





In dieser Blog-Serie folgen Sie der Reise von Seasalt.ai bei der Erstellung einer abgerundeten Modern Meetings Experience, angefangen bei den bescheidenen Anfängen über die Optimierung unseres Dienstes auf verschiedenen Hardware- und Modellen bis hin zur Integration modernster NLP-Systeme und schließlich zur vollständigen Realisierung von SeaMeet, unseren kollaborativen modernen Meeting-Lösungen.
Jenseits der Transkription
Alle bisherigen Hindernisse, mit denen wir konfrontiert waren, haben uns eine wichtige Lektion gelehrt: dass wir all dies besser selbst machen können. Also machte sich die Crew hier bei Seasalt.ai daran, unsere eigenen akustischen und sprachlichen Modelle zu trainieren, um mit den Fähigkeiten des Konversations-Transkribierers von Azure zu konkurrieren. Microsoft hat auf der MS Build 2019 eine beeindruckende Präsentation gehalten und die Speech Services von Azure als ein sehr leistungsfähiges und dennoch sehr zugängliches Produkt vorgestellt. Nachdem wir begeistert waren, müssen wir uns die Frage stellen, wohin wir von hier aus gehen sollen? Wie können wir dieses bereits instrumentelle Produkt erweitern? Modern Meetings demonstrierte ein robustes Potenzial für die Umwandlung von Sprache in Text, aber hier hört es auf. Wir wissen, dass Azure uns zuhören kann, aber was wäre, wenn wir es dazu bringen könnten, für uns zu denken? Mit reinen Transkriptionen ist das Produkt zwar beeindruckend, die Anwendungen sind jedoch etwas begrenzt.
Durch die Integration der bestehenden Speech-to-Text-Technologie mit Systemen, die aus den Transkriptionen Erkenntnisse gewinnen können, können wir ein Produkt liefern, das die Erwartungen übertrifft und die Bedürfnisse der Benutzer antizipiert. Wir haben uns entschieden, drei Systeme zu integrieren, um den Gesamtwert unserer SeaMeet-Transkriptionen zu verbessern: Zusammenfassung, Themenabstraktion und Aktionspunkt-Extraktion. Jedes dieser Systeme wurde ausgewählt, um spezifische Schmerzpunkte der Benutzer zu lindern.
Zur Demonstration zeigen wir das Ergebnis der Ausführung der Zusammenfassungs-, Themen- und Aktionssysteme für das folgende kurze Transkript:
Kim: "Danke, Xuchen, du bist stummgeschaltet, weil viele Leute in diesem Anruf sind. Drücke Sternchen 6, um die Stummschaltung aufzuheben."
Xuchen: "OK, ich dachte, es wäre nur schlechter Empfang."
Kim: "Ja."
Sam: "Ich habe gerade eine separate Datei mit Sprachdaten für Dienstage bis zu 30 Tagen verschickt. Ihr solltet einige aktualisierte Versionen haben."
Kim: "Es wird also definitiv Grenzfälle geben, in denen dies nicht funktioniert. Ich habe bereits ein paar gefunden, wie in diesem Beispiel. Es nimmt das Verb heraus und sagt, der Sprecher sei der Beauftragte, obwohl es in Wirklichkeit eher Carol ist. Aber es ist das gleiche Muster wie bei etwas wie dem zweiten, wo man wirklich will, dass ich der Beauftragte bin, weil sie Jason nicht beauftragen, sondern sich selbst beauftragen, es Jason zu sagen."
Sam: "Verstanden."
Xuchen: "Der Nachteil daran ist also, dass man irgendwie Regeln dafür schreiben muss. Ja, der Vorteil ist, dass es ein bereits trainiertes Modell ist. Man kann es weiter trainieren, aber wir müssen nicht eine Menge Daten darauf werfen."
Kim: "Obwohl es nicht die Klassifizierung durchführt, die uns sagen würde, ob dies eine Aktion ist oder etwas anderes."
Xuchen: "Also, der Trick hier ist, dass wir wollen, dass das Hilfsverb vorhanden ist, aber wir wollen auch einige Personennamen."
Sam: "Richtig, sonst könnte es daran liegen."
Xuchen: "Ja, wenn es einen Satz mit, wissen Sie, vielen Instanzen mit offensichtlichen Wörtern gibt. Allerdings würden nicht viele von ihnen bei den Aktionen helfen."Zusammenfassung
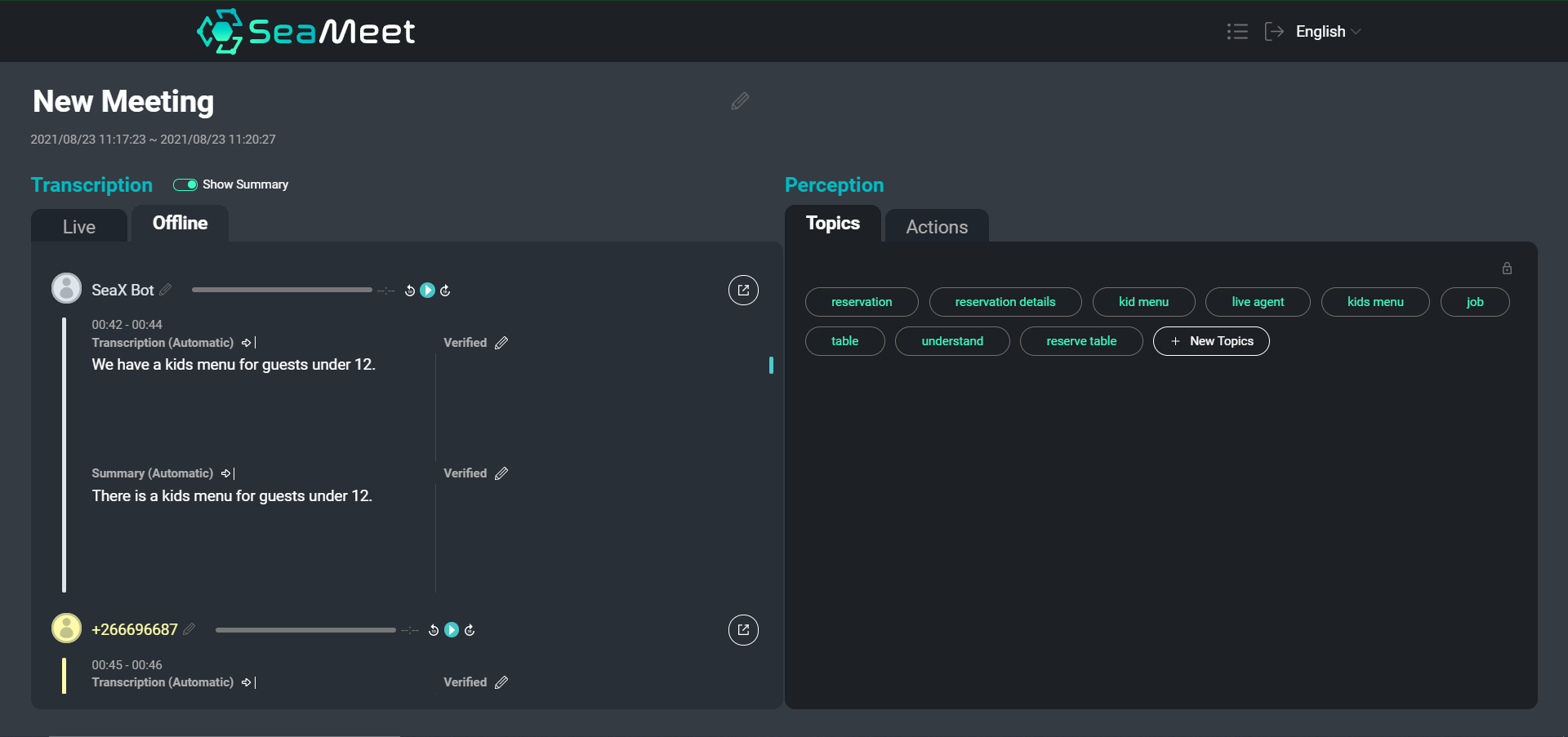
Ein Überblick über unsere SeaMeet-Oberfläche mit Benutzeräußerungen und deren kurzen Zusammenfassungen auf der linken Seite
Während die Navigation in einer Texttranskription sicherlich einfacher ist als das Durchsuchen von stundenlangem aufgezeichnetem Audio, kann es bei besonders langen Besprechungen dennoch zeitaufwändig sein, bestimmte Inhalte zu finden oder einen Überblick über das gesamte Gespräch zu erhalten. Wir haben uns entschieden, zusätzlich zur vollständigen Transkription zwei Arten von Zusammenfassungen bereitzustellen.
Zusammenfassungen auf der Ebene einzelner Äußerungen bieten prägnantere, leichter lesbare Segmente. Darüber hinaus helfen die kurzen Zusammenfassungen, den Text zu normalisieren, indem semantisch leere Segmente entfernt und Anaphern- und Koreferenzauflösung durchgeführt werden. Wir können dann die zusammengefassten Segmente in nachgelagerte Anwendungen (wie z. B. die Themenabstraktion) einspeisen, um die Endergebnisse zu verbessern.
Zusätzlich zu den kurzen Zusammenfassungen haben wir uns auch entschieden, eine einzige lange Zusammenfassung bereitzustellen, die darauf abzielt, einen sehr allgemeinen Überblick über die gesamte Besprechung zu erstellen. Diese Zusammenfassung fungiert wie ein Abstract für die Besprechung und deckt nur die wichtigsten Diskussionspunkte und Schlussfolgerungen ab.
Das folgende ist ein Beispiel für die kurzen Zusammenfassungen, bei denen wir jedes Segment im Originaltranskript durch den Zusammenfasser geschickt haben:
Kim: "Xuchen ist stummgeschaltet, weil viele Leute im Anruf sind."
Xuchen: "Es ist nur schlechter Empfang."
Sam: "Ich habe eine separate Datei mit Sprachdaten für Dienstage bis zu 30 Tagen verschickt."
Kim: "Es wird Grenzfälle geben, in denen dies nicht funktioniert."
Xuchen: "Der Nachteil beim Trainieren eines bereits trainierten Modells ist, dass man Regeln dafür schreiben muss."
Kim: "Die Klassifizierung führt nicht die Klassifizierung durch, die ihnen eine Aktion geben würde."
Xuchen: "Der Trick hier ist, dass sie wollen, dass das Hilfsverb vorhanden ist, aber sie wollen auch einige Personennamen."
Xuchen: "Wenn es einen Satz mit Wörtern gibt, werden nicht viele von ihnen bei den Aktionen helfen."Und dieses Beispiel zeigt die gesamte Besprechung, die in einem einzigen Absatz zusammengefasst ist:
"Xuchen ist stummgeschaltet, weil viele Leute im Anruf sind. Sam hat eine separate Datei mit Sprachdaten für Dienstage bis zu 30 Tagen verschickt. Xuchen hat einige Grenzfälle gefunden, in denen der Sprecher der Beauftragte ist."Im Kern beider Zusammenfassungskomponenten, der kurzen und der langen, befindet sich ein auf Transformatoren basierendes Zusammenfassungsmodell. Wir optimieren das Modell auf einem Dialogdatensatz für die abstrakte Zusammenfassung. Die Daten enthalten Textausschnitte unterschiedlicher Länge, die jeweils mit einer handgeschriebenen Zusammenfassung gepaart sind. Für die mehrsprachige Zusammenfassung verwenden wir dasselbe Paradigma, verwenden jedoch ein mehrsprachiges Basismodell, das auf einer übersetzten Version des Datensatzes optimiert wurde. Über die SeaMeet-Oberfläche hat der Benutzer auch die Möglichkeit, eine maschinell erstellte Zusammenfassung zu überprüfen oder eine eigene bereitzustellen. Wir können dann diese vom Benutzer eingegebenen Zusammenfassungen sammeln und sie wieder zu unserem Trainingssatz hinzufügen, um unsere Modelle kontinuierlich zu verbessern.
Themenabstraktion
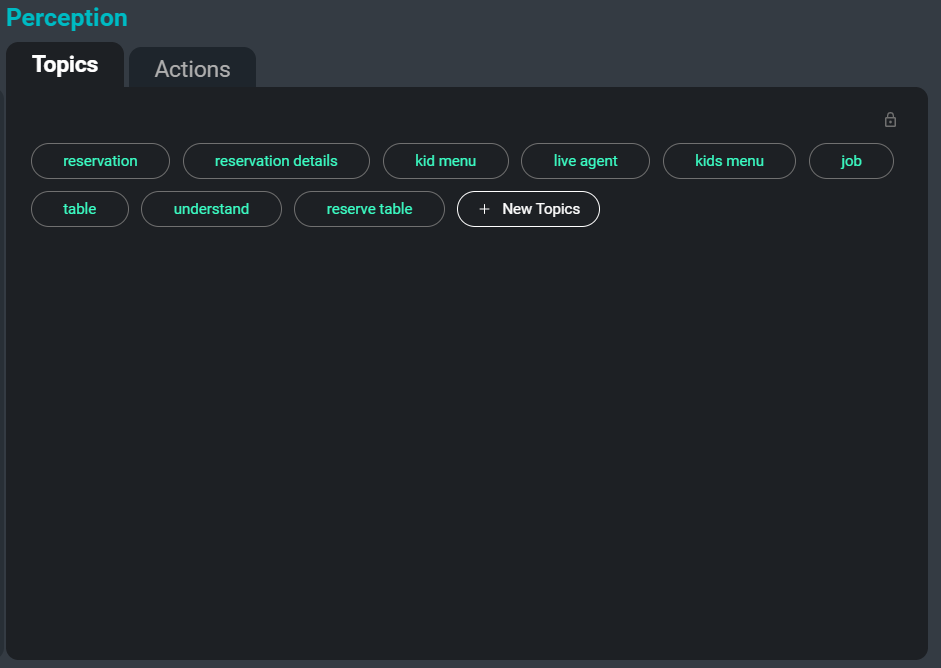
Die SeaMeet-Oberfläche, fokussiert auf den Reiter „Themen“ auf der rechten Seite
Ein weiteres Problem beim Umgang mit großen Sammlungen von Transkriptionen ist das Organisieren, Kategorisieren und Durchsuchen. Durch die automatische Abstraktion von Schlüsselwörtern und Themen aus dem Transkript können wir den Benutzern eine mühelose Möglichkeit bieten, bestimmte Besprechungen oder sogar bestimmte Abschnitte von Besprechungen, in denen ein relevantes Thema diskutiert wird, aufzuspüren. Darüber hinaus dienen diese Themen als eine weitere Methode zur Zusammenfassung der wichtigsten und denkwürdigsten Informationen in einem Transkript.
Hier ist ein Beispiel für Schlüsselwörter, die aus dem Beispieltranskript extrahiert würden:
Hilfsverb
Sprecher
Sprachdaten
separate Datei
aktualisierte Versionen
Personennamen
trainiertes Modell
Regeln schreibenDie Aufgabe der Themenextraktion verwendet eine Kombination aus abstrakten und extraktiven Ansätzen. Abstraktiv bezieht sich auf einen Textklassifizierungsansatz, bei dem jede Eingabe in einen Satz von Labels klassifiziert wird, die während des Trainings gesehen wurden. Für diese Methode haben wir eine neuronale Architektur verwendet, die auf Dokumenten trainiert wurde, die mit einer Liste relevanter Themen gepaart sind. Extraktiv bezieht sich auf einen Schlüsselwortsuchansatz, bei dem relevante Schlüsselwörter aus dem bereitgestellten Text extrahiert und als Themen zurückgegeben werden. Für diesen Ansatz verwenden wir eine Kombination von Ähnlichkeitsmetriken wie Kosinus-Ähnlichkeit und TF-IDF zusätzlich zu Informationen über das gemeinsame Auftreten von Wörtern, um die relevantesten Schlüsselwörter und Phrasen zu extrahieren.
Sowohl die abstrakten als auch die extraktiven Techniken haben Vor- und Nachteile, aber indem wir sie zusammen verwenden, können wir die Stärken jeder einzelnen nutzen. Das abstrakte Modell ist großartig darin, unterschiedliche, aber verwandte Details zu sammeln und ein etwas allgemeineres Thema zu finden, das zu allen passt. Es kann jedoch niemals ein Thema vorhersagen, das es während des Trainings nicht gesehen hat, und es ist unmöglich, auf jedes erdenkliche Thema zu trainieren, das in einem Gespräch auftauchen könnte! Die extraktiven Modelle hingegen können Schlüsselwörter und Themen direkt aus dem Text ziehen, was bedeutet, dass sie domänenunabhängig sind und Themen extrahieren können, die sie noch nie zuvor gesehen haben. Der Nachteil dieses Ansatzes ist, dass die Themen manchmal zu ähnlich oder zu spezifisch sind. Durch die Verwendung beider haben wir einen glücklichen Mittelweg zwischen verallgemeinerbar und domänenspezifisch gefunden.
Aktionspunkt-Extraktion
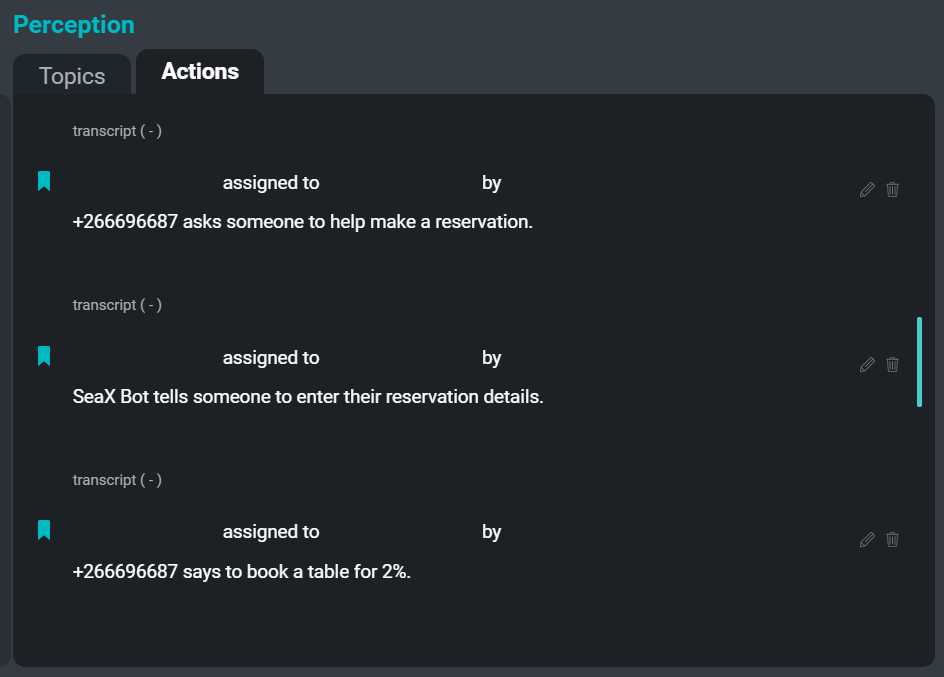
Die SeaMeet-Benutzeroberfläche, fokussiert auf den Reiter „Aktionen“ auf der rechten Seite
Der letzte Schmerzpunkt, den wir für die Benutzer lindern wollten, ist die Aufgabe, Aktionspunkte aufzuzeichnen. Das Aufzeichnen von Aktionspunkten ist eine sehr häufige Aufgabe, die einem Mitarbeiter während einer Besprechung zugewiesen wird. Das Aufschreiben von „wer wem was wann zu tun gesagt hat“ kann extrem zeitaufwändig sein und dazu führen, dass der Schreiber abgelenkt ist und nicht vollständig an der Besprechung teilnehmen kann. Durch die Automatisierung dieses Prozesses hoffen wir, dem Benutzer einen Teil dieser Verantwortung abzunehmen, damit jeder seine volle Aufmerksamkeit der Teilnahme an der Besprechung widmen kann.
Das folgende ist ein Beispiel für einige Aktionspunkte, die aus dem Beispieltranskript extrahiert werden könnten:
Vorschlag: "Sam sagt, das Team sollte einige aktualisierte Versionen haben."
Aussage: "Kim sagt, es wird definitiv Grenzfälle geben, in denen dies nicht funktioniert."
Befehl: "Xuchen sagt, jemand muss Regeln dafür schreiben."
Wunsch: "Xuchen sagt, das Team möchte, dass das Hilfsverb vorhanden ist, aber auch einige Personennamen."Der Zweck des Aktions-Extraktor-Systems besteht darin, kurze abstrakte Zusammenfassungen von Aktionspunkten zu erstellen, die aus Meeting-Transkriptionen extrahiert wurden. Das Ergebnis der Ausführung des Aktions-Extraktors über eine Meeting-Transkription ist eine Liste von Befehlen, Vorschlägen, Absichtserklärungen und anderen umsetzbaren Segmenten, die als Aufgaben oder Nachverfolgungen für die Meeting-Teilnehmer dargestellt werden können. In Zukunft wird der Extraktor auch die Namen der Beauftragten und Auftraggeber sowie die mit jedem Aktionspunkt verbundenen Fälligkeitstermine erfassen.
Die Aktions-Extraktions-Pipeline hat zwei Hauptkomponenten: einen Klassifikator und einen Zusammenfasser. Zuerst wird jedes Segment an einen Mehrklassen-Klassifikator übergeben und erhält eines der folgenden Labels:
- Frage
- Befehl
- Vorschlag
- Wunsch
- Aussage
- Nicht umsetzbar
Wenn das Segment ein anderes Label als „nicht umsetzbar“ erhält, wird es zusammen mit den beiden vorhergehenden Segmenten im Transkript an die Zusammenfassungskomponente gesendet, die mehr Kontext für die Zusammenfassung liefert. Der Zusammenfassungsschritt ist im Wesentlichen derselbe wie die eigenständige Zusammenfassungskomponente, jedoch wird das Modell auf einem maßgeschneiderten Datensatz trainiert, der speziell für die Zusammenfassung von Aktionspunkten mit einem gewünschten Ausgabeformat erstellt wurde.
SeaMeet bekommt ein Gehirn
Dies war ein großer Schritt zur Schaffung unseres eigenen einzigartigen Produkts: das Trainieren von Zusammenfassungs- sowie Themen- und Aktions-Extraktionsmodellen, um unser Produkt noch weiter zu bringen, und das Entwerfen einer schönen Oberfläche, um alles in einem atemberaubenden Paket zusammenzufügen. Dies ist die Geschichte bisher, der Beginn der Reise von Seasalt.ai, die besten Geschäftslösungen auf einen sich schnell entwickelnden Markt zu bringen und der Welt SeaMeet zu liefern: Die Zukunft moderner Meetings.


