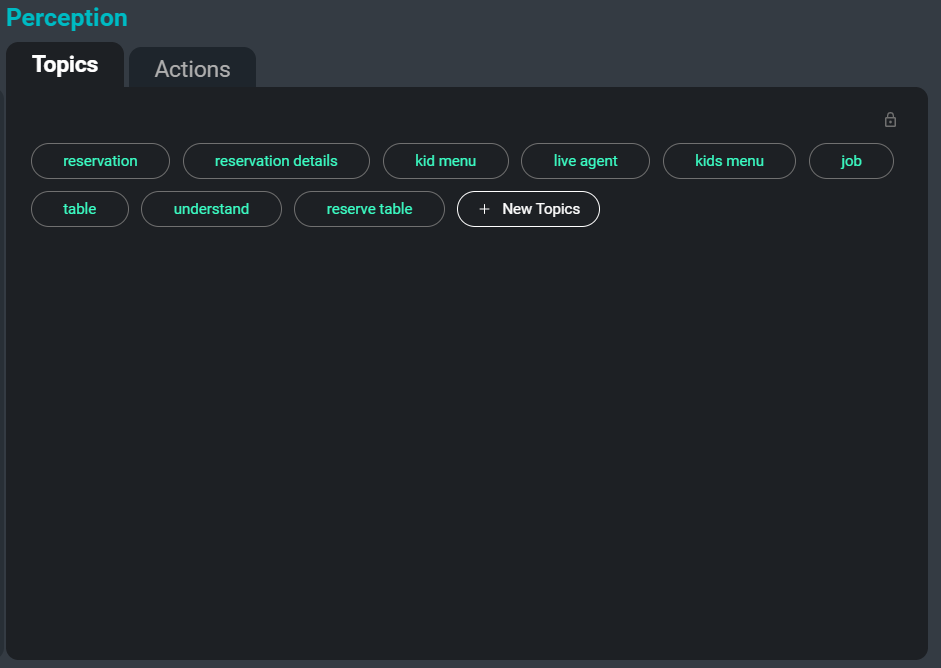
SeaMeet इंटरफ़ेस, दाईं ओर ‘विषय’ टैब पर केंद्रित है
प्रतिलेखन के बड़े संग्रह से निपटने में एक और समस्या उन्हें व्यवस्थित करना, वर्गीकृत करना और खोजना है। प्रतिलेख से कीवर्ड और विषयों को स्वचालित रूप से सार करके, हम उपयोगकर्ताओं को कुछ बैठकों, या बैठकों के विशिष्ट वर्गों को ट्रैक करने का एक सरल तरीका प्रदान कर सकते हैं जहाँ एक प्रासंगिक विषय पर चर्चा हो रही है। इसके अतिरिक्त, ये विषय एक प्रतिलेख में सबसे महत्वपूर्ण और यादगार जानकारी को सारांशित करने की एक और विधि के रूप में काम करते हैं।
यहाँ नमूना प्रतिलेख से निकाले जाने वाले कीवर्ड का एक उदाहरण दिया गया है:
सहायक क्रिया
वक्ता
भाषण डेटा
अलग फ़ाइल
अद्यतन संस्करण
व्यक्ति के नाम
प्रशिक्षित मॉडल
नियम लिखेंविषय निष्कर्षण कार्य सार और निकालने वाले दृष्टिकोणों के संयोजन का उपयोग करता है। सार एक पाठ वर्गीकरण दृष्टिकोण को संदर्भित करता है, जहाँ प्रत्येक इनपुट को प्रशिक्षण के दौरान देखे गए लेबल के एक सेट में वर्गीकृत किया जाता है। इस पद्धति के लिए हमने प्रासंगिक विषयों की सूची के साथ जोड़े गए दस्तावेजों पर प्रशिक्षित एक तंत्रिका वास्तुकला का उपयोग किया। निकालने वाला एक कीफ़्रेज़ खोज दृष्टिकोण को संदर्भित करता है जहाँ प्रासंगिक कीफ़्रेज़ प्रदान किए गए पाठ से निकाले जाते हैं और विषयों के रूप में लौटाए जाते हैं। इस दृष्टिकोण के लिए, हम सबसे प्रासंगिक कीवर्ड और वाक्यांशों को निकालने के लिए कोसाइन समानता और TF-IDF जैसे समानता मेट्रिक्स के संयोजन के साथ-साथ शब्द सह-घटना जानकारी का उपयोग करते हैं।
सार और निकालने वाली दोनों तकनीकों के फायदे और नुकसान हैं, लेकिन उन्हें एक साथ उपयोग करके हम प्रत्येक की ताकत का लाभ उठा सकते हैं। सार मॉडल अलग-अलग, लेकिन संबंधित विवरणों को इकट्ठा करने और थोड़ा और सामान्य विषय खोजने में बहुत अच्छा है जो उन सभी के लिए उपयुक्त है। हालाँकि, यह कभी भी ऐसे विषय की भविष्यवाणी नहीं कर सकता है जिसे उसने प्रशिक्षण के दौरान नहीं देखा है, और बातचीत में आने वाले हर बोधगम्य विषय पर प्रशिक्षित करना असंभव है! दूसरी ओर, निकालने वाले मॉडल सीधे पाठ से कीवर्ड और विषय खींच सकते हैं, जिसका अर्थ है कि यह डोमेन स्वतंत्र है, और उन विषयों को निकाल सकता है जिन्हें उसने पहले कभी नहीं देखा है। इस दृष्टिकोण का दोष यह है कि कभी-कभी विषय बहुत समान या बहुत विशिष्ट होते हैं। दोनों का उपयोग करके हमने सामान्यीकरण योग्य और डोमेन-विशिष्ट के बीच एक सुखद माध्यम पाया है।
कार्रवाई आइटम निष्कर्षण
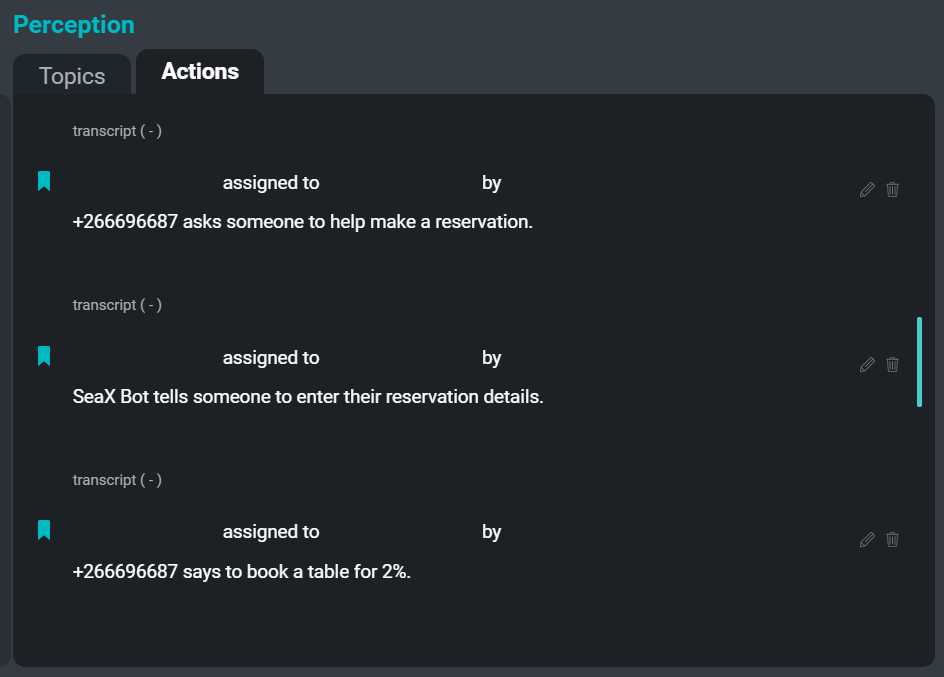
SeaMeet UI, दाईं ओर ‘एक्शन’ टैब पर केंद्रित है
अंतिम दर्द बिंदु जिसे हमने उपयोगकर्ताओं के लिए कम करने के लिए निर्धारित किया है, वह है कार्रवाई आइटम रिकॉर्ड करने का कार्य। कार्रवाई आइटम रिकॉर्ड करना एक बहुत ही सामान्य कार्य है जो एक कर्मचारी को एक बैठक के दौरान करने के लिए सौंपा जाता है। ‘किसने किसको कब क्या करने के लिए कहा’ लिखना बेहद समय लेने वाला हो सकता है, और लेखक को विचलित कर सकता है और बैठक में पूरी तरह से भाग लेने में असमर्थ हो सकता है। इस प्रक्रिया को स्वचालित करके, हम उपयोगकर्ता से उस जिम्मेदारी का कुछ हिस्सा कम करने की उम्मीद करते हैं ताकि हर कोई बैठक में भाग लेने पर अपना पूरा ध्यान समर्पित कर सके।
निम्नलिखित कुछ कार्रवाई आइटम का एक उदाहरण है जो उदाहरण प्रतिलेख से निकाला जा सकता है:
सुझाव: "सैम का कहना है कि टीम के पास कुछ अद्यतन संस्करण होने चाहिए।"
बयान: "किम का कहना है कि निश्चित रूप से ऐसे किनारे के मामले होंगे जहां यह काम नहीं करता है।"
अनिवार्य: "Xuchen का कहना है कि किसी को इसके लिए नियम लिखने होंगे।"
इच्छा: "Xuchen का कहना है कि टीम चाहती है कि सहायक क्रिया मौजूद हो, लेकिन कुछ व्यक्ति के नाम भी चाहती है।"एक्शन एक्सट्रैक्टर सिस्टम का उद्देश्य मीटिंग ट्रांसक्रिप्शन से निकाले गए एक्शन आइटम के छोटे सार सारांश बनाना है। एक मीटिंग ट्रांसक्रिप्शन पर एक्शन एक्सट्रैक्टर चलाने का परिणाम कमांड, सुझाव, इरादे के बयान और अन्य कार्रवाई योग्य खंडों की एक सूची है जिसे मीटिंग प्रतिभागियों के लिए टू-डू या फॉलो-अप के रूप में प्रस्तुत किया जा सकता है। भविष्य में, एक्सट्रैक्टर प्रत्येक कार्रवाई आइटम से जुड़े असाइनी और असाइनर्स के नाम के साथ-साथ देय तिथियों को भी कैप्चर करेगा।
एक्शन एक्सट्रैक्शन पाइपलाइन में दो मुख्य घटक होते हैं: एक क्लासिफायर और एक सारांशक। सबसे पहले, प्रत्येक खंड को एक बहु-वर्गीय क्लासिफायर में पास किया जाता है और निम्नलिखित में से एक लेबल प्राप्त होता है:
- प्रश्न
- अनिवार्य
- सुझाव
- इच्छा
- बयान
- गैर-कार्रवाई योग्य
यदि खंड को ‘गैर-कार्रवाई योग्य’ के अलावा कोई अन्य लेबल प्राप्त होता है, तो इसे प्रतिलेख में पिछले दो खंडों के साथ सारांश घटक को भेजा जाता है, जो सारांश के लिए अधिक संदर्भ प्रदान करते हैं। सारांश चरण अनिवार्य रूप से स्टैंड-अलोन सारांश घटक के समान है, हालांकि मॉडल को वांछित आउटपुट प्रारूप के साथ कार्रवाई आइटम को सारांशित करने के लिए विशेष रूप से निर्मित एक बीस्पोक डेटासेट पर प्रशिक्षित किया जाता है।
SeaMeet को एक दिमाग मिलता है
यह हमारे अपने अनूठे उत्पाद को बनाने की दिशा में एक बड़ा कदम रहा है: हमारे उत्पाद को और भी आगे ले जाने के लिए सारांश प्लस विषय और कार्रवाई निष्कर्षण मॉडल को प्रशिक्षित करना, और एक सुंदर इंटरफ़ेस डिजाइन करना ताकि सब कुछ एक आश्चर्यजनक पैकेज में एक साथ बंधा हो। यह अब तक की कहानी है, Seasalt.ai की यात्रा की शुरुआत जो तेजी से विकसित हो रहे बाजार में सर्वश्रेष्ठ व्यावसायिक समाधान लाने और दुनिया को SeaMeet देने के लिए है: आधुनिक बैठकों का भविष्य।


