





カスタマーサービスまたはマーケティングのディレクターの皆様へ、もし上司から以下の質問をされたら、この記事を送ってください。
“なぜ意図/エンティティベースのNLUは時代遅れで、LLM/GenAIが明らかなトレンドなのか?”
自然言語理解(NLU)システムは、テキストや音声などの自然言語入力を処理・分析し、意味を導き出し、関連情報を抽出し、コミュニケーションの根底にある意図を理解することを目的としています。NLUは、仮想アシスタント、チャットボット、感情分析ツール、言語翻訳システムなど、さまざまなAIアプリケーションの基本的なコンポーネントです。人間とコンピューターの相互作用を可能にし、自然言語入力を理解して応答できるインテリジェントなシステムの開発を促進する上で重要な役割を果たします。
この質問は、IVRとチャットボットのアプローチを再考している既存のクライアントから寄せられたものです。彼らは、通常、Microsoft Bot Framework(またはluis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLUなどの大手テクノロジー企業が提供する、前世代のNLUベースの技術スタックに縛られています。
課題は、保険会社、金融機関、政府、航空会社/自動車販売店、その他の大手企業などの主要なクライアントが、すでに前世代のテクノロジーを導入していることです。しかし、意図/エンティティベースのNLUはスケーラブルではないため、クライアントはNLUシステムを維持およびアップグレードするために毎年数十万ドルから数百万ドルを費やす必要があります。このスケーラビリティの欠如は、メンテナンスコストの増加に貢献し、最終的にはクライアントを犠牲にして前世代のNLUプロバイダーに利益をもたらします。スケーラブルではないため、メンテナンスコストは年々高くなります。
なぜ意図/エンティティベースのNLUは効果的にスケールできないのか?
主な理由は、モデルの識別能力が限られていることにあります。その理由を以下に示します。
-
最小限の意図要件: NLUモデルは、効果的にトレーニングするために少なくとも2つの異なる意図を必要とします。たとえば、天気について尋ねる場合、意図は明確かもしれませんが、各クエリの背後には、フォールバックや「元気ですか?」のような天気とは関係のない問い合わせなど、複数の潜在的な意図が存在します。
-
トレーニングデータの要求: 大手テクノロジー企業は通常、効果的なトレーニングのために、意図ごとに数千の肯定的な例を要求します。この広範なデータセットは、モデルが異なる意図を正確に学習し、区別するために必要です。
-
肯定例と否定例のバランス: ある意図に肯定例を追加すると、他の意図には否定例を含める必要があります。このバランスの取れたアプローチにより、NLUモデルは肯定例と否定例の両方から効果的に学習できます。
-
多様な例のセット: 過学習を防ぎ、モデルがさまざまなコンテキストで一般化する能力を高めるために、肯定例と否定例の両方が多様である必要があります。
-
新しい意図の追加の複雑さ: 既存のNLUモデルに新しい意図を追加することは、骨の折れるプロセスです。数千の肯定例と否定例を追加し、その後、ベースラインのパフォーマンスを維持するためにモデルを再トレーニングする必要があります。このプロセスは、意図の数が増えるにつれてますます困難になります。
処方効果:意図/エンティティベースのNLUの落とし穴

意図/エンティティベースのNLUの処方効果
医学における「処方カスケード」として知られる現象と同様に、意図/エンティティベースのNLUのスケーラビリティの課題は、恐ろしい処方カスケードに例えることができます。毎日大量の薬を服用している高齢者を想像してみてください。それぞれの薬は、前の薬の副作用に対処するために処方されています。このシナリオはあまりにもよく知られており、薬Aの導入が副作用を引き起こし、それに対抗するために薬Bの処方が必要になります。しかし、薬Bは独自の副作用を引き起こし、薬Cなどが必要になります。その結果、高齢者は管理すべき薬の山に埋もれてしまいます。これが処方カスケードです。
もう一つの分かりやすい比喩は、ブロックの塔を建てることです。各ブロックは薬を表しています。最初に薬Aが置かれますが、その不安定性(副作用)により、それを安定させるために薬Bを追加する必要があります。しかし、この新しい追加はシームレスに統合されない可能性があり、塔がさらに傾く原因となります(Bの副作用)。この不安定性を修正するために、さらに多くのブロック(薬C、Dなど)が追加され、塔の不安定性と崩壊の可能性を悪化させます。これは、複数の薬から生じる潜在的な健康上の合併症を表しています。

意図/エンティティベースのNLUのもう一つの分かりやすい比喩は、ブロックの塔を建てることです
同様に、NLUシステムに新しい意図が追加されるたびに、比喩的なブロックの塔は高くなり、不安定性が増します。補強の必要性が高まり、メンテナンスコストが増加します。その結果、意図/エンティティベースのNLUは、プロバイダーにとっては最初は魅力的に見えるかもしれませんが、実際にはクライアントが維持するには過度に負担になります。これらのシステムはスケーラビリティに欠け、プロバイダーとクライアントの両方にとって重大な課題を提起します。 次のセクションでは、GenAI/LLMベースのNLUがこれらの課題に効果的に対処するための、より持続可能でスケーラブルな代替手段をどのように提供するかを探ります。
GenAI/LLMベースのNLU:回復力のあるソリューション
GenAI/LLMベースのNLUは、意図/エンティティベースのシステムが直面するスケーラビリティの課題に対する堅牢なソリューションを提供します。これは主に2つの主要な要因に起因します。
-
事前学習と世界知識: GenAI/LLMモデルは大量のデータで事前学習されており、豊富な世界知識を継承できます。この蓄積された知識は、さまざまな意図を識別する上で重要な役割を果たし、それによって否定的な例に対するモデルの識別能力を高めます。
-
Few-Shot学習: GenAI/LLMベースのNLUの際立った特徴の1つは、Few-Shot学習技術を使用できることです。各意図に広範なトレーニングデータを必要とする従来のメソッドとは異なり、Few-Shot学習により、モデルはわずかな例から学習できます。この効率的な学習アプローチは、最小限のデータで意図された目標を強化し、トレーニングの負担を大幅に軽減します。
このシナリオを考えてみましょう。「今日の天気はどうですか?」というクエリを読者として提示されたとき、あなたは本能的にそれを、毎日遭遇する多数の文の中から天気に関する問い合わせとして認識します。意図を識別するこの生来の能力は、Few-Shot学習の概念に似ています。
大人として、私たちの脳は膨大な語彙で事前学習されており、20歳までに約1億5000万語と推定されています。この広範な言語への露出により、新しい意図に遭遇したときにすぐに理解でき、強化のためにわずかな例しか必要としません。
Urban Dictionaryは、Few-Shot学習の実際の例を探求するための優れたリソースとして機能し、迅速な理解を促進する上でのその有効性をさらに示しています。
GenAI/LLMベースのNLUに内在するFew-Shot学習機能は、コスト削減とスケーラビリティの実現に不可欠です。事前学習中にトレーニングの大部分がすでに完了しているため、最小限の例でモデルを微調整することが主な焦点となり、プロセスを合理化し、スケーラビリティを向上させます。
GenAI/LLMベースのNLU:結果と証拠の提供
2024年3月現在、自然言語処理(NLP)の状況は、GenAI/LLMベースのNLUの登場により大きく変化しました。かつて支配的だったNLPイノベーションの進歩は、最先端の進歩の停滞が示すように、過去2〜3年間で停滞しています。かつて最も注目されていたNLPの進捗状況を最先端の状況で確認すると、ほとんどが2〜3年前に停止しています。
以前は、このGithubリポジトリでNLPのイノベーションを追跡していました。更新はほとんど2〜3年前に停止しました。
このパラダイムシフトを裏付ける注目すべきベンチマークの1つは、2022年12月に最新のエントリが追加されたSuperGlueリーダーボードです。興味深いことに、この期間はChatGPT(3.5)の導入と一致しており、NLPコミュニティ全体に衝撃を与えました。
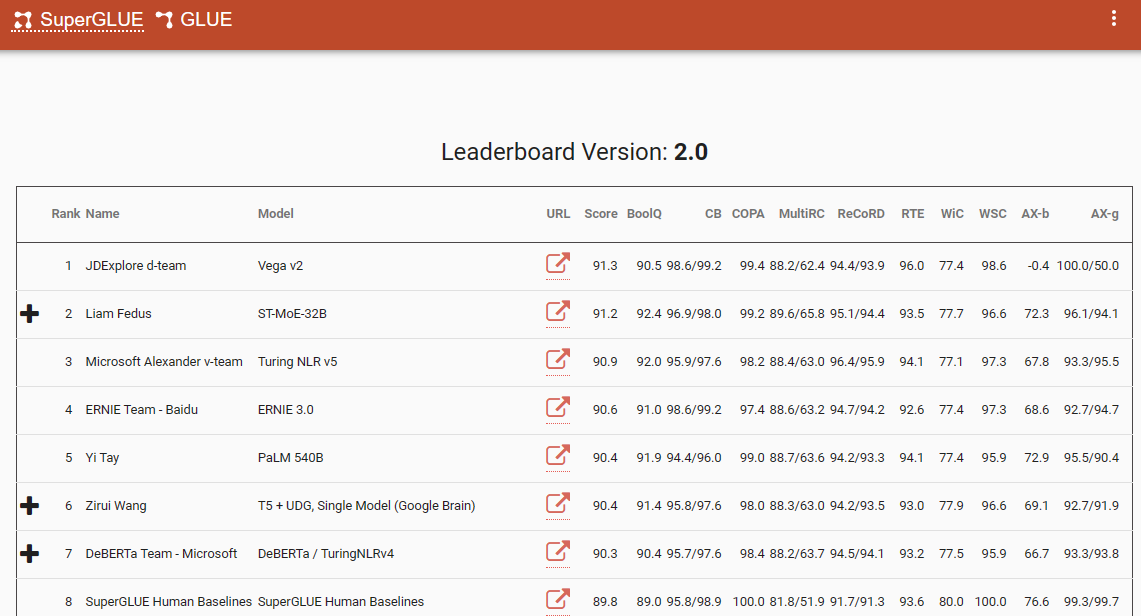
SuperGlueリーダーボードはChatGPTの導入まで人気がありました
画期的なGPT-3論文「言語モデルはFew-Shot学習者である」は、Few-Shot学習の有効性を示す説得力のある証拠を提供しています。論文の7ページの図2.1は、ゼロショット、ワンショット、Few-Shot学習アプローチの違いを明確にし、学習効率と有効性の点で後者の優位性を強調しています。

ゼロショット、ワンショット、Few-Shot学習アプローチの違い
さらに、GenAI/LLMベースのNLUの有効性を裏付けるのは、19ページの表3.8です。この表は、従来の教師ありNLUメソッドとGPT-3 Few-Shot学習の直接比較を提供しています。この比較では、GPT-3 Few-Shotは、意図/エンティティベースのNLUシステムで採用されている教師あり学習の代表であるFine-tuned BERT-Largeを、さまざまなタスクで上回っています。
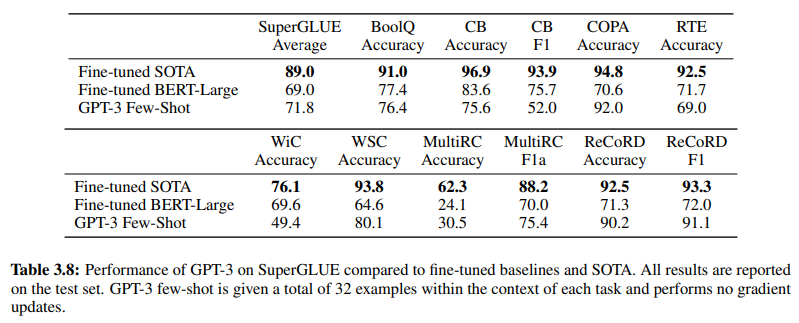
GPT-3 Few-Shotは、さまざまなタスクでFine-tuned BERT-Largeを上回っています
GPT-3 Few-Shotの優位性は、その精度だけでなく、コスト効率にも明らかです。GenAI/LLMベースのNLUに関連する初期設定費用とメンテナンス費用は、従来のメソッドと比較して大幅に低くなっています。
NLPコミュニティで提示された経験的証拠は、GenAI/LLMベースのNLUの変革的な影響を強調しています。それはすでに比類のない精度と効率性を示しています。次に、その費用対効果を確認しましょう。
トレーニングデータ要件:比較分析
意図/エンティティベースのNLUとGenAI/LLMベースのNLUの間の明らかな比較は、それらの異なるトレーニングデータ要件を明らかにします。20ページの図3.8は、顕著な対比を示しています。
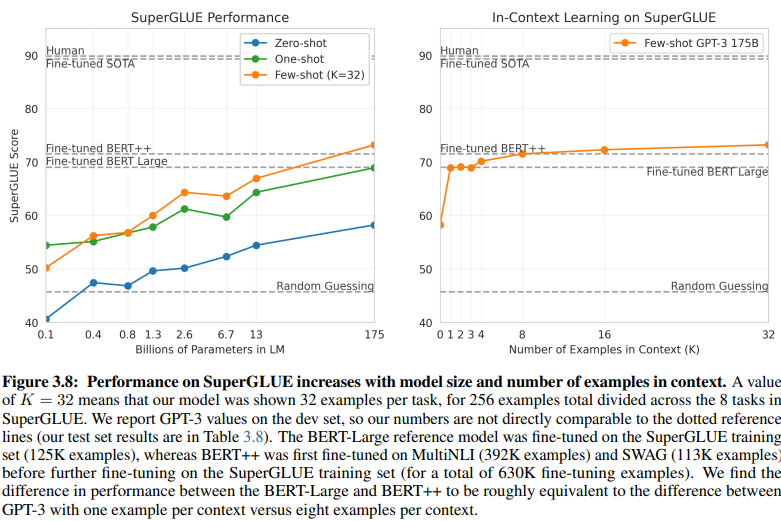
GenAI/LLMベースのNLUは、トレーニングに必要なデータがはるかに少ない
-
教師あり学習NLU: この従来のアプローチでは、効果的なトレーニングのために50万以上の例(630K)が必要な広範なデータセットが必要です。
-
Few-Shot GPT-3: 対照的に、GenAI/LLMベースのNLUは、タスクごとにわずか32の例で効果的なチューニングに十分であり、驚くべき効率性を示しています。この効率的な学習アプローチは、最小限のデータで意図された目標を強化し、トレーニングの負担を大幅に軽減します。
この違いの大きさは驚くべきものです。630,000の例に対してわずか32。トレーニングデータ要件のこの劇的な削減は、GenAI/LLMベースのNLUを採用する企業にとって大幅なコスト削減につながります。
さらに、開発タイムラインへの暗示的な影響は深遠です。GenAI/LLMベースのNLUでは、短縮されたトレーニングプロセスにより、NLUシステムの展開が複数の桁で加速され、自然言語処理の分野での迅速な適応と革新が促進されます。
本質的に、この比較は、GenAI/LLMベースのNLUの変革的な可能性を強調しており、トレーニングデータ要件と開発タイムラインにおいて比類のない効率性とコスト効率を提供します。
進化を受け入れる:GenAI/LLMベースのNLUが優勢である理由
自然言語理解の分野では、意図/エンティティベースのシステムからGenAI/LLMベースのソリューションへの移行が議論の余地なく進行中です。この変化は、従来の意図/エンティティベースのNLUの限界と、GenAI/LLMベースのアプローチが提供する説得力のある利点を強調する多数の要因によって推進されています。
意図/エンティティベースのNLUは、いくつかの説得力のある理由から、ますます時代遅れと見なされています。
-
限られた柔軟性: 従来のNLUシステムは、事前定義された意図とエンティティに依存しており、これらの事前定義されたカテゴリから逸脱するユーザー入力に対するチャットボットとIVRの適応性を制限します。
-
メンテナンスの課題: これらのシステムがスケールし、意図とエンティティの数が増えるにつれて、メンテナンスと更新に必要な複雑さと時間が指数関数的に増加します。
-
コンテキスト理解の欠如: これらのシステムは、会話の複雑なコンテキストのニュアンスを把握するのに失敗することが多く、不正確な応答や意図を明確にするための追加のユーザー入力の必要性につながります。
-
生成の欠如: 意図およびエンティティベースのNLUシステムは、テキストを生成する能力が本質的に制限されており、意図の分類とエンティティの抽出を中心としたタスクに限定されます。これにより、チャットボットとIVRの適応性が制限され、会話のコンテキストと一致しない単調な応答につながることがよくあります。
対照的に、GenAI/LLMベースのNLUは、その変革的な属性により、主要なトレンドとして浮上しています。
-
適応学習: GenAIモデルは、リアルタイムの会話から動的に学習する能力を持っており、手動での更新を必要とせずに、新しいトピックやユーザーの行動に自律的に適応できます。
-
コンテキスト理解: これらのモデルは、会話の複雑なコンテキストのニュアンスを理解することに優れており、ユーザーに響くより正確で関連性の高い応答につながります。
-
Few-Shot学習: GenAIモデルは最小限の例でトレーニングできるため、トレーニングプロセスが合理化され、明示的な意図とエンティティの定義への依存が軽減されます。
-
自然言語生成: GenAI/LLMはテキストを生成する能力を誇り、自然でコンテキストに関連する応答を提供するチャットボットやその他のNLPアプリケーションを作成できます。
会話型AIの未来は、有機的に学習し適応できるシステムにかかっており、ユーザーにシームレスで直感的な体験を提供します。GenAI/LLMベースのNLUは、この進化を体現しており、従来の意図/エンティティベースのシステムの制約を超えた動的で柔軟なアプローチを提供します。
本質的に、NLUの主要な軌跡は、GenAI/LLMベースのアプローチの優位性によって明確に定義されており、適応性、コンテキスト性、ユーザー中心性を優先する会話型AIの新時代を告げています。


