





W całej tej serii blogów śledź podróż Seasalt.ai w tworzeniu wszechstronnego doświadczenia w zakresie nowoczesnych spotkań, począwszy od skromnych początków, poprzez optymalizację naszych usług na różnym sprzęcie i modelach, aż po integrację najnowocześniejszych systemów NLP i wreszcie pełną realizację SeaMeet, naszych wspólnych, nowoczesnych rozwiązań do spotkań.
Poza transkrypcją
Wszystkie poprzednie przeszkody, z którymi się borykaliśmy, nauczyły nas ważnej lekcji: że możemy zrobić to wszystko lepiej sami. Tak więc ekipa z Seasalt.ai zabrała się za szkolenie własnych modeli akustycznych i językowych, aby konkurować z możliwościami transkrypcji konwersacyjnej Azure. Microsoft zaprezentował niesamowitą prezentację na MS Build 2019, pokazując usługi mowy Azure jako wysoce wydajny, a jednocześnie bardzo przystępny produkt. Po zachwycie jesteśmy zmuszeni zadać sobie pytanie, dokąd zmierzamy? Jak możemy rozwinąć ten już instrumentalny produkt? Nowoczesne spotkania wykazały solidny potencjał zamiany mowy na tekst, ale na tym się kończy. Wiemy, że Azure może nas słuchać, ale co, jeśli uda nam się sprawić, by myślał za nas? Przy samych transkrypcjach, choć produkt jest imponujący, zastosowania są nieco ograniczone.
Integrując istniejącą technologię zamiany mowy na tekst z systemami, które mogą generować spostrzeżenia z transkrypcji, możemy dostarczyć produkt, który przekracza oczekiwania i przewiduje potrzeby użytkowników. Zdecydowaliśmy się włączyć trzy systemy w celu poprawy ogólnej wartości naszych transkrypcji SeaMeet: podsumowanie, abstrakcję tematów i wyodrębnianie elementów akcji. Każdy z nich został wybrany w celu złagodzenia określonych problemów użytkowników.
Aby to zademonstrować, pokażemy wynik uruchomienia systemów podsumowań, tematów i działań na następującym krótkim transkrypcie:
Kim: „Dziękuję, Xuchen, jesteś wyciszony, ponieważ na tym połączeniu jest wiele osób. Naciśnij gwiazdkę 6, aby wyłączyć wyciszenie”.
Xuchen: „OK, myślałem, że to po prostu zły odbiór”.
Kim: „Tak”.
Sam: „Właśnie wysłałem osobny plik z danymi mowy na wtorki do 30 dni. Powinniście mieć zaktualizowane wersje”.
Kim: „Więc na pewno będą przypadki brzegowe, w których to nie zadziała. Znalazłem już kilka, jak w tym przykładzie. Wyciąga jakby czasownik i mówi, że mówca jest cesjonariuszem, podczas gdy tak naprawdę to Carol jest cesjonariuszem. Ale to ten sam wzorzec, co w drugim przypadku, w którym naprawdę chcesz, żebym to ja był cesjonariuszem, ponieważ nie przypisują Jasona, tylko siebie, żeby powiedzieć Jasonowi”.
Sam: „Rozumiem”.
Xuchen: „Więc wadą tego jest to, że trzeba do tego pisać reguły. Tak, zaletą jest to, że jest to już wytrenowany model. Można go dalej trenować, ale nie musimy wrzucać do tego tony danych”.
Kim: „Chociaż nie wykonuje klasyfikacji, która dałaby nam informację, czy to jest działanie, czy coś innego?”.
Xuchen: „Więc sztuczka polega na tym, że chcemy, aby czasownik posiłkowy był obecny, ale chcemy też kilka imion”.
Sam: „Zgadza się, w przeciwnym razie może dlatego, że”.
Xuchen: „Tak, jeśli jest zdanie z, wiesz, wieloma wystąpieniami z oczywistymi słowami. Jednak niewiele z nich pomogłoby w działaniach”.Podsumowanie
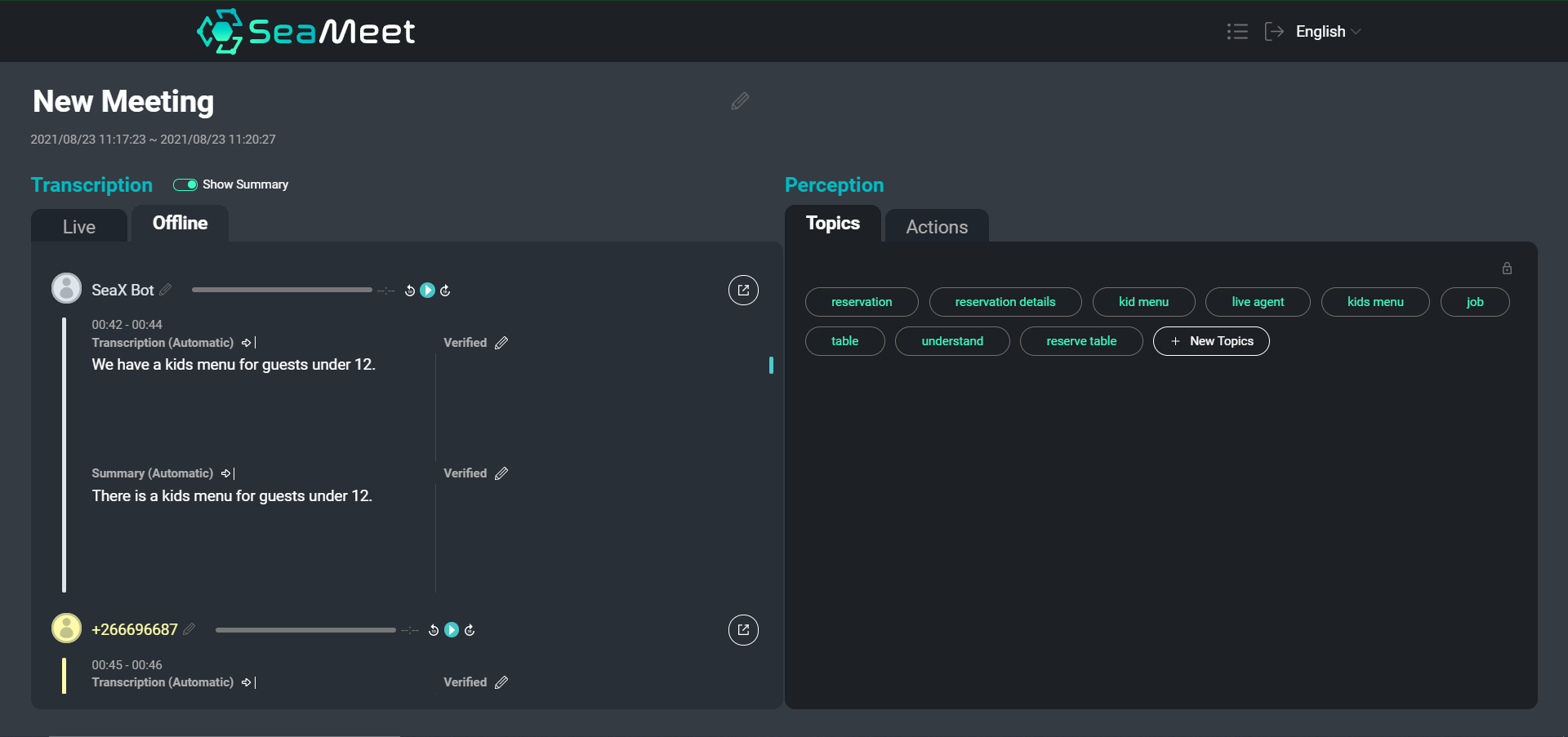
Przegląd naszego interfejsu SeaMeet, zawierający wypowiedzi użytkowników z ich krótkimi podsumowaniami po lewej stronie
Chociaż poruszanie się po transkrypcji tekstowej jest z pewnością łatwiejsze niż przeszukiwanie godzin nagranego dźwięku, w przypadku szczególnie długich spotkań znalezienie określonej treści lub uzyskanie przeglądu całej rozmowy może być nadal czasochłonne. Zdecydowaliśmy się udostępnić dwa rodzaje podsumowań oprócz pełnej transkrypcji.
Podsumowania na poziomie poszczególnych wypowiedzi zapewniają bardziej zwięzłe, łatwe do odczytania segmenty. Dodatkowo krótkie podsumowania pomagają znormalizować tekst, usuwając semantycznie puste segmenty i wykonując rozwiązywanie anafory i koreferencji. Następnie możemy przekazać podsumowane segmenty do dalszych aplikacji (takich jak abstrakcja tematów), aby poprawić wyniki końcowe.
Oprócz krótkich podsumowań zdecydowaliśmy się również udostępnić jedno długie podsumowanie, które ma na celu stworzenie bardzo ogólnego przeglądu całego spotkania. To podsumowanie działa jak streszczenie spotkania, obejmując tylko główne punkty dyskusji i wnioski.
Oto przykład krótkich podsumowań, w których każdy segment oryginalnego transkryptu przepuściliśmy przez sumaryzator:
Kim: „Xuchen jest wyciszony, ponieważ na połączeniu jest wiele osób”.
Xuchen: „To po prostu zły odbiór”.
Sam: „Wysłałem osobny plik z danymi mowy na wtorki do 30 dni”.
Kim: „Będą przypadki brzegowe, w których to nie zadziała”.
Xuchen: „Wadą trenowania już wytrenowanego modelu jest to, że trzeba do niego pisać reguły”.
Kim: „Klasyfikacja nie wykonuje klasyfikacji, która dałaby im działanie”.
Xuchen: „Sztuczka polega na tym, że chcą, aby czasownik posiłkowy był obecny, ale chcą też kilka imion”.
Xuchen: „Jeśli jest zdanie ze słowami, niewiele z nich pomoże w działaniach”.A ten przykład pokazuje całe spotkanie podsumowane w jednym akapicie:
„Xuchen jest wyciszony, ponieważ na połączeniu jest wiele osób. Sam wysłał osobny plik z danymi mowy na wtorki do 30 dni. Xuchen znalazł kilka przypadków brzegowych, w których mówca jest cesjonariuszem”.U podstaw zarówno krótkich, jak i długich komponentów podsumowania leży model podsumowania oparty na transformatorze. Dostrajamy model na zbiorze danych dialogowych do podsumowania abstrakcyjnego. Dane zawierają fragmenty tekstu o różnej długości, każdy w parze z ręcznie napisanym podsumowaniem. W przypadku podsumowania wielojęzycznego stosujemy ten sam paradygmat, ale wykorzystujemy wielojęzyczny model bazowy dostrojony na przetłumaczonej wersji zbioru danych. Z interfejsu SeaMeet użytkownik ma również możliwość zweryfikowania podsumowania wygenerowanego maszynowo lub podania własnego. Następnie możemy zebrać te podsumowania wprowadzone przez użytkownika i dodać je z powrotem do naszego zestawu treningowego, aby stale ulepszać nasze modele.
Abstrakcja tematów
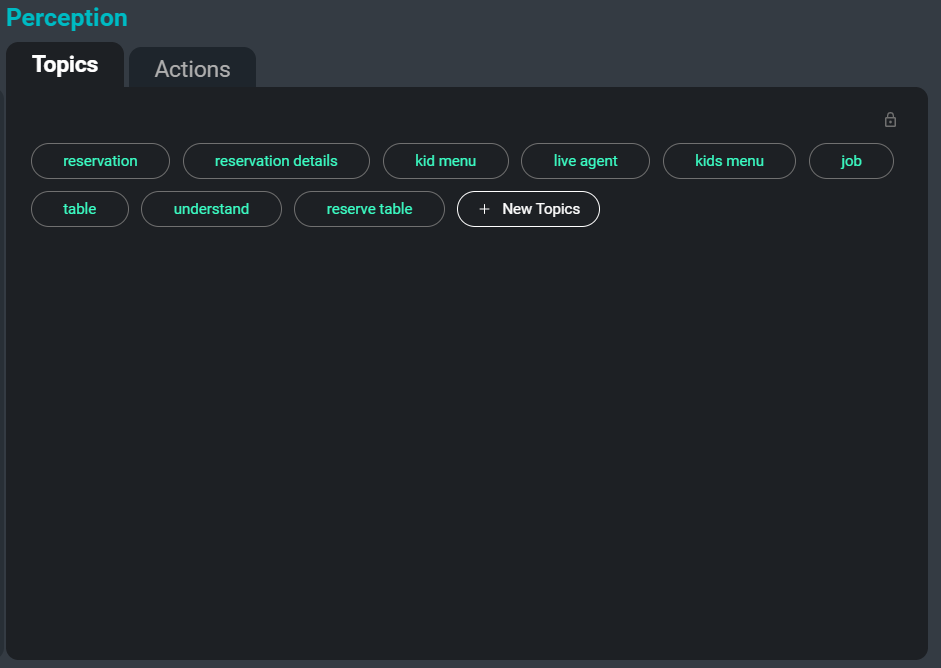
Interfejs SeaMeet, skoncentrowany na karcie „Tematy” po prawej stronie
Innym problemem podczas pracy z dużymi zbiorami transkrypcji jest ich organizowanie, kategoryzowanie i przeszukiwanie. Automatycznie abstrahując słowa kluczowe i tematy z transkrypcji, możemy zapewnić użytkownikom bezproblemowy sposób na śledzenie określonych spotkań, a nawet określonych sekcji spotkań, w których omawiany jest odpowiedni temat. Dodatkowo tematy te służą jako kolejna metoda podsumowania najważniejszych i najbardziej zapadających w pamięć informacji w transkrypcji.
Oto przykład słów kluczowych, które zostałyby wyodrębnione z przykładowego transkryptu:
czasownik posiłkowy
mówca
dane mowy
osobny plik
zaktualizowane wersje
imiona osób
wytrenowany model
pisać regułyZadanie ekstrakcji tematów wykorzystuje kombinację podejść abstrakcyjnych i ekstrakcyjnych. Abstrakcyjne odnosi się do podejścia do klasyfikacji tekstu, w którym każde dane wejściowe są klasyfikowane do zestawu etykiet widzianych podczas szkolenia. W tej metodzie wykorzystaliśmy architekturę neuronową wytrenowaną na dokumentach sparowanych z listą odpowiednich tematów. Ekstrakcyjne odnosi się do podejścia do wyszukiwania słów kluczowych, w którym odpowiednie słowa kluczowe są wyodrębniane z dostarczonego tekstu i zwracane jako tematy. W tym podejściu wykorzystujemy kombinację metryk podobieństwa, takich jak podobieństwo kosinusowe i TF-IDF, oprócz informacji o współwystępowaniu słów, aby wyodrębnić najbardziej odpowiednie słowa kluczowe i frazy.
Zarówno techniki abstrakcyjne, jak i ekstrakcyjne mają zalety i wady, ale stosując je razem, możemy wykorzystać mocne strony każdej z nich. Model abstrakcyjny świetnie radzi sobie ze zbieraniem odrębnych, ale powiązanych szczegółów i znajdowaniem nieco bardziej ogólnego tematu, który pasuje do nich wszystkich. Jednak nigdy nie może przewidzieć tematu, którego nie widział podczas szkolenia, i niemożliwe jest trenowanie na każdym możliwym temacie, który może pojawić się w rozmowie! Z drugiej strony modele ekstrakcyjne mogą wyciągać słowa kluczowe i tematy bezpośrednio z tekstu, co oznacza, że są niezależne od domeny i mogą wyodrębniać tematy, których nigdy wcześniej nie widziały. Wadą tego podejścia jest to, że czasami tematy są zbyt podobne lub zbyt szczegółowe. Stosując oba, znaleźliśmy szczęśliwy środek między uogólnialnym a specyficznym dla domeny.
Wyodrębnianie elementów akcji
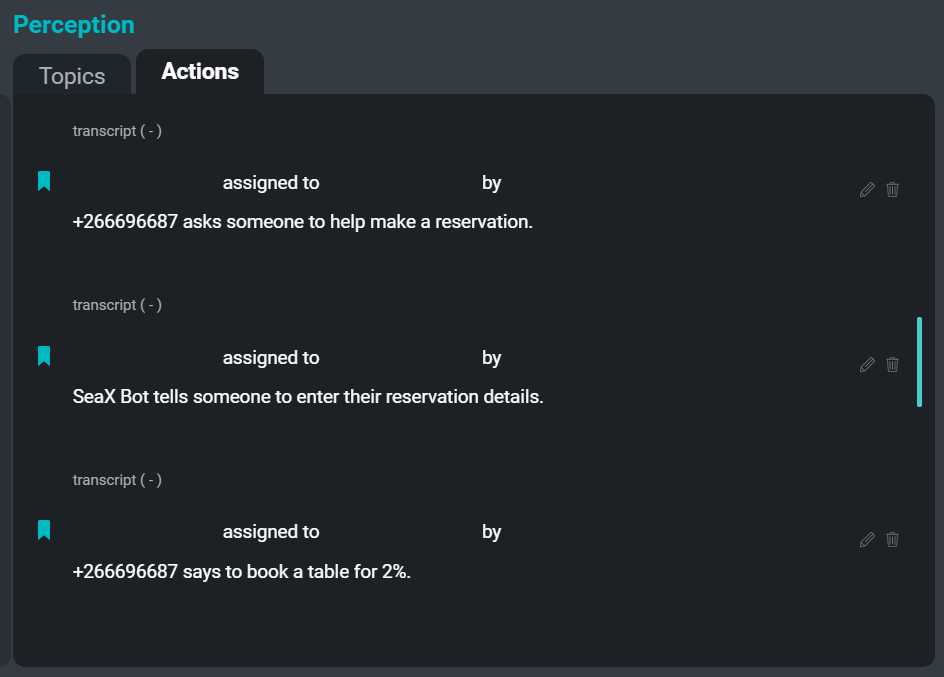
Interfejs użytkownika SeaMeet, skoncentrowany na karcie „Działania” po prawej stronie
Ostatnim problemem, który postanowiliśmy złagodzić dla użytkowników, jest zadanie rejestrowania elementów akcji. Rejestrowanie elementów akcji jest bardzo częstym zadaniem przydzielanym pracownikowi do wykonania podczas spotkania. Zapisywanie „kto komu kazał co i kiedy zrobić” może być niezwykle czasochłonne i może powodować rozproszenie uwagi piszącego i uniemożliwiać mu pełne uczestnictwo w spotkaniu. Automatyzując ten proces, mamy nadzieję odciążyć użytkownika od części tej odpowiedzialności, aby każdy mógł w pełni poświęcić swoją uwagę na uczestnictwo w spotkaniu.
Oto przykład niektórych elementów akcji, które można wyodrębnić z przykładowego transkryptu:
sugestia: „Sam mówi, że zespół powinien mieć zaktualizowane wersje”.
oświadczenie: „Kim mówi, że na pewno będą przypadki brzegowe, w których to nie zadziała”.
nakaz: „Xuchen mówi, że ktoś musi napisać do tego reguły”.
życzenie: „Xuchen mówi, że zespół chce, aby czasownik posiłkowy był obecny, ale chce też kilka imion”.Celem systemu ekstraktora działań jest tworzenie krótkich abstrakcyjnych podsumowań elementów działań wyodrębnionych z transkrypcji spotkań. Wynikiem uruchomienia ekstraktora działań na transkrypcji spotkania jest lista poleceń, sugestii, oświadczeń woli i innych segmentów, które można przedstawić jako zadania do wykonania lub działania następcze dla uczestników spotkania. W przyszłości ekstraktor będzie również przechwytywał nazwy cesjonariuszy i cedentów, a także terminy wykonania powiązane z każdym elementem akcji.
Potok ekstrakcji działań ma dwa główne komponenty: klasyfikator i sumaryzator. Po pierwsze, każdy segment jest przekazywany do klasyfikatora wieloklasowego i otrzymuje jedną z następujących etykiet:
- Pytanie
- Nakaz
- Sugestia
- Życzenie
- Oświadczenie
- Niedziałające
Jeśli segment otrzyma jakąkolwiek etykietę inną niż „niedziałające”, jest wysyłany do komponentu podsumowania wraz z dwoma poprzednimi segmentami w transkrypcji, które zapewniają więcej kontekstu dla podsumowania. Krok podsumowania jest zasadniczo taki sam, jak samodzielny komponent podsumowania, jednak model jest trenowany na niestandardowym zbiorze danych skonstruowanym specjalnie do podsumowywania elementów akcji w pożądanym formacie wyjściowym.
SeaMeet zyskuje mózg
To był duży krok w kierunku stworzenia naszego własnego, unikalnego produktu: szkolenie modeli podsumowania oraz ekstrakcji tematów i działań, aby jeszcze bardziej rozwinąć nasz produkt, oraz zaprojektowanie pięknego interfejsu, aby połączyć wszystko w oszałamiający pakiet. To jest historia do tej pory, początek podróży Seasalt.ai w dostarczaniu najlepszych rozwiązań biznesowych na szybko rozwijający się rynek i dostarczaniu światu SeaMeet: przyszłości nowoczesnych spotkań.


