




致所有客戶服務或行銷總監,如果您的老闆問您以下問題,請將此文章發送給他們:
“為什麼基於意圖/實體的 NLU 已經過時,而基於 LLM/GenAI 的 NLU 是顯而易見的趨勢?”
自然語言理解 (NLU) 系統旨在處理和分析自然語言輸入,例如文本或語音,以提取含義、提取相關信息並理解通信背後的潛在意圖。NLU 是各種 AI 應用程式的基本組成部分,包括虛擬助手、聊天機器人、情感分析工具、語言翻譯系統等。它在實現人機交互和促進能夠理解和響應自然語言輸入的智能系統開發方面發揮著關鍵作用。
這個問題來自那些正在重新思考其 IVR 和聊天機器人方法的成熟客戶。他們被鎖定在上一代基於 NLU 的技術棧中,這些技術棧通常由大型科技公司提供,例如:Microsoft Bot Framework(或 luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU。
挑戰在於,保險公司、金融機構、政府、航空公司/汽車經銷商等主要客戶已經部署了上一代技術。但由於基於意圖/實體的 NLU 無法擴展,客戶每年必須花費數十萬到數百萬美元來維護和升級其 NLU 系統。這種缺乏可擴展性導致維護成本不斷上升,最終以犧牲客戶為代價,使上一代 NLU 提供商受益。由於它們無法擴展,維護成本逐年增加。
為什麼基於意圖/實體的 NLU 無法有效擴展?
主要原因在於模型有限的判別能力。以下是原因的細分:
-
最小意圖要求:NLU 模型需要至少兩個不同的意圖才能有效訓練。例如,當詢問天氣時,意圖可能很明確,但每個查詢背後都有多個潛在意圖,例如回退或與天氣無關的查詢,例如“你好嗎?”
-
訓練數據需求:大型科技公司通常要求每個意圖提供數千個正面示例才能進行有效訓練。這種廣泛的數據集對於模型準確學習和區分不同意圖是必要的。
-
平衡正面和負面示例:向一個意圖添加正面示例需要為其他意圖包含負面示例。這種平衡的方法確保 NLU 模型可以有效地從正面和負面實例中學習。
-
多樣化的示例集:正面和負面示例都必須多樣化,以防止過擬合併增強模型在不同上下文中泛化的能力。
-
添加新意圖的複雜性:向現有 NLU 模型添加新意圖涉及一個繁瑣的過程。必須添加數千個正面和負面示例,然後重新訓練模型以保持其基線性能。隨著意圖數量的增加,此過程變得越來越具有挑戰性。
處方效應:基於意圖/實體 NLU 的陷阱

基於意圖/實體 NLU 的處方效應
類似於醫學中被稱為「處方級聯」的現象,基於意圖/實體的 NLU 的可擴展性挑戰可以比作令人望而生畏的處方級聯。想像一位老年人背負著大量日常藥物,每種藥物都是為了解決前一種藥物副作用而開的。這種情景太常見了,藥物 A 的引入導致副作用,需要開藥物 B 來抵消它們。然而,藥物 B 又引入了自己的一系列副作用,從而需要藥物 C,依此類推。因此,老年人發現自己被管理著堆積如山的藥片——一個處方級聯。
另一個形象的比喻是建造一座積木塔,每個積木代表一種藥物。最初,藥物 A 被放置,但其不穩定性(副作用)促使添加藥物 B 來穩定它。然而,這種新添加可能無法無縫集成,導致塔進一步傾斜(B 的副作用)。為了糾正這種不穩定性,添加了更多的積木(藥物 C、D 等),從而加劇了塔的不穩定性和倒塌的脆弱性——這代表了多種藥物可能引起的健康併發症。

基於意圖/實體 NLU 的另一個形象比喻是建造一座積木塔
同樣,隨著 NLU 系統中添加的每個新意圖,比喻性的積木塔會越來越高,增加不穩定性。對強化的需求不斷升級,導致更高的維護成本。因此,雖然基於意圖/實體的 NLU 最初可能對提供商有吸引力,但現實是它對客戶來說維護成本過高。這些系統缺乏可擴展性,給提供商和客戶都帶來了重大挑戰。 在接下來的部分中,我們將探討基於 GenAI/LLM 的 NLU 如何提供更可持續和可擴展的替代方案,以有效解決這些挑戰。
基於 GenAI/LLM 的 NLU:彈性解決方案
基於 GenAI/LLM 的 NLU 為基於意圖/實體的系統所面臨的可擴展性挑戰提供了強大的解決方案。這主要歸因於兩個關鍵因素:
-
預訓練和世界知識:GenAI/LLM 模型在大量數據上進行預訓練,使它們能夠繼承豐富的世界知識。這種累積的知識在區分各種意圖方面發揮著關鍵作用,從而增強了模型對抗負面示例的判別能力。
-
少樣本學習:基於 GenAI/LLM 的 NLU 的一個顯著特點是它能夠採用少樣本學習技術。與需要大量訓練數據才能實現每個意圖的傳統方法不同,少樣本學習使模型能夠僅從幾個示例中學習。這種高效的學習方法以最少的數據強化了預期目標,顯著降低了訓練負擔。
考慮這個場景:當您作為讀者被問到「今天天氣怎麼樣?」時,您會本能地將其識別為關於天氣的詢問,而不是每天遇到的眾多句子中的一個。這種識別意圖的內在能力類似於少樣本學習的概念。
作為成年人,我們的大腦經過大量詞彙的預訓練,估計到 20 歲時詞彙量約為 1.5 億。這種廣泛的語言接觸使我們能夠快速掌握新意圖,只需少量示例即可進行強化。
Urban Dictionary 是探索少樣本學習實際應用示例的絕佳資源,進一步說明了其在促進快速理解方面的有效性。
基於 GenAI/LLM 的 NLU 中固有的少樣本學習能力對於降低成本和實現可擴展性至關重要。由於大部分訓練已在預訓練期間完成,因此使用最少數量範例對模型進行微調成為主要焦點,從而簡化了流程並提高了可擴展性。
基於 GenAI/LLM 的 NLU:提供結果和證據
截至 2024 年 3 月,自然語言處理 (NLP) 領域發生了重大轉變,以基於 GenAI/LLM 的 NLU 的出現為標誌。NLP 創新中曾經佔據主導地位的進展在過去 2-3 年中停滯不前,這從最先進技術進展的停滯中可見一斑。如果您查看曾經最熱門的 NLP 進展,就會發現它在 2-3 年前就基本停止了:
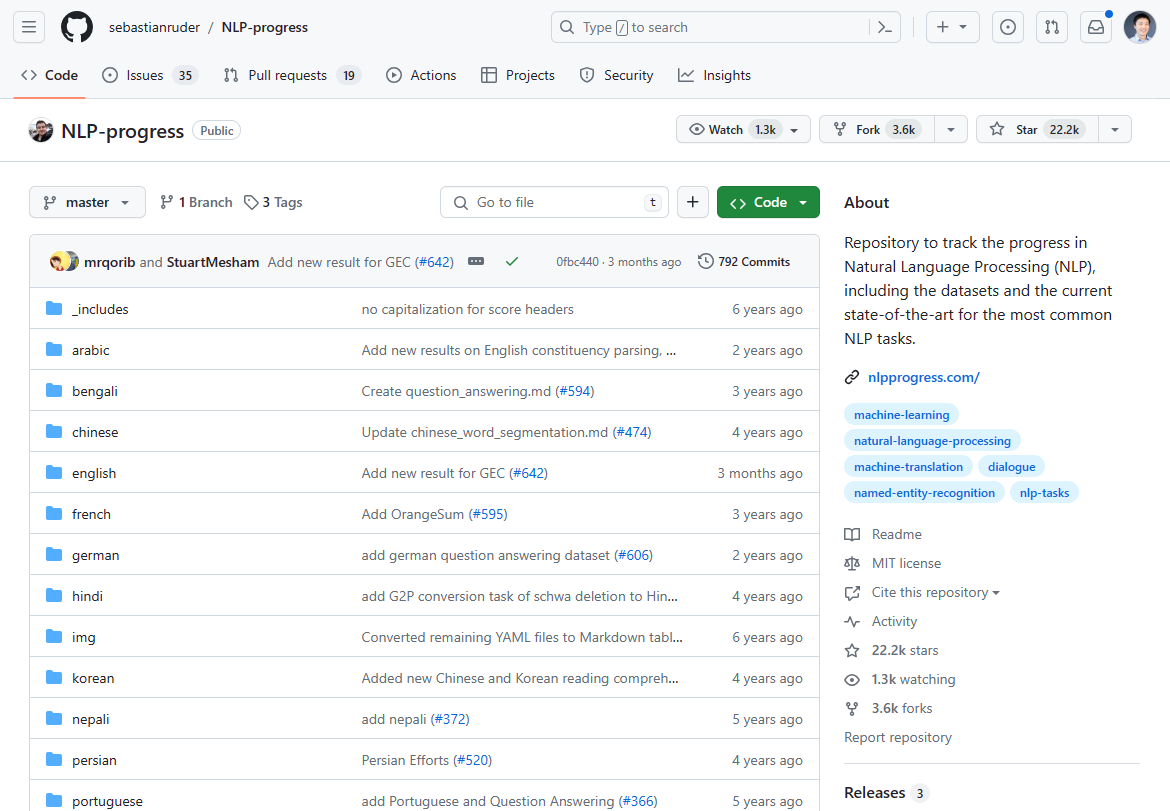
我們曾經在這個 Github 倉庫中追蹤 NLP 創新。更新在 2-3 年前就基本停止了。
一個值得注意的基準,強調了這種範式轉變的是 SuperGlue 排行榜,其最新條目在 2022 年 12 月。有趣的是,這個時間框架與 ChatGPT (3.5) 的引入相吻合,後者在整個 NLP 社區引起了轟動。
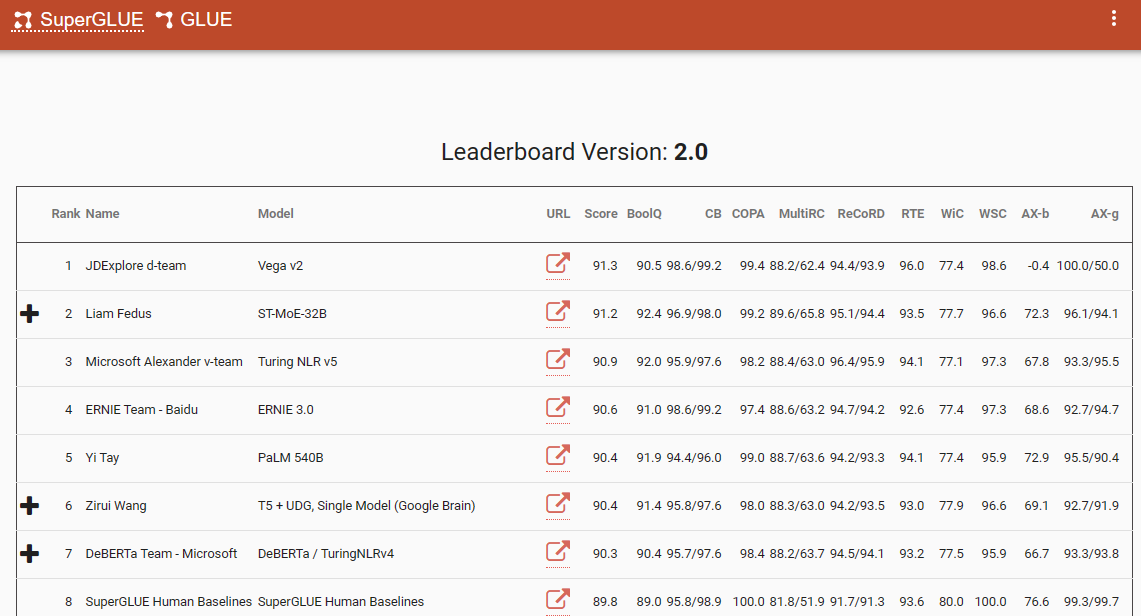
SuperGlue 排行榜在 ChatGPT 引入之前很受歡迎
開創性的 GPT-3 論文,恰當地命名為「語言模型是少樣本學習者」,提供了少樣本學習有效性的令人信服的證據。論文第 7 頁的圖 2.1 描繪了零樣本、單樣本和少樣本學習方法之間的區別,強調了後者在學習效率和有效性方面的優越性。

零樣本、單樣本和少樣本學習方法之間的區別
此外,為證實基於 GenAI/LLM 的 NLU 的有效性,第 19 頁的表 3.8 直接比較了傳統的監督式 NLU 方法和 GPT-3 少樣本學習。在此比較中,GPT-3 少樣本在各種任務中都超越了 Fine-tuned BERT-Large,後者是基於意圖/實體的 NLU 系統所採用的監督式學習的代表。
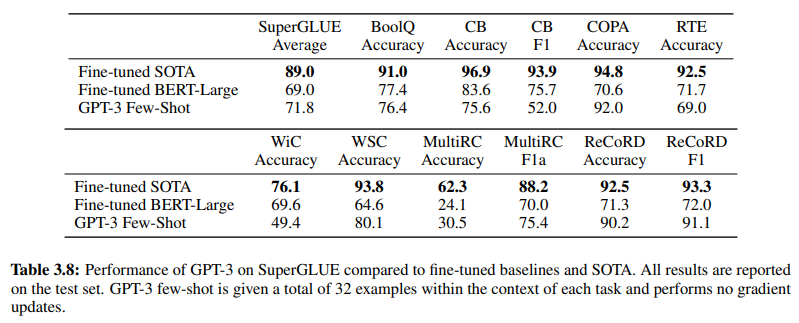
GPT-3 少樣本在各種任務中超越了 Fine-tuned BERT-Large
GPT-3 少樣本的優越性不僅體現在其準確性上,還體現在其成本效益上。與傳統方法相比,基於 GenAI/LLM 的 NLU 的初始設置和維護成本都顯著降低。
NLP 社區中提供的經驗證據強調了基於 GenAI/LLM 的 NLU 的變革性影響。它已經展示了其無與倫比的準確性和效率。接下來,讓我們檢查其成本效益。
訓練數據要求:比較分析
基於意圖/實體的 NLU 和基於 GenAI/LLM 的 NLU 之間的一個揭示性比較揭示了它們不同的訓練數據要求。第 20 頁的圖 3.8 呈現出鮮明的對比:
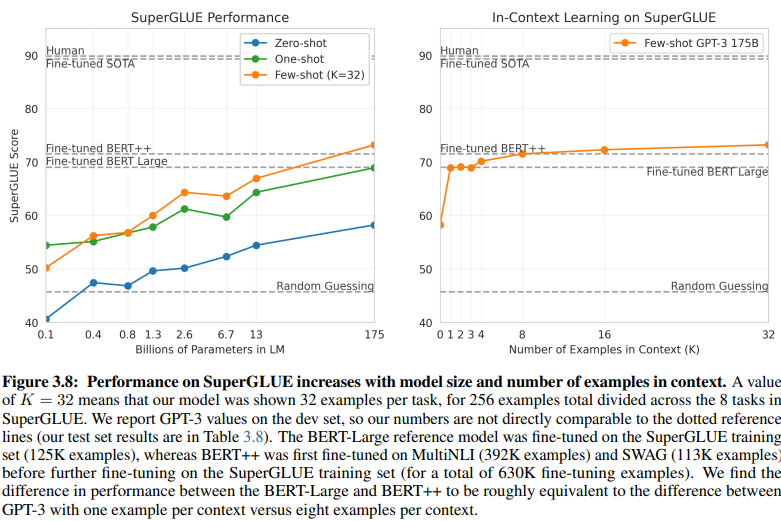
基於 GenAI/LLM 的 NLU 訓練所需數據量少得多
-
監督學習 NLU:這種傳統方法需要大量數據集,有效訓練需要超過五十萬個範例 (630K)。
-
少樣本 GPT-3:相比之下,基於 GenAI/LLM 的 NLU 表現出卓越的效率,每個任務只需 32 個範例即可有效微調。
這種差異的 magnitud 令人震驚:630,000 個範例與僅僅 32 個。訓練數據需求的這種急劇減少為採用基於 GenAI/LLM 的 NLU 的企業帶來了顯著的成本節約。
此外,對開發時間表的隱含影響是深遠的。借助基於 GenAI/LLM 的 NLU,縮短的訓練過程將 NLU 系統的部署速度提高了多個數量級,從而促進了自然語言處理領域的快速適應和創新。
本質上,這種比較強調了基於 GenAI/LLM 的 NLU 的變革潛力,在訓練數據需求和開發時間表方面提供了無與倫比的效率和成本效益。
擁抱進化:為什麼基於 GenAI/LLM 的 NLU 盛行
在自然語言理解領域,從基於意圖/實體的系統向基於 GenAI/LLM 的解決方案的轉變正在毫無疑問地進行中。這種轉變是由眾多因素推動的,這些因素強調了傳統基於意圖/實體的 NLU 的局限性以及基於 GenAI/LLM 的方法所提供的令人信服的優勢。
基於意圖/實體的 NLU 越來越被認為是過時的,原因有幾個令人信服:
-
有限的靈活性:傳統的 NLU 系統依賴於預定義的意圖和實體,這限制了聊天機器人與 IVR 對偏離這些預定義類別的用戶輸入的適應性。
-
維護挑戰:隨著這些系統的擴展以及意圖和實體數量的激增,維護和更新所需的複雜性和時間呈指數級增長。
-
缺乏上下文理解:這些系統通常無法理解對話中複雜的上下文細微差別,導致不準確的響應或需要額外的用戶輸入來澄清意圖。
-
缺乏生成能力:基於意圖和實體的 NLU 系統在生成文本的能力上固有地受到限制,這使得它們僅限於圍繞意圖分類和實體提取的任務。這限制了聊天機器人與 IVR 的適應性,通常導致單調的響應,無法與對話上下文保持一致。
相比之下,基於 GenAI/LLM 的 NLU 因其變革性屬性而成為主流趨勢:
-
自適應學習:GenAI 模型具有從實時對話中動態學習的能力,使它們能夠自主適應新主題和用戶行為,而無需手動更新。
-
上下文理解:這些模型擅長理解對話中複雜的上下文細微差別,從而產生更準確和相關的響應,與用戶產生共鳴。
-
少樣本學習:GenAI 模型可以用最少的範例進行訓練,從而簡化訓練過程並減少對顯式意圖和實體定義的依賴。
-
自然語言生成:GenAI/LLM 擁有生成文本的能力,使它們能夠創建聊天機器人和其他 NLP 應用程式,提供自然且上下文相關的響應。
對話式 AI 的未來取決於能夠有機地學習和適應的系統,為用戶提供無縫和直觀的體驗。基於 GenAI/LLM 的 NLU 體現了這一演變,提供了一種動態靈活的方法,超越了傳統基於意圖/實體的系統的限制。
本質上,NLU 的主要軌跡無疑是由基於 GenAI/LLM 的方法的興起所定義的,預示著一個以適應性、上下文性和以用戶為中心為優先的對話式 AI 新時代。