





Sa lahat ng Direktor ng Customer Service o Marketing, kung tatanungin kayo ng inyong boss ng sumusunod na tanong, ipadala sa kanila ang artikulong ito:
“Bakit luma na ang NLU na batay sa intensyon/entity at bakit ang LLM/GenAI ang malinaw na trend?”
Ang mga sistema ng Natural Language Understanding (NLU) ay naglalayong iproseso at suriin ang mga input ng natural na wika, tulad ng text o speech, upang makakuha ng kahulugan, makakuha ng mga nauugnay na impormasyon, at maunawaan ang pinagbabatayan na intensyon sa likod ng komunikasyon. Ang NLU ay isang pangunahing bahagi ng iba’t ibang aplikasyon ng AI, kabilang ang mga virtual assistant, chatbot, tool sa pagsusuri ng damdamin, sistema ng pagsasalin ng wika, at marami pa. Malaki ang papel nito sa pagpapagana ng interaksyon ng tao-computer at pagpapadali sa pagbuo ng mga intelligent na sistema na may kakayahang maunawaan at tumugon sa mga input ng natural na wika.
Ang tanong na ito ay nagmula sa mga itinatag na kliyente na muling nag-iisip ng kanilang IVR at chatbot approach. Sila ay nakakulong sa nakaraang henerasyon ng NLU-based tech stack, na karaniwang inaalok ng mga malalaking tech player tulad ng: Microsoft Bot Framework (o luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
Ang hamon ay ang mga pangunahing kliyente tulad ng mga kumpanya ng seguro, institusyong pinansyal, gobyerno, airline/car dealership, at iba pang malalaking deal ay na-deploy na ang teknolohiya ng nakaraang henerasyon. Ngunit dahil ang NLU na batay sa intensyon/entity ay hindi scalable, ang mga kliyente ay kailangang gumastos ng daan-daang libo hanggang milyun-milyong dolyar bawat taon upang mapanatili at i-upgrade ang kanilang NLU system. Ang kakulangan ng scalability na ito ay nag-aambag sa pagtaas ng mga gastos sa pagpapanatili, na sa huli ay nakikinabang sa mga provider ng NLU ng nakaraang henerasyon sa kapinsalaan ng kanilang mga kliyente. Dahil hindi sila nag-i-scale, mas mataas ang gastos sa pagpapanatili taon-taon.
Bakit hindi epektibong nag-i-scale ang NLU na batay sa intensyon/entity?
Ang pangunahing dahilan ay nasa limitadong kapangyarihan ng diskriminasyon ng modelo. Narito ang isang paglalahad kung bakit ito ang kaso:
-
Minimum Intents Requirement: Ang mga modelo ng NLU ay nangangailangan ng hindi bababa sa dalawang magkakaibang intensyon upang epektibong masanay. Halimbawa, kapag nagtatanong tungkol sa panahon, maaaring malinaw ang intensyon, ngunit sa ilalim ng bawat query ay may maraming potensyal na intensyon, tulad ng isang fallback o mga katanungan na hindi nauugnay sa panahon tulad ng “kumusta ka?”
-
Pangangailangan sa Data ng Pagsasanay: Karaniwang nangangailangan ang mga malalaking kumpanya ng teknolohiya ng libu-libong positibong halimbawa bawat intensyon para sa epektibong pagsasanay. Ang malawak na dataset na ito ay kinakailangan para matuto ang modelo at makilala nang tumpak ang iba’t ibang intensyon.
-
Pagbalanse ng Positibo at Negatibong Halimbawa: Ang pagdaragdag ng mga positibong halimbawa sa isang intensyon ay nangangailangan ng pagsasama ng mga negatibong halimbawa para sa iba pang mga intensyon. Ang balanseng pamamaraang ito ay nagsisiguro na ang modelo ng NLU ay maaaring matuto nang epektibo mula sa parehong positibo at negatibong mga pagkakataon.
-
Iba’t ibang Set ng Halimbawa: Ang parehong positibo at negatibong halimbawa ay dapat na magkakaiba upang maiwasan ang overfitting at mapahusay ang kakayahan ng modelo na mag-generalize sa iba’t ibang konteksto.
-
Pagiging Kumplikado ng Pagdaragdag ng Bagong Intensyon: Ang pagdaragdag ng bagong intensyon sa isang umiiral na modelo ng NLU ay nagsasangkot ng isang masusing proseso. Libu-libong positibo at negatibong halimbawa ang dapat idagdag, na susundan ng muling pagsasanay ng modelo upang mapanatili ang baseline performance nito. Ang proses na ito ay nagiging lalong mahirap habang lumalaki ang bilang ng mga intensyon.
Ang Epekto ng Pagrereseta: Ang Bitag ng NLU na Batay sa Intensyon/Entity

Ang Epekto ng Pagrereseta ng NLU na batay sa Intensyon/Entity
Katulad ng phenomenon sa medisina na kilala bilang “prescribing cascade,” ang mga hamon sa scalability ng NLU na batay sa intensyon/entity ay maaaring ihambing sa isang nakakatakot na kaskad ng mga reseta. Isipin ang isang matandang indibidwal na nabibigatan ng napakaraming pang-araw-araw na gamot, bawat isa ay inireseta upang matugunan ang mga side effect ng nauna. Ang senaryong ito ay masyadong pamilyar, kung saan ang pagpapakilala ng Gamot A ay humahantong sa mga side effect na nangangailangan ng reseta ng Gamot B upang kontrahin ang mga ito. Gayunpaman, ang Gamot B ay nagpapakilala ng sarili nitong hanay ng mga side effect, na nagtutulak sa pangangailangan para sa Gamot C, at iba pa. Dahil dito, ang matandang tao ay nalulunod sa isang bundok ng mga pildoras na dapat pamahalaan—isang prescribing cascade.
Ang isa pang naglalarawang metapora ay ang pagbuo ng isang tore ng mga bloke, kung saan ang bawat bloke ay kumakatawan sa isang gamot. Sa simula, inilalagay ang Gamot A, ngunit ang kawalang-tatag nito (mga side effect) ay nagtutulak sa pagdaragdag ng Gamot B upang patatagin ito. Gayunpaman, ang bagong karagdagan na ito ay maaaring hindi maging maayos na isinama, na nagiging sanhi ng pagtagilid ng tore (side effect ng B). Sa pagsisikap na itama ang kawalang-tatag na ito, mas maraming bloke (Gamot C, D, atbp.) ang idinagdag, na nagpapalala sa kawalang-tatag ng tore at pagiging madaling gumuho—isang representasyon ng mga potensyal na komplikasyon sa kalusugan na nagmumula sa maraming gamot.

Ang isa pang naglalarawang metapora para sa NLU na batay sa intensyon/entity ay ang pagbuo ng isang tore ng mga bloke
Katulad nito, sa bawat bagong intensyon na idinagdag sa isang sistema ng NLU, ang metaporikal na tore ng mga bloke ay lumalaki, na nagpapataas ng kawalang-tatag. Ang pangangailangan para sa pagpapatibay ay tumataas, na nagreresulta sa mas mataas na gastos sa pagpapanatili. Dahil dito, bagama’t ang NLU na batay sa intensyon/entity ay maaaring mukhang kaakit-akit sa mga provider sa simula, ang katotohanan ay nagiging labis itong pabigat para sa mga kliyente na panatilihin. Ang mga sistemang ito ay kulang sa scalability, na nagdudulot ng malalaking hamon para sa parehong mga provider at kliyente. Sa mga susunod na seksyon, susuriin natin kung paano nag-aalok ang NLU na batay sa GenAI/LLM ng mas napapanatili at nasusukat na alternatibo upang epektibong matugunan ang mga hamong ito.
NLU na batay sa GenAI/LLM: Isang Matatag na Solusyon
Nag-aalok ang NLU na batay sa GenAI/LLM ng matatag na solusyon sa mga hamon sa scalability na kinakaharap ng mga sistemang batay sa intensyon/entity. Ito ay pangunahing iniuugnay sa dalawang pangunahing salik:
-
Pre-Training at Kaalaman sa Mundo: Ang mga modelo ng GenAI/LLM ay sinasanay nang pauna sa napakaraming data, na nagpapahintulot sa kanila na magmana ng maraming kaalaman sa mundo. Ang naipong kaalaman na ito ay gumaganap ng isang mahalagang papel sa pagkilala sa pagitan ng iba’t ibang intensyon, sa gayon ay nagpapahusay sa mga kakayahan ng diskriminasyon ng modelo laban sa mga negatibong halimbawa.
-
Few-Shot Learning: Isa sa mga pangunahing tampok ng NLU na batay sa GenAI/LLM ay ang kakayahan nitong gumamit ng mga teknik ng few-shot learning. Hindi tulad ng tradisyonal na pamamaraan na nangangailangan ng malawak na data ng pagsasanay para sa bawat intensyon, ang few-shot learning ay nagbibigay-daan sa modelo na matuto mula sa iilang halimbawa lamang. Ang mahusay na pamamaraang ito ng pag-aaral ay nagpapatibay sa mga nilalayon na layunin na may kaunting data, na makabuluhang nagpapababa sa pasanin ng pagsasanay.
Isaalang-alang ang senaryong ito: kapag ipinakita ang query na “Ano ang panahon ngayon?” bilang isang mambabasa, likas mong kinikilala ito bilang isang katanungan tungkol sa panahon sa gitna ng maraming pangungusap na nakakaharap araw-araw. Ang likas na kakayahang ito na makilala ang intensyon ay katulad ng konsepto ng few-shot learning.
Bilang mga matatanda, ang ating utak ay sinanay na may malawak na bokabularyo, na tinatayang nasa 150 milyong salita sa edad na 20. Ang malawak na pagkakalantad sa wika na ito ay nagbibigay-daan sa atin na mabilis na maunawaan ang mga bagong intensyon sa pagkakita sa kanila, na nangangailangan lamang ng ilang halimbawa para sa pagpapatibay.
Ang Urban Dictionary ay nagsisilbing isang mahusay na mapagkukunan para sa paggalugad ng mga halimbawa ng few-shot learning sa aksyon, na higit pang naglalarawan ng pagiging epektibo nito sa pagpapadali ng mabilis na pag-unawa.
Ang kakayahan ng few-shot learning na likas sa NLU na batay sa GenAI/LLM ay mahalaga sa pagbabawas ng mga gastos at pagpapagana ng scalability. Sa karamihan ng pagsasanay na nakumpleto na sa panahon ng pre-training, ang fine-tuning ng modelo na may kaunting bilang ng mga halimbawa ang nagiging pangunahing pokus, na nagpapabilis sa proseso at nagpapahusay sa scalability.
NLU na batay sa GenAI/LLM: Paghahatid ng mga Resulta at Ebidensya
Simula Marso 2024, ang landscape ng natural language processing (NLP) ay sumailalim sa isang makabuluhang pagbabago, na minarkahan ng paglitaw ng NLU na batay sa GenAI/LLM bilang isang game-changer. Ang dating nangingibabaw na pag-unlad sa NLP innovation ay nag-plateau sa nakalipas na 2-3 taon, tulad ng pinatunayan ng stagnation sa state-of-the-art advancements. Kung susuriin mo ang dating pinakamainit na pag-unlad ng NLP para sa state of the art, ito ay halos huminto 2-3 taon na ang nakalipas:
Dati naming sinusubaybayan ang NLP innovation sa Github Repo na ito. Ang update ay halos huminto 2-3 taon na ang nakalipas.
Isang kapansin-pansing benchmark na nagpapatunay sa pagbabagong ito ng paradigma ay ang SuperGlue leaderboard, na may pinakabagong entry noong Disyembre 2022. Kapansin-pansin, ang time frame na ito ay kasabay ng pagpapakilala ng ChatGPT (3.5), na nagdulot ng pagkabigla sa komunidad ng NLP.
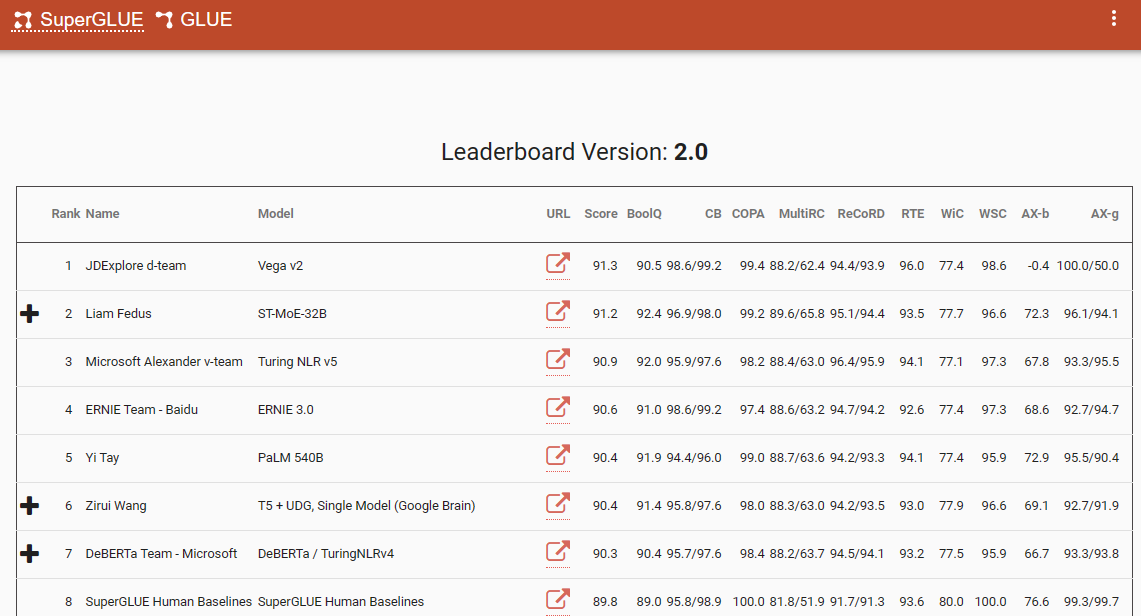
Sikat ang SuperGlue leaderboard hanggang sa pagpapakilala ng ChatGPT
Ang seminal na papel ng GPT-3, na may angkop na pamagat na “Ang mga Modelo ng Wika ay Few-Shot Learners”, ay nag-aalok ng nakakumbinsing ebidensya ng pagiging epektibo ng few-shot learning. Ang Figure 2.1 sa pahina 7 ng papel ay naglalarawan ng mga pagkakaiba sa pagitan ng zero-shot, one-shot, at few-shot learning approaches, na nagbibigay-diin sa kahusayan ng huli sa mga tuntunin ng kahusayan at pagiging epektibo ng pag-aaral.

Ang mga pagkakaiba sa pagitan ng zero-shot, one-shot, at few-shot learning approaches
Higit pa rito, pinatutunayan ang pagiging epektibo ng NLU na batay sa GenAI/LLM ay ang Table 3.8 sa pahina 19, na nagbibigay ng direktang paghahambing sa pagitan ng tradisyonal na supervised NLU methods at GPT-3 Few-Shot learning. Sa paghahambing na ito, nalampasan ng GPT-3 Few-Shot ang Fine-tuned BERT-Large, isang representasyon ng supervised learning na ginagamit ng mga NLU system na batay sa intensyon/entity, sa iba’t ibang gawain.
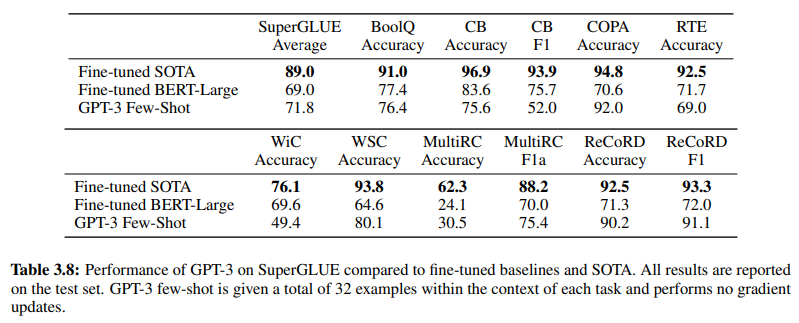
Nalampasan ng GPT-3 Few-Shot ang Fine-tuned BERT-Large sa iba’t ibang gawain
Ang kahusayan ng GPT-3 Few-Shot ay hindi lamang maliwanag sa katumpakan nito kundi pati na rin sa pagiging cost-effective nito. Ang parehong paunang pag-setup at mga gastos sa pagpapanatili na nauugnay sa NLU na batay sa GenAI/LLM ay makabuluhang mas mababa kumpara sa tradisyonal na pamamaraan.
Ang empirical na ebidensya na ipinakita sa komunidad ng NLP ay nagpapatunay sa transformative impact ng NLU na batay sa GenAI/LLM. Naipakita na nito ang walang kapantay na katumpakan at kahusayan nito. Susunod, tingnan natin ang pagiging cost-effective nito.
Mga Kinakailangan sa Data ng Pagsasanay: Isang Paghahambing na Pagsusuri
Ang isang nagbubunyag na paghahambing sa pagitan ng NLU na batay sa intensyon/entity at NLU na batay sa GenAI/LLM ay nagbibigay-liwanag sa kanilang magkakaibang mga kinakailangan sa data ng pagsasanay. Ang Figure 3.8 sa pahina 20 ay nagpapakita ng isang malaking kaibahan:
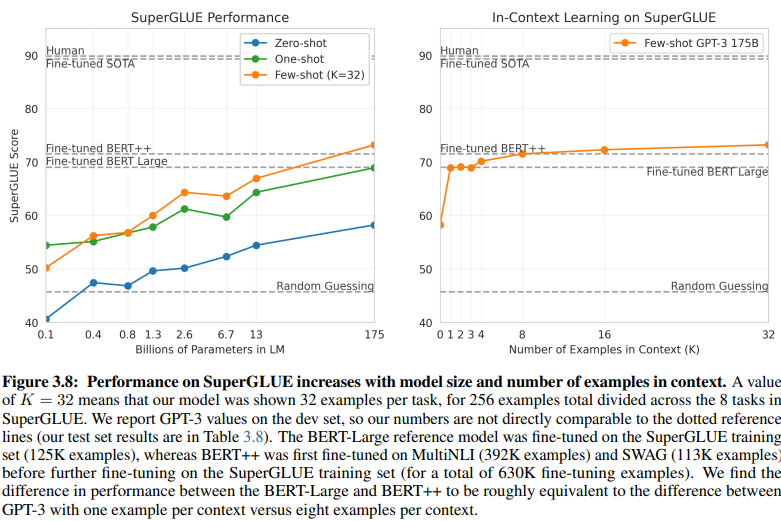
Ang NLU na batay sa GenAI/LLM ay nangangailangan ng mas kaunting data para sa pagsasanay
-
Supervised Learning NLU: Ang tradisyonal na pamamaraang ito ay nangangailangan ng malawak na dataset, na may higit sa kalahating milyong halimbawa (630K) na kinakailangan para sa epektibong pagsasanay.
-
Few-Shot GPT-3: Sa kabaligtaran, ang NLU na batay sa GenAI/LLM ay nagpapakita ng kapansin-pansing kahusayan, na may 32 halimbawa lamang bawat gawain na sapat para sa epektibong pag-tune.
Ang laki ng pagkakaiba na ito ay kapansin-pansin: 630,000 halimbawa kumpara sa 32 lamang. Ang dramatikong pagbawas na ito sa mga kinakailangan sa data ng pagsasanay ay nagreresulta sa malaking pagtitipid sa gastos para sa mga negosyong gumagamit ng NLU na batay sa GenAI/LLM.
Bukod pa rito, ang ipinahiwatig na epekto sa mga timeline ng pag-unlad ay malalim. Sa NLU na batay sa GenAI/LLM, ang pinaikling proses ng pagsasanay ay nagpapabilis sa pag-deploy ng mga sistema ng NLU sa pamamagitan ng maraming factor ng magnitude, na nagpapadali sa mabilis na pag-angkop at pagbabago sa larangan ng natural language processing.
Sa esensya, binibigyang-diin ng paghahambing na ito ang transformative potential ng NLU na batay sa GenAI/LLM, na nag-aalok ng walang kapantay na kahusayan at cost-effectiveness sa mga kinakailangan sa data ng pagsasanay at mga timeline ng pag-unlad.
Pagyakap sa Ebolusyon: Bakit Nangingibabaw ang NLU na Batay sa GenAI/LLM
Sa larangan ng natural language understanding, ang paglipat mula sa mga sistemang batay sa intensyon/entity patungo sa mga solusyong batay sa GenAI/LLM ay walang alinlangan na nagaganap. Ang pagbabagong ito ay itinutulak ng maraming salik na nagbibigay-diin sa mga limitasyon ng tradisyonal na NLU na batay sa intensyon/entity at ang mga nakakumbinsing bentahe na inaalok ng mga pamamaraang batay sa GenAI/LLM.
Ang NLU na batay sa intensyon/entity ay lalong itinuturing na luma na sa ilang nakakumbinsing dahilan:
-
Limitadong Flexibility: Ang tradisyonal na NLU system ay nakasalalay sa mga pre-defined na intensyon at entity, na naglilimita sa kakayahan ng mga chatbot at IVR na umangkop sa mga input ng user na lumilihis mula sa mga pre-defined na kategoryang ito.
-
Mga Hamon sa Pagpapanatili: Habang lumalaki ang mga sistemang ito at dumarami ang bilang ng mga intensyon at entity, ang pagiging kumplikado at oras na kinakailangan para sa pagpapanatili at mga update ay tumataas nang exponentially.
-
Kakulangan ng Pag-unawa sa Konteksto: Ang mga sistemang ito ay madalas na nabibigo sa pag-unawa sa masalimuot na mga nuances ng konteksto ng mga pag-uusap, na nagreresulta sa hindi tumpak na mga tugon o ang pangangailangan para sa karagdagang input ng user upang linawin ang mga intensyon.
-
Kakulangan ng Pagbuo: Ang mga NLU system na batay sa intensyon at entity ay likas na limitado sa kanilang kakayahang bumuo ng text, na naglilimita sa kanila sa mga gawain na nakasentro sa pag-uuri ng mga intensyon at pagkuha ng mga entity. Nililimitahan nito ang kakayahan ng mga chatbot at IVR na umangkop, na madalas na humahantong sa mga monotonous na tugon na hindi umaayon sa konteksto ng pag-uusap.
Sa matinding kaibahan, ang NLU na batay sa GenAI/LLM ay lumilitaw bilang nangingibabaw na trend dahil sa mga katangian nitong nagbabago:
-
Adaptive Learning: Ang mga modelo ng GenAI ay nagtataglay ng kakayahang matuto nang dynamic mula sa mga real-time na pag-uusap, na nagpapahintulot sa kanila na umangkop sa mga bagong paksa at pag-uugali ng user nang awtonomiya, nang hindi nangangailangan ng manual na pag-update.
-
Pag-unawa sa Konteksto: Ang mga modelong ito ay mahusay sa pag-unawa sa masalimuot na mga nuances ng konteksto ng mga pag-uusap, na nagreresulta sa mas tumpak at nauugnay na mga tugon na umaayon sa mga gumagamit.
-
Few-Shot Learning: Ang mga modelo ng GenAI ay maaaring sanayin na may kaunting halimbawa, na nagpapabilis sa proseso ng pagsasanay at nagbabawas ng pagdepende sa tahasang mga kahulugan ng intensyon at entity.
-
Pagbuo ng Natural na Wika: Ipinagmamalaki ng GenAI/LLM ang kakayahang bumuo ng text, na nagbibigay-kapangyarihan sa kanila na lumikha ng mga chatbot at iba pang mga aplikasyon ng NLP na naghahatid ng natural at contextually relevant na mga tugon.
Ang hinaharap ng conversational AI ay nakasalalay sa mga sistema na maaaring matuto at umangkop nang organiko, na nagbibigay sa mga gumagamit ng isang seamless at intuitive na karanasan. Ang NLU na batay sa GenAI/LLM ay naglalaman ng ebolusyon na ito, na nag-aalok ng isang dynamic at flexible na pamamaraan na lumalampas sa mga limitasyon ng tradisyonal na mga sistemang batay sa intensyon/entity.
Sa esensya, ang nangingibabaw na trajectory ng NLU ay walang alinlangan na tinukoy ng pagtaas ng mga pamamaraang batay sa GenAI/LLM, na nagpapahiwatig ng isang bagong panahon ng conversational AI na nagbibigay-priyoridad sa adaptability, contextuality, at user-centricity.


