





إلى جميع مديري خدمة العملاء أو التسويق، إذا سألك رئيسك السؤال التالي، أرسل لهم هذه المقالة:
“لماذا يعتبر فهم اللغة الطبيعية القائم على النية/الكيان قديمًا، ولماذا يعتبر فهم اللغة الطبيعية القائم على LLM/GenAI هو الاتجاه الواضح؟”
تهدف أنظمة فهم اللغة الطبيعية (NLU) إلى معالجة وتحليل مدخلات اللغة الطبيعية، مثل النص أو الكلام، من أجل استخلاص المعنى، واستخراج المعلومات ذات الصلة، وفهم النية الكامنة وراء الاتصال. يعد فهم اللغة الطبيعية مكونًا أساسيًا لتطبيقات الذكاء الاصطناعي المختلفة، بما في ذلك المساعدين الافتراضيين، وروبوتات الدردشة، وأدوات تحليل المشاعر، وأنظمة ترجمة اللغة، والمزيد. يلعب دورًا حاسمًا في تمكين التفاعل بين الإنسان والحاسوب وتسهيل تطوير أنظمة ذكية قادرة على فهم مدخلات اللغة الطبيعية والاستجابة لها.
يأتي هذا السؤال من عملاء راسخين يعيدون التفكير في نهجهم في IVR وروبوتات الدردشة. لقد تم تقييدهم بالجيل السابق من مكدس التكنولوجيا القائم على NLU، والذي تقدمه عادةً شركات التكنولوجيا الكبرى مثل: Microsoft Bot Framework (أو luis.ai), IBM Watson NLU، Google DialogFlow، Meta’s wit.ai، Amazon Lex، SAP Conversational AI، Nuance Mix NLU.
التحدي هو أن العملاء الرئيسيين مثل شركات التأمين والمؤسسات المالية والحكومات وشركات الطيران/وكلاء السيارات والصفقات الكبيرة الأخرى قد نشروا بالفعل تقنية الجيل الأخير. ولكن نظرًا لأن NLU القائم على النية/الكيان غير قابل للتطوير، يتعين على العملاء إنفاق مئات الآلاف إلى ملايين الدولارات كل عام للحفاظ على نظام NLU الخاص بهم وتحديثه. يساهم هذا النقص في قابلية التوسع في ارتفاع تكاليف الصيانة، مما يفيد في النهاية مزودي NLU من الجيل الأخير على حساب عملائهم. نظرًا لعدم قابليتهم للتوسع، فإن تكلفة الصيانة أعلى عامًا بعد عام.
لماذا يفشل فهم اللغة الطبيعية القائم على النية/الكيان في التوسع بفعالية؟
السبب الرئيسي يكمن في القوة التمييزية المحدودة للنموذج. إليك تفصيل لماذا هذا هو الحال:
-
الحد الأدنى من متطلبات النوايا: تتطلب نماذج فهم اللغة الطبيعية ما لا يقل عن نيتين متميزتين للتدريب بفعالية. على سبيل المثال، عند السؤال عن الطقس، قد تكون النية واضحة، ولكن وراء كل استعلام توجد نوايا متعددة محتملة، مثل احتياطي أو استفسارات غير متعلقة بالطقس مثل “كيف حالك؟”
-
متطلبات بيانات التدريب: تطلب شركات التكنولوجيا الكبرى عادةً آلاف الأمثلة الإيجابية لكل نية للتدريب الفعال. هذه المجموعة الواسعة من البيانات ضرورية لكي يتعلم النموذج ويميز بين النوايا المختلفة بدقة.
-
موازنة الأمثلة الإيجابية والسلبية: إضافة أمثلة إيجابية إلى نية واحدة تستلزم تضمين أمثلة سلبية لنوايا أخرى. يضمن هذا النهج المتوازن أن نموذج فهم اللغة الطبيعية يمكن أن يتعلم من كل من الحالات الإيجابية والسلبية بفعالية.
-
مجموعات أمثلة متنوعة: يجب أن تكون الأمثلة الإيجابية والسلبية متنوعة لمنع التجاوز وتعزيز قدرة النموذج على التعميم عبر سياقات مختلفة.
-
تعقيد إضافة نوايا جديدة: تتضمن إضافة نية جديدة إلى نموذج فهم اللغة الطبيعية الحالي عملية شاقة. يجب إضافة آلاف الأمثلة الإيجابية والسلبية، يليها إعادة تدريب النموذج للحفاظ على أدائه الأساسي. تصبح هذه العملية صعبة بشكل متزايد مع نمو عدد النوايا.
تأثير الوصف: فخ فهم اللغة الطبيعية القائم على النية/الكيان

تأثير الوصف لفهم اللغة الطبيعية القائم على النية/الكيان
على غرار الظاهرة في الطب المعروفة باسم “سلسلة الوصفات الطبية”، يمكن تشبيه تحديات قابلية التوسع في فهم اللغة الطبيعية القائم على النية/الكيان بسلسلة وصفات طبية مخيفة. تخيل فردًا مسنًا مثقلًا بعدد كبير من الأدوية اليومية، كل منها موصوف لمعالجة الآثار الجانبية للدواء السابق. هذا السيناريو مألوف جدًا، حيث يؤدي إدخال الدواء A إلى آثار جانبية تستلزم وصف الدواء B لمواجهتها. ومع ذلك، يقدم الدواء B مجموعة خاصة به من الآثار الجانبية، مما يستدعي الحاجة إلى الدواء C، وهكذا. وبالتالي، يجد الشخص المسن نفسه غارقًا في كومة من الحبوب لإدارتها - سلسلة وصفات طبية.
استعارة توضيحية أخرى هي بناء برج من الكتل، حيث تمثل كل كتلة دواءً. في البداية، يتم وضع الدواء A، ولكن عدم استقراره (الآثار الجانبية) يدفع إلى إضافة الدواء B لتثبيته. ومع ذلك، قد لا يندمج هذا الإضافة الجديدة بسلاسة، مما يتسبب في ميل البرج أكثر (الآثار الجانبية لـ B). في محاولة لتصحيح هذا عدم الاستقرار، يتم إضافة المزيد من الكتل (الأدوية C، D، إلخ)، مما يؤدي إلى تفاقم عدم استقرار البرج وقابليته للانهيار - تمثيل للمضاعفات الصحية المحتملة الناجمة عن الأدوية المتعددة.

استعارة توضيحية أخرى لفهم اللغة الطبيعية القائم على النية/الكيان هي بناء برج من الكتل
وبالمثل، مع كل نية جديدة تضاف إلى نظام فهم اللغة الطبيعية، يزداد ارتفاع برج الكتل المجازي، مما يزيد من عدم الاستقرار. تزداد الحاجة إلى التعزيز، مما يؤدي إلى ارتفاع تكاليف الصيانة. وبالتالي، بينما قد يبدو فهم اللغة الطبيعية القائم على النية/الكيان جذابًا للمزودين في البداية، فإن الواقع هو أنه يصبح مرهقًا بشكل مفرط للعملاء للحفاظ عليه. تفتقر هذه الأنظمة إلى قابلية التوسع، مما يشكل تحديات كبيرة لكل من المزودين والعملاء على حد سواء. في الأقسام اللاحقة، سنستكشف كيف يوفر فهم اللغة الطبيعية القائم على GenAI/LLM بديلاً أكثر استدامة وقابلية للتوسع لمعالجة هذه التحديات بفعالية.
فهم اللغة الطبيعية القائم على GenAI/LLM: حل مرن
يوفر فهم اللغة الطبيعية القائم على GenAI/LLM حلاً قويًا لتحديات قابلية التوسع التي تواجهها الأنظمة القائمة على النية/الكيان. يُعزى ذلك بشكل أساسي إلى عاملين رئيسيين:
-
التدريب المسبق والمعرفة العالمية: يتم تدريب نماذج GenAI/LLM مسبقًا على كميات هائلة من البيانات، مما يمكنها من وراثة ثروة من المعرفة العالمية. تلعب هذه المعرفة المتراكمة دورًا حاسمًا في التمييز بين النوايا المختلفة، وبالتالي تعزيز قدرات النموذج التمييزية ضد الأمثلة السلبية.
-
التعلم من عدد قليل من الأمثلة (Few-Shot Learning): إحدى السمات المميزة لفهم اللغة الطبيعية القائم على GenAI/LLM هي قدرته على استخدام تقنيات التعلم من عدد قليل من الأمثلة. على عكس الطرق التقليدية التي تتطلب بيانات تدريب واسعة لكل نية، يمكّن التعلم من عدد قليل من الأمثلة النموذج من التعلم من عدد قليل من الأمثلة فقط. يعزز هذا النهج التعليمي الفعال الأهداف المقصودة بأقل قدر من البيانات، مما يقلل بشكل كبير من عبء التدريب.
تأمل هذا السيناريو: عند تقديم الاستعلام “ما هو الطقس اليوم؟” كقارئ، فإنك تتعرف عليه غريزيًا على أنه استفسار عن الطقس وسط العديد من الجمل التي تصادفها يوميًا. هذه القدرة الفطرية على تمييز النية تشبه مفهوم التعلم من عدد قليل من الأمثلة.
كبالغين، يتم تدريب أدمغتنا مسبقًا على مفردات واسعة، تقدر بحوالي 150 مليون كلمة بحلول سن 20. يتيح لنا هذا التعرض اللغوي الواسع فهم النوايا الجديدة بسرعة عند مواجهتها، مما يتطلب عددًا قليلاً فقط من الأمثلة للتعزيز.
يعد Urban Dictionary مصدرًا ممتازًا لاستكشاف أمثلة للتعلم من عدد قليل من الأمثلة في العمل، مما يزيد من توضيح فعاليته في تسهيل الفهم السريع.
تعد قدرة التعلم من عدد قليل من الأمثلة المتأصلة في فهم اللغة الطبيعية القائم على GenAI/LLM أساسية في تقليل التكاليف وتمكين قابلية التوسع. مع اكتمال الجزء الأكبر من التدريب بالفعل أثناء التدريب المسبق، يصبح الضبط الدقيق للنموذج بعدد قليل من الأمثلة هو التركيز الأساسي، مما يبسط العملية ويعزز قابلية التوسع.
فهم اللغة الطبيعية القائم على GenAI/LLM: تقديم النتائج والأدلة
اعتبارًا من مارس 2024، شهد مجال معالجة اللغة الطبيعية (NLP) تحولًا كبيرًا، تميز بظهور فهم اللغة الطبيعية القائم على GenAI/LLM كعامل تغيير في اللعبة. لقد توقف التقدم الذي كان سائدًا في ابتكار معالجة اللغة الطبيعية على مدى السنتين إلى الثلاث سنوات الماضية، كما يتضح من ركود التطورات الحديثة. إذا قمت بفحص تقدم معالجة اللغة الطبيعية الذي كان الأكثر رواجًا في السابق للحالة الفنية، فقد توقف في الغالب قبل سنتين إلى ثلاث سنوات:
اعتدنا على تتبع ابتكار معالجة اللغة الطبيعية في هذا المستودع على Github. توقف التحديث في الغالب قبل سنتين إلى ثلاث سنوات.
أحد المعايير البارزة التي تؤكد هذا التحول النموذجي هو لوحة المتصدرين SuperGlue، مع أحدث إدخال لها في ديسمبر 2022. ومن المثير للاهتمام أن هذا الإطار الزمني يتزامن مع إدخال ChatGPT (3.5)، الذي أحدث صدمة في مجتمع معالجة اللغة الطبيعية.
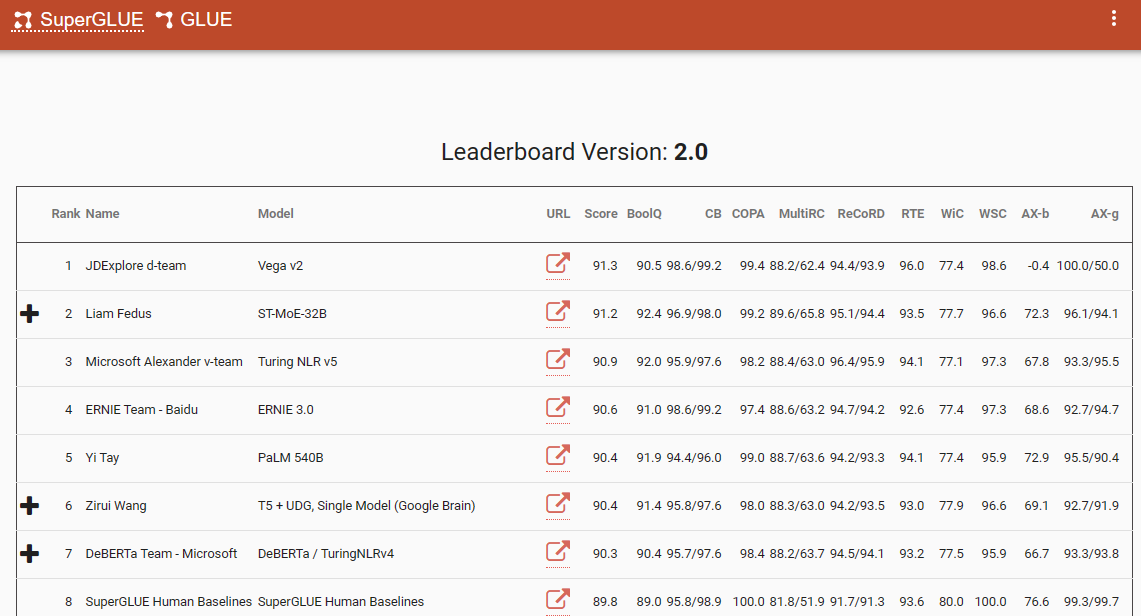
كانت لوحة المتصدرين SuperGlue شائعة حتى إدخال ChatGPT
تقدم ورقة GPT-3 الأساسية، التي تحمل عنوان “نماذج اللغة هي متعلمون من عدد قليل من الأمثلة”، دليلًا مقنعًا على فعالية التعلم من عدد قليل من الأمثلة. يوضح الشكل 2.1 في الصفحة 7 من الورقة الفروق بين أساليب التعلم الصفري، والتعلم من مثال واحد، والتعلم من عدد قليل من الأمثلة، مع تسليط الضوء على تفوق الأخير من حيث كفاءة وفعالية التعلم.

الفروق بين أساليب التعلم الصفري، والتعلم من مثال واحد، والتعلم من عدد قليل من الأمثلة
بالإضافة إلى ذلك، تؤكد فعالية فهم اللغة الطبيعية القائم على GenAI/LLM الجدول 3.8 في الصفحة 19، والذي يقدم مقارنة مباشرة بين طرق فهم اللغة الطبيعية التقليدية الخاضعة للإشراف وتعلم GPT-3 من عدد قليل من الأمثلة. في هذه المقارنة، يتفوق GPT-3 Few-Shot على Fine-tuned BERT-Large، وهو تمثيل للتعلم الخاضع للإشراف المستخدم بواسطة أنظمة فهم اللغة الطبيعية القائمة على النية/الكيان، عبر مهام مختلفة.
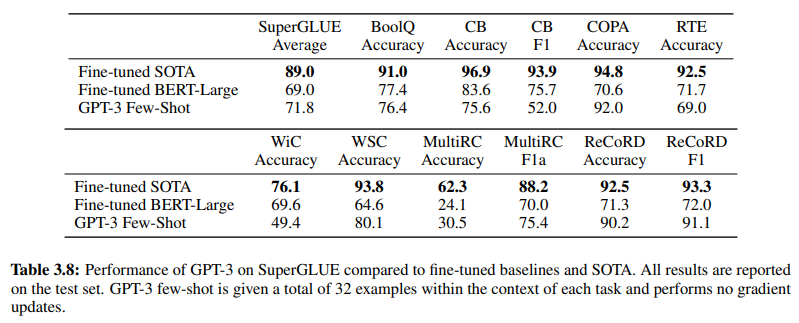
يتفوق GPT-3 Few-Shot على Fine-tuned BERT-Large عبر مهام مختلفة
لا يتجلى تفوق GPT-3 Few-Shot في دقته فحسب، بل في فعاليته من حيث التكلفة أيضًا. فتكاليف الإعداد الأولية والصيانة المرتبطة بفهم اللغة الطبيعية القائم على GenAI/LLM أقل بكثير مقارنة بالطرق التقليدية.
تؤكد الأدلة التجريبية المقدمة في مجتمع معالجة اللغة الطبيعية على التأثير التحويلي لفهم اللغة الطبيعية القائم على GenAI/LLM. لقد أظهر بالفعل دقته وكفاءته التي لا مثيل لها. بعد ذلك، دعنا نتحقق من فعاليته من حيث التكلفة.
متطلبات بيانات التدريب: تحليل مقارن
مقارنة كاشفة بين فهم اللغة الطبيعية القائم على النية/الكيان وفهم اللغة الطبيعية القائم على GenAI/LLM تسلط الضوء على متطلبات بيانات التدريب المتباينة. يقدم الشكل 3.8 في الصفحة 20 تباينًا صارخًا:
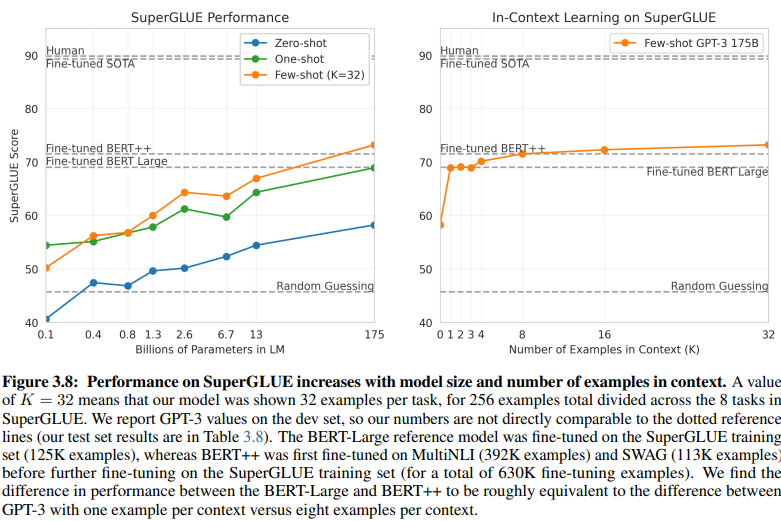
يتطلب فهم اللغة الطبيعية القائم على GenAI/LLM بيانات أقل بكثير للتدريب
-
فهم اللغة الطبيعية للتعلم الخاضع للإشراف: يتطلب هذا النهج التقليدي مجموعة بيانات واسعة، مع أكثر من نصف مليون مثال (630 ألف) مطلوب للتدريب الفعال.
-
GPT-3 للتعلم من عدد قليل من الأمثلة (Few-Shot GPT-3): على النقيض من ذلك، يُظهر فهم اللغة الطبيعية القائم على GenAI/LLM كفاءة ملحوظة، مع 32 مثالًا فقط لكل مهمة كافية للضبط الفعال.
حجم هذا الاختلاف مذهل: 630,000 مثال مقابل 32 فقط. يترجم هذا الانخفاض الهائل في متطلبات بيانات التدريب إلى وفورات كبيرة في التكاليف للشركات التي تتبنى فهم اللغة الطبيعية القائم على GenAI/LLM.
علاوة على ذلك، فإن التأثير الضمني على الجداول الزمنية للتطوير عميق. مع فهم اللغة الطبيعية القائم على GenAI/LLM، فإن عملية التدريب المختصرة تسرع نشر أنظمة فهم اللغة الطبيعية بعوامل متعددة من حيث الحجم، مما يسهل التكيف السريع والابتكار في مجال معالجة اللغة الطبيعية.
في جوهرها، تؤكد هذه المقارنة على الإمكانات التحويلية لفهم اللغة الطبيعية القائم على GenAI/LLM، مما يوفر كفاءة لا مثيل لها وفعالية من حيث التكلفة في متطلبات بيانات التدريب والجداول الزمنية للتطوير.
احتضان التطور: لماذا يسود فهم اللغة الطبيعية القائم على GenAI/LLM
في مجال فهم اللغة الطبيعية، فإن الانتقال من الأنظمة القائمة على النية/الكيان إلى الحلول القائمة على GenAI/LLM يجري بلا منازع. يدفع هذا التحول العديد من العوامل التي تؤكد قيود فهم اللغة الطبيعية التقليدي القائم على النية/الكيان والمزايا المقنعة التي تقدمها الأساليب القائمة على GenAI/LLM.
يعتبر فهم اللغة الطبيعية القائم على النية/الكيان قديمًا بشكل متزايد لعدة أسباب مقنعة:
-
مرونة محدودة: تعتمد أنظمة فهم اللغة الطبيعية التقليدية على نوايا وكيانات محددة مسبقًا، مما يقيد قابلية روبوتات الدردشة و IVRs للتكيف مع مدخلات المستخدم التي تنحرف عن هذه الفئات المحددة مسبقًا.
-
تحديات الصيانة: مع توسع هذه الأنظمة وتكاثر عدد النوايا والكيانات، تزداد التعقيد والوقت اللازم للصيانة والتحديثات بشكل كبير.
-
نقص الفهم السياقي: غالبًا ما تتعثر هذه الأنظمة في فهم الفروق الدقيقة السياقية للمحادثات، مما يؤدي إلى استجابات غير دقيقة أو الحاجة إلى إدخال مستخدم إضافي لتوضيح النوايا.
-
نقص التوليد: أنظمة فهم اللغة الطبيعية القائمة على النية والكيان محدودة بطبيعتها في قدرتها على توليد النص، مما يقيدها بالمهام التي تركز على تصنيف النوايا واستخراج الكيانات. وهذا يحد من قابلية روبوتات الدردشة و IVRs للتكيف، مما يؤدي غالبًا إلى استجابات رتيبة تفشل في التوافق مع السياق المحادثي.
على النقيض من ذلك، يظهر فهم اللغة الطبيعية القائم على GenAI/LLM كاتجاه سائد بسبب سماته التحويلية:
-
التعلم التكيفي: تمتلك نماذج GenAI القدرة على التعلم ديناميكيًا من المحادثات في الوقت الفعلي، مما يمكنها من التكيف مع الموضوعات الجديدة وسلوكيات المستخدم بشكل مستقل، دون الحاجة إلى تحديثات يدوية.
-
الفهم السياقي: تتفوق هذه النماذج في فهم الفروق الدقيقة السياقية المعقدة للمحادثات، مما يؤدي إلى استجابات أكثر دقة وذات صلة تتوافق مع المستخدمين.
-
التعلم من عدد قليل من الأمثلة (Few-Shot Learning): يمكن تدريب نماذج GenAI بعدد قليل من الأمثلة، مما يبسط عملية التدريب ويقلل الاعتماد على تعريفات النية والكيان الصريحة.
-
توليد اللغة الطبيعية: تتميز نماذج GenAI/LLMs بالقدرة على توليد النص، مما يمكنها من إنشاء روبوتات الدردشة وتطبيقات معالجة اللغة الطبيعية الأخرى التي تقدم استجابات طبيعية وذات صلة سياقية.
يعتمد مستقبل الذكاء الاصطناعي المحادثة على الأنظمة التي يمكنها التعلم والتكيف عضويًا، مما يوفر للمستخدمين تجربة سلسة وبديهية. يجسد فهم اللغة الطبيعية القائم على GenAI/LLM هذا التطور، حيث يقدم نهجًا ديناميكيًا ومرنًا يتجاوز قيود الأنظمة التقليدية القائمة على النية/الكيان.
في جوهرها، يتم تحديد المسار السائد لفهم اللغة الطبيعية بشكل لا لبس فيه من خلال صعود الأساليب القائمة على GenAI/LLM، مما يبشر بعصر جديد من الذكاء الاصطناعي المحادثة الذي يولي الأولوية للقدرة على التكيف والسياقية والتركيز على المستخدم.


