





À tous les directeurs du service client ou du marketing, si votre patron vous pose la question suivante, envoyez-leur cet article :
“Pourquoi le NLU basé sur l’intention/entité est-il obsolète et pourquoi le NLU basé sur LLM/GenAI est-il la tendance évidente ?”
Les systèmes de compréhension du langage naturel (NLU) visent à traiter et analyser les entrées en langage naturel, telles que le texte ou la parole, afin d’en déduire le sens, d’extraire les informations pertinentes et de comprendre l’intention sous-jacente à la communication. Le NLU est un composant fondamental de diverses applications d’IA, notamment les assistants virtuels, les chatbots, les outils d’analyse des sentiments, les systèmes de traduction linguistique, et bien plus encore. Il joue un rôle essentiel en permettant l’interaction homme-machine et en facilitant le développement de systèmes intelligents capables de comprendre et de répondre aux entrées en langage naturel.
Cette question provient de clients établis qui repensent leur approche IVR et chatbot. Ils sont bloqués dans la génération précédente de piles technologiques basées sur le NLU, généralement offertes par les grands acteurs technologiques tels que : Microsoft Bot Framework (ou luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
Le défi est que les principaux clients tels que les compagnies d’assurance, les institutions financières, les gouvernements, les compagnies aériennes/concessionnaires automobiles et autres grandes entreprises ont déjà déployé la technologie de la dernière génération. Mais parce que le NLU basé sur l’intention/entité n’est pas évolutif, les clients doivent dépenser des centaines de milliers à des millions de dollars chaque année pour maintenir et mettre à niveau leur système NLU. Ce manque d’évolutivité contribue à l’augmentation des coûts de maintenance, ce qui profite finalement aux fournisseurs de NLU de dernière génération aux dépens de leurs clients. Parce qu’ils ne sont pas évolutifs, les coûts de maintenance augmentent d’année en année.
Pourquoi le NLU basé sur l’intention/entité ne parvient-il pas à évoluer efficacement ?
La raison principale réside dans le pouvoir discriminatoire limité du modèle. Voici une explication de la raison pour laquelle il en est ainsi :
-
Exigence minimale d’intentions: Les modèles NLU nécessitent au moins deux intentions distinctes pour s’entraîner efficacement. Par exemple, lorsqu’on pose une question sur la météo, l’intention peut être claire, mais derrière chaque requête se cachent de multiples intentions potentielles, telles qu’un repli ou des demandes non liées à la météo comme “comment allez-vous ?”
-
Exigences en matière de données d’entraînement: Les grandes entreprises technologiques exigent généralement des milliers d’exemples positifs par intention pour un entraînement efficace. Cet ensemble de données étendu est nécessaire pour que le modèle puisse apprendre et discriminer avec précision entre les différentes intentions.
-
Équilibrage des exemples positifs et négatifs: L’ajout d’exemples positifs à une intention nécessite l’inclusion d’exemples négatifs pour d’autres intentions. Cette approche équilibrée garantit que le modèle NLU peut apprendre efficacement des instances positives et négatives.
-
Ensembles d’exemples diversifiés: Les exemples positifs et négatifs doivent être diversifiés pour éviter le surapprentissage et améliorer la capacité du modèle à généraliser dans différents contextes.
-
Complexité de l’ajout de nouvelles intentions: L’ajout d’une nouvelle intention à un modèle NLU existant implique un processus laborieux. Des milliers d’exemples positifs et négatifs doivent être ajoutés, suivis d’un réentraînement du modèle pour maintenir ses performances de base. Ce processus devient de plus en plus difficile à mesure que le nombre d’intentions augmente.
L’effet de prescription : le piège du NLU basé sur l’intention/entité

L’effet de prescription du NLU basé sur l’intention/entité
Analogue au phénomène en médecine connu sous le nom de « cascade de prescription », les défis d’évolutivité du NLU basé sur l’intention/entité peuvent être comparés à une cascade de prescriptions intimidante. Imaginez une personne âgée accablée par une pléthore de médicaments quotidiens, chacun prescrit pour traiter les effets secondaires du précédent. Ce scénario est trop familier, où l’introduction du médicament A entraîne des effets secondaires nécessitant la prescription du médicament B pour les contrecarrer. Cependant, le médicament B introduit son propre ensemble d’effets secondaires, ce qui incite à la nécessité du médicament C, et ainsi de suite. Par conséquent, la personne âgée se retrouve inondée d’une montagne de pilules à gérer – une cascade de prescription.
Une autre métaphore illustrative est celle de la construction d’une tour de blocs, chaque bloc représentant un médicament. Initialement, le médicament A est placé, mais son instabilité (effets secondaires) incite à l’ajout du médicament B pour le stabiliser. Cependant, ce nouvel ajout peut ne pas s’intégrer de manière transparente, ce qui fait que la tour penche davantage (effet secondaire de B). Dans un effort pour corriger cette instabilité, d’autres blocs (médicaments C, D, etc.) sont ajoutés, ce qui exacerbe l’instabilité de la tour et sa susceptibilité à l’effondrement – une représentation des complications de santé potentielles résultant de plusieurs médicaments.

Une autre métaphore illustrative pour le NLU basé sur l’intention/entité est la construction d’une tour de blocs
De même, avec chaque nouvelle intention ajoutée à un système NLU, la tour métaphorique de blocs grandit, augmentant l’instabilité. Le besoin de renforcement s’intensifie, ce qui entraîne des coûts de maintenance plus élevés. Par conséquent, bien que le NLU basé sur l’intention/entité puisse sembler attrayant pour les fournisseurs au départ, la réalité est qu’il devient excessivement lourd à maintenir pour les clients. Ces systèmes manquent d’évolutivité, ce qui pose des défis importants tant pour les fournisseurs que pour les clients. Dans les sections suivantes, nous explorerons comment le NLU basé sur GenAI/LLM offre une alternative plus durable et évolutive pour relever efficacement ces défis.
NLU basé sur GenAI/LLM : une solution résiliente
Le NLU basé sur GenAI/LLM offre une solution robuste aux défis d’évolutivité rencontrés par les systèmes basés sur l’intention/entité. Cela est principalement attribué à deux facteurs clés :
-
Pré-entraînement et connaissances du monde: Les modèles GenAI/LLM sont pré-entraînés sur de vastes quantités de données, ce qui leur permet d’hériter d’une richesse de connaissances du monde. Ces connaissances accumulées jouent un rôle crucial dans la distinction entre diverses intentions, améliorant ainsi les capacités discriminatoires du modèle contre les exemples négatifs.
-
Apprentissage à quelques coups (Few-Shot Learning): L’une des caractéristiques distinctives du NLU basé sur GenAI/LLM est sa capacité à utiliser des techniques d’apprentissage à quelques coups. Contrairement aux méthodes traditionnelles qui nécessitent des données d’entraînement étendues pour chaque intention, l’apprentissage à quelques coups permet au modèle d’apprendre à partir de quelques exemples seulement. Cette approche d’apprentissage efficace renforce les objectifs visés avec un minimum de données, réduisant considérablement la charge d’entraînement.
Considérez ce scénario : lorsqu’on vous présente la requête « Quel temps fait-il aujourd’hui ? » en tant que lecteur, vous la reconnaissez instinctivement comme une question sur la météo parmi la multitude de phrases rencontrées quotidiennement. Cette capacité innée à discerner l’intention est similaire au concept d’apprentissage à quelques coups.
En tant qu’adultes, nos cerveaux sont pré-entraînés avec un vaste vocabulaire, estimé à environ 150 millions de mots à l’âge de 20 ans. Cette exposition linguistique étendue nous permet de saisir rapidement de nouvelles intentions dès que nous les rencontrons, ne nécessitant que quelques exemples pour le renforcement.
L’Urban Dictionary est une excellente ressource pour explorer des exemples d’apprentissage à quelques coups en action, illustrant davantage son efficacité à faciliter une compréhension rapide.
La capacité d’apprentissage à quelques coups inhérente au NLU basé sur GenAI/LLM est essentielle pour réduire les coûts et permettre l’évolutivité. La majeure partie de l’entraînement étant déjà terminée lors du pré-entraînement, l’ajustement fin du modèle avec un nombre minimal d’exemples devient l’objectif principal, rationalisant le processus et améliorant l’évolutivité.
NLU basé sur GenAI/LLM : Résultats et preuves
En mars 2024, le paysage du traitement du langage naturel (TLN) a subi un changement significatif, marqué par l’émergence du NLU basé sur GenAI/LLM comme un tournant. Les progrès autrefois dominants dans l’innovation du TLN ont stagné au cours des 2-3 dernières années, comme en témoigne la stagnation des avancées de pointe. Si vous consultez les progrès du TLN autrefois les plus populaires pour l’état de l’art, ils se sont pour la plupart arrêtés il y a 2-3 ans :
Nous suivions l’innovation en TLN sur ce dépôt Github. La mise à jour s’est principalement arrêtée il y a 2-3 ans.
Un repère notable qui souligne ce changement de paradigme est le classement SuperGlue, avec sa dernière entrée en décembre 2022. Fait intéressant, cette période coïncide avec l’introduction de ChatGPT (3.5), qui a provoqué une onde de choc dans la communauté du TLN.
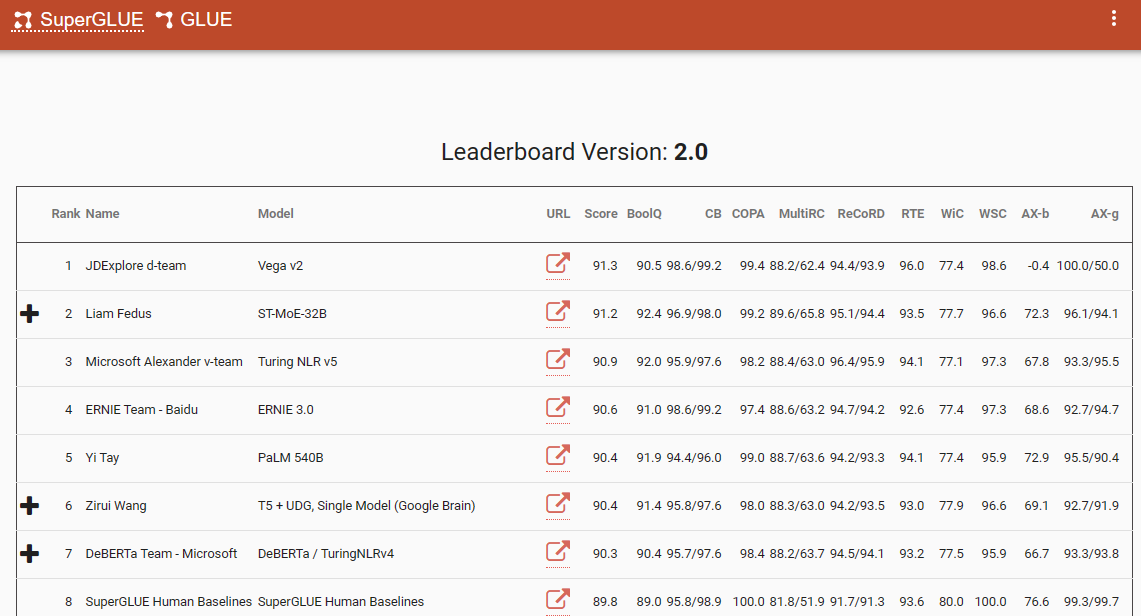
Le classement SuperGlue était populaire jusqu’à l’introduction de ChatGPT
L’article séminal de GPT-3, intitulé à juste titre « Les modèles de langage sont des apprenants à quelques coups », offre des preuves convaincantes de l’efficacité de l’apprentissage à quelques coups. La figure 2.1 à la page 7 de l’article délimite les distinctions entre les approches d’apprentissage à zéro coup, à un coup et à quelques coups, soulignant la supériorité de cette dernière en termes d’efficacité et d’efficience d’apprentissage.

Les distinctions entre les approches d’apprentissage à zéro coup, à un coup et à quelques coups
De plus, corroborant l’efficacité du NLU basé sur GenAI/LLM, le tableau 3.8 à la page 19 fournit une comparaison directe entre les méthodes NLU supervisées traditionnelles et l’apprentissage à quelques coups de GPT-3. Dans cette comparaison, GPT-3 Few-Shot surpasse Fine-tuned BERT-Large, une représentation de l’apprentissage supervisé employé par les systèmes NLU basés sur l’intention/entité, dans diverses tâches.
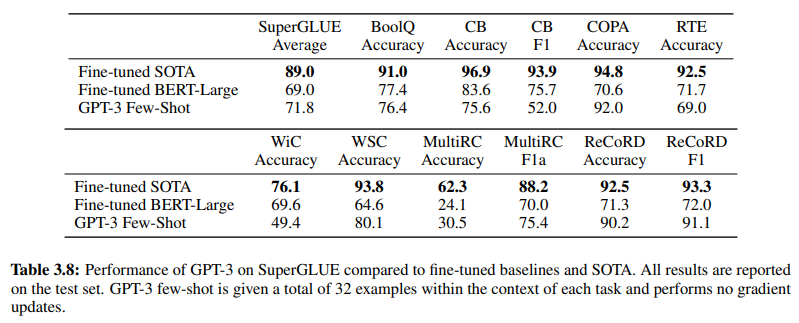
GPT-3 Few-Shot surpasse Fine-tuned BERT-Large dans diverses tâches
La supériorité de GPT-3 Few-Shot est non seulement évidente dans sa précision, mais aussi dans sa rentabilité. Les coûts de configuration initiale et de maintenance associés au NLU basé sur GenAI/LLM sont considérablement inférieurs à ceux des méthodes traditionnelles.
Les preuves empiriques présentées dans la communauté NLP soulignent l’impact transformateur du NLU basé sur GenAI/LLM. Il a déjà démontré sa précision et son efficacité inégalées. Ensuite, examinons son efficacité en termes de coûts.
Exigences en matière de données d’entraînement : une analyse comparative
Une comparaison révélatrice entre le NLU basé sur l’intention/entité et le NLU basé sur GenAI/LLM met en lumière leurs exigences différentes en matière de données d’entraînement. La figure 3.8 à la page 20 présente un contraste frappant :
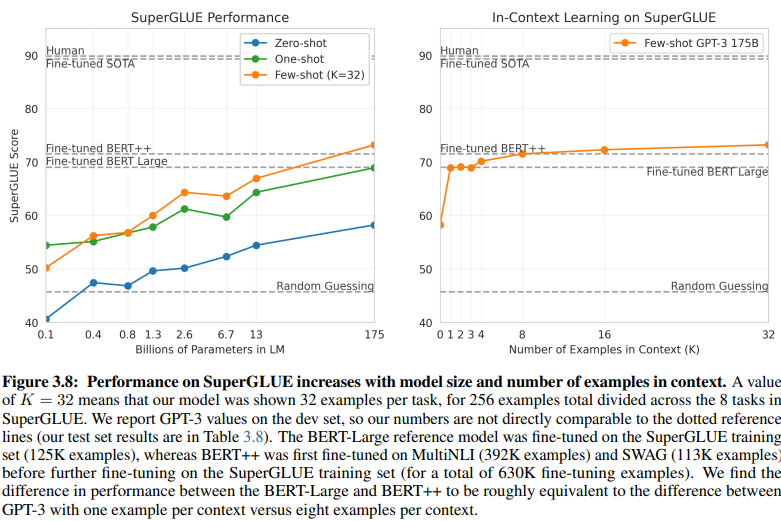
Le NLU basé sur GenAI/LLM nécessite beaucoup moins de données pour l’entraînement
-
NLU d’apprentissage supervisé: Cette approche traditionnelle nécessite un ensemble de données étendu, avec plus d’un demi-million d’exemples (630K) requis pour un entraînement efficace.
-
GPT-3 à quelques coups: En revanche, le NLU basé sur GenAI/LLM démontre une efficacité remarquable, avec seulement 32 exemples par tâche suffisants pour un réglage fin efficace.
L’ampleur de cette différence est frappante : 630 000 exemples contre seulement 32. Cette réduction drastique des exigences en matière de données d’entraînement se traduit par des économies de coûts significatives pour les entreprises qui adoptent le NLU basé sur GenAI/LLM.
De plus, l’impact implicite sur les délais de développement est profond. Avec le NLU basé sur GenAI/LLM, le processus d’entraînement raccourci accélère le déploiement des systèmes NLU par plusieurs facteurs de grandeur, facilitant une adaptation et une innovation rapides dans le domaine du traitement du langage naturel.
Essentiellement, cette comparaison souligne le potentiel transformateur du NLU basé sur GenAI/LLM, offrant une efficacité et une rentabilité inégalées en termes d’exigences en matière de données d’entraînement et de délais de développement.
Adopter l’évolution : pourquoi le NLU basé sur GenAI/LLM prévaut
Dans le domaine de la compréhension du langage naturel, la transition des systèmes basés sur l’intention/entité vers les solutions basées sur GenAI/LLM est incontestablement en cours. Ce changement est propulsé par une multitude de facteurs qui soulignent les limites du NLU traditionnel basé sur l’intention/entité et les avantages convaincants offerts par les approches basées sur GenAI/LLM.
Le NLU basé sur l’intention/entité est de plus en plus considéré comme obsolète pour plusieurs raisons convaincantes :
-
Flexibilité limitée: Les systèmes NLU traditionnels reposent sur des intentions et des entités prédéfinies, ce qui limite l’adaptabilité des chatbots et des IVR aux entrées utilisateur qui s’écartent de ces catégories prédéfinies.
-
Défis de maintenance: À mesure que ces systèmes évoluent et que le nombre d’intentions et d’entités prolifère, la complexité et le temps requis pour la maintenance et les mises à jour augmentent de manière exponentielle.
-
Manque de compréhension contextuelle: Ces systèmes échouent souvent à saisir les nuances contextuelles complexes des conversations, ce qui entraîne des réponses inexactes ou la nécessité d’une saisie utilisateur supplémentaire pour clarifier les intentions.
-
Manque de génération: Les systèmes NLU basés sur l’intention et l’entité sont intrinsèquement limités dans leur capacité à générer du texte, ce qui les confine aux tâches centrées sur la classification des intentions et l’extraction des entités. Cela restreint l’adaptabilité des chatbots et des IVR, conduisant souvent à des réponses monotones qui ne correspondent pas au contexte conversationnel.
En revanche, le NLU basé sur GenAI/LLM apparaît comme la tendance dominante en raison de ses attributs transformateurs :
-
Apprentissage adaptatif: Les modèles GenAI possèdent la capacité d’apprendre dynamiquement à partir de conversations en temps réel, ce qui leur permet de s’adapter à de nouveaux sujets et comportements des utilisateurs de manière autonome, sans nécessiter de mises à jour manuelles.
-
Compréhension contextuelle: Ces modèles excellent dans la compréhension des nuances contextuelles complexes des conversations, ce qui se traduit par des réponses plus précises et pertinentes qui résonnent avec les utilisateurs.
-
Apprentissage à quelques coups: Les modèles GenAI peuvent être entraînés avec un minimum d’exemples, ce qui rationalise le processus d’entraînement et réduit la dépendance aux définitions explicites d’intentions et d’entités.
-
Génération de langage naturel: Les GenAI/LLM possèdent la capacité de générer du texte, ce qui leur permet de créer des chatbots et d’autres applications de TLN qui fournissent des réponses naturelles et contextuellement pertinentes.
L’avenir de l’IA conversationnelle repose sur des systèmes capables d’apprendre et de s’adapter de manière organique, offrant aux utilisateurs une expérience fluide et intuitive. Le NLU basé sur GenAI/LLM incarne cette évolution, offrant une approche dynamique et flexible qui transcende les contraintes des systèmes traditionnels basés sur l’intention/entité.
Essentiellement, la trajectoire dominante du NLU est définie sans équivoque par l’ascension des approches basées sur GenAI/LLM, annonçant une nouvelle ère de l’IA conversationnelle qui privilégie l’adaptabilité, la contextualité et l’orientation utilisateur.


