





ถึงผู้อำนวยการฝ่ายบริการลูกค้าหรือการตลาดทุกท่าน หากเจ้านายของคุณถามคำถามต่อไปนี้ ให้ส่งบทความนี้ให้พวกเขา:
“ทำไม NLU ที่อิงตามเจตนา/เอนทิตีจึงล้าสมัย และทำไม LLM/GenAI จึงเป็นเทรนด์ที่ชัดเจน?”
ระบบ Natural Language Understanding (NLU) มีเป้าหมายที่จะประมวลผลและวิเคราะห์ข้อมูลภาษาธรรมชาติ เช่น ข้อความหรือเสียง เพื่อดึงความหมาย แยกข้อมูลที่เกี่ยวข้อง และทำความเข้าใจเจตนาที่ซ่อนอยู่เบื้องหลังการสื่อสาร NLU เป็นองค์ประกอบพื้นฐานของแอปพลิเคชัน AI ต่างๆ รวมถึงผู้ช่วยเสมือน แชทบอท เครื่องมือวิเคราะห์ความรู้สึก ระบบแปลภาษา และอื่นๆ อีกมากมาย มีบทบาทสำคัญในการเปิดใช้งานการโต้ตอบระหว่างมนุษย์กับคอมพิวเตอร์ และอำนวยความสะดวกในการพัฒนาระบบอัจฉริยะที่สามารถเข้าใจและตอบสนองต่อข้อมูลภาษาธรรมชาติได้
คำถามนี้มาจากลูกค้าที่จัดตั้งขึ้นซึ่งกำลังพิจารณาแนวทาง IVR และแชทบอทของตนใหม่ พวกเขาถูกล็อกอยู่ในเทคโนโลยี NLU รุ่นก่อนหน้า ซึ่งมักจะนำเสนอโดยผู้เล่นเทคโนโลยีรายใหญ่ เช่น Microsoft Bot Framework (หรือ luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU
ความท้าทายคือลูกค้าหลัก เช่น บริษัทประกันภัย สถาบันการเงิน รัฐบาล สายการบิน/ตัวแทนจำหน่ายรถยนต์ และข้อตกลงใหญ่อื่นๆ ได้นำเทคโนโลยีรุ่นล่าสุดมาใช้แล้ว แต่เนื่องจาก NLU ที่อิงตามเจตนา/เอนทิตีไม่สามารถปรับขนาดได้ ลูกค้าจึงต้องใช้เงินหลายแสนถึงหลายล้านดอลลาร์ทุกปีเพื่อบำรุงรักษาและอัปเกรดระบบ NLU ของตน การขาดความสามารถในการปรับขนาดนี้ส่งผลให้ต้นทุนการบำรุงรักษาสูงขึ้น ซึ่งท้ายที่สุดแล้วจะเป็นประโยชน์ต่อผู้ให้บริการ NLU รุ่นล่าสุดโดยแลกกับลูกค้าของตน เนื่องจากไม่สามารถปรับขนาดได้ ต้นทุนการบำรุงรักษาจึงสูงขึ้นทุกปี
ทำไม NLU ที่อิงตามเจตนา/เอนทิตีจึงไม่สามารถปรับขนาดได้อย่างมีประสิทธิภาพ?
เหตุผลหลักอยู่ที่พลังการจำแนกที่จำกัดของโมเดล นี่คือรายละเอียดว่าทำไมจึงเป็นเช่นนั้น:
-
ข้อกำหนดเจตนาขั้นต่ำ: โมเดล NLU ต้องการเจตนาที่แตกต่างกันอย่างน้อยสองเจตนาเพื่อฝึกอบรมอย่างมีประสิทธิภาพ ตัวอย่างเช่น เมื่อถามเกี่ยวกับสภาพอากาศ เจตนาอาจจะชัดเจน แต่เบื้องหลังแต่ละคำถามมีเจตนาที่เป็นไปได้หลายอย่าง เช่น การสำรองข้อมูล หรือคำถามที่ไม่เกี่ยวข้องกับสภาพอากาศ เช่น “สบายดีไหม?”
-
ความต้องการข้อมูลการฝึกอบรม: บริษัทเทคโนโลยีขนาดใหญ่มักต้องการตัวอย่างเชิงบวกหลายพันตัวอย่างต่อเจตนาสำหรับการฝึกอบรมที่มีประสิทธิภาพ ชุดข้อมูลที่กว้างขวางนี้จำเป็นสำหรับโมเดลในการเรียนรู้และจำแนกความแตกต่างระหว่างเจตนาต่างๆ ได้อย่างแม่นยำ
-
การปรับสมดุลตัวอย่างเชิงบวกและเชิงลบ: การเพิ่มตัวอย่างเชิงบวกให้กับเจตนาหนึ่งจำเป็นต้องรวมตัวอย่างเชิงลบสำหรับเจตนาอื่นๆ แนวทางที่สมดุลนี้ช่วยให้โมเดล NLU สามารถเรียนรู้จากทั้งตัวอย่างเชิงบวกและเชิงลบได้อย่างมีประสิทธิภาพ
-
ชุดตัวอย่างที่หลากหลาย: ทั้งตัวอย่างเชิงบวกและเชิงลบต้องมีความหลากหลายเพื่อป้องกันการโอเวอร์ฟิตติ้งและเพิ่มความสามารถของโมเดลในการสรุปผลในบริบทที่แตกต่างกัน
-
ความซับซ้อนในการเพิ่มเจตนาใหม่: การเพิ่มเจตนาใหม่ให้กับโมเดล NLU ที่มีอยู่เกี่ยวข้องกับกระบวนการที่ต้องใช้แรงงานมาก ต้องเพิ่มตัวอย่างเชิงบวกและเชิงลบหลายพันตัวอย่าง จากนั้นจึงฝึกอบรมโมเดลใหม่เพื่อรักษาประสิทธิภาพพื้นฐาน กระบวนการนี้จะท้าทายมากขึ้นเรื่อยๆ เมื่อจำนวนเจตนาเพิ่มขึ้น
ผลกระทบของการสั่งยา: ข้อผิดพลาดของ NLU ที่อิงตามเจตนา/เอนทิตี

ผลกระทบของการสั่งยาของ NLU ที่อิงตามเจตนา/เอนทิตี
คล้ายกับปรากฏการณ์ทางการแพทย์ที่เรียกว่า ”** prescribing cascade**” ความท้าทายด้านความสามารถในการปรับขนาดของ NLU ที่อิงตามเจตนา/เอนทิตีสามารถเปรียบได้กับน้ำตกแห่งการสั่งยาที่น่ากลัว ลองนึกภาพผู้สูงอายุที่แบกรับภาระยาประจำวันจำนวนมาก ซึ่งแต่ละเม็ดถูกสั่งเพื่อจัดการกับผลข้างเคียงของยาเม็ดก่อนหน้า สถานการณ์นี้คุ้นเคยกันดี โดยที่การแนะนำยา A นำไปสู่ผลข้างเคียงที่จำเป็นต้องสั่งยา B เพื่อต่อต้าน อย่างไรก็ตาม ยา B ก็มีผลข้างเคียงของตัวเอง ซึ่งกระตุ้นให้ต้องใช้ยา C และอื่นๆ อีกมากมาย ผลที่ตามมาคือ ผู้สูงอายุพบว่าตัวเองจมอยู่กับกองยาจำนวนมากที่ต้องจัดการ—ซึ่งก็คือ prescribing cascade
อีกหนึ่งอุปมาที่ชัดเจนคือการสร้างหอคอยจากบล็อก โดยแต่ละบล็อกแทนยา ในตอนแรก ยา A ถูกวางไว้ แต่ความไม่เสถียร (ผลข้างเคียง) กระตุ้นให้เพิ่มยา B เพื่อทำให้เสถียร อย่างไรก็ตาม การเพิ่มใหม่นี้อาจไม่รวมเข้าด้วยกันอย่างราบรื่น ทำให้หอคอยเอียงมากขึ้น (ผลข้างเคียงของ B) ในความพยายามที่จะแก้ไขความไม่เสถียรนี้ บล็อกเพิ่มเติม (ยา C, D, ฯลฯ) ถูกเพิ่มเข้ามา ทำให้ความไม่เสถียรของหอคอยและความอ่อนแอต่อการพังทลายแย่ลง—ซึ่งเป็นการแสดงถึงภาวะแทรกซ้อนทางสุขภาพที่อาจเกิดขึ้นจากการใช้ยาหลายชนิด

อีกหนึ่งอุปมาที่ชัดเจนสำหรับ NLU ที่อิงตามเจตนา/เอนทิตีคือการสร้างหอคอยจากบล็อก
ในทำนองเดียวกัน ทุกครั้งที่มีการเพิ่มเจตนาใหม่ในระบบ NLU หอคอยบล็อกเชิงเปรียบเทียบก็จะสูงขึ้น ทำให้ความไม่เสถียรเพิ่มขึ้น ความต้องการการเสริมแรงเพิ่มขึ้น ส่งผลให้ต้นทุนการบำรุงรักษาสูงขึ้น ดังนั้น แม้ว่า NLU ที่อิงตามเจตนา/เอนทิตีอาจดูน่าสนใจสำหรับผู้ให้บริการในตอนแรก แต่ความเป็นจริงคือมันกลายเป็นภาระที่มากเกินไปสำหรับลูกค้าในการบำรุงรักษา ระบบเหล่านี้ขาดความสามารถในการปรับขนาด ทำให้เกิดความท้าทายอย่างมากสำหรับทั้งผู้ให้บริการและลูกค้า ในส่วนถัดไป เราจะสำรวจว่า NLU ที่อิงตาม GenAI/LLM นำเสนอทางเลือกที่ยั่งยืนและปรับขนาดได้มากกว่าเพื่อแก้ไขปัญหาเหล่านี้ได้อย่างมีประสิทธิภาพได้อย่างไร
NLU ที่อิงตาม GenAI/LLM: โซลูชันที่ยืดหยุ่น
NLU ที่อิงตาม GenAI/LLM นำเสนอโซลูชันที่แข็งแกร่งสำหรับความท้าทายด้านความสามารถในการปรับขนาดที่ระบบที่อิงตามเจตนา/เอนทิตีต้องเผชิญ สิ่งนี้ส่วนใหญ่มาจากสองปัจจัยหลัก:
-
การฝึกอบรมล่วงหน้าและความรู้โลก: โมเดล GenAI/LLM ได้รับการฝึกอบรมล่วงหน้าด้วยข้อมูลจำนวนมหาศาล ทำให้สามารถสืบทอดความรู้โลกมากมาย ความรู้ที่สะสมนี้มีบทบาทสำคัญในการจำแนกความแตกต่างระหว่างเจตนาต่างๆ ซึ่งช่วยเพิ่มความสามารถในการจำแนกของโมเดลต่อตัวอย่างเชิงลบ
-
การเรียนรู้แบบ Few-Shot: หนึ่งในคุณสมบัติเด่นของ NLU ที่อิงตาม GenAI/LLM คือความสามารถในการใช้เทคนิคการเรียนรู้แบบ few-shot ซึ่งแตกต่างจากวิธีการดั้งเดิมที่ต้องใช้ข้อมูลการฝึกอบรมจำนวนมากสำหรับแต่ละเจตนา การเรียนรู้แบบ few-shot ช่วยให้โมเดลสามารถเรียนรู้จากตัวอย่างเพียงไม่กี่ตัวอย่าง แนวทางการเรียนรู้ที่มีประสิทธิภาพนี้ช่วยเสริมเป้าหมายที่ตั้งใจไว้ด้วยข้อมูลที่น้อยที่สุด ซึ่งช่วยลดภาระการฝึกอบรมได้อย่างมาก
พิจารณาสถานการณ์นี้: เมื่อได้รับคำถามว่า “วันนี้อากาศเป็นอย่างไร?” ในฐานะผู้อ่าน คุณจะรับรู้โดยสัญชาตญาณว่าเป็นคำถามเกี่ยวกับสภาพอากาศท่ามกลางประโยคมากมายที่พบเจอในแต่ละวัน ความสามารถโดยกำเนิดในการจำแนกเจตนานี้คล้ายกับแนวคิดของการเรียนรู้แบบ few-shot
ในฐานะผู้ใหญ่ สมองของเราได้รับการฝึกฝนล่วงหน้าด้วยคำศัพท์จำนวนมาก ซึ่งประมาณ 150 ล้านคำเมื่ออายุ 20 ปี การสัมผัสภาษาที่กว้างขวางนี้ช่วยให้เราเข้าใจเจตนาใหม่ๆ ได้อย่างรวดเร็วเมื่อพบเจอ โดยต้องการเพียงไม่กี่ตัวอย่างเพื่อเสริมแรง
Urban Dictionary เป็นแหล่งข้อมูลที่ยอดเยี่ยมสำหรับการสำรวจตัวอย่างของการเรียนรู้แบบ few-shot ในการปฏิบัติ ซึ่งแสดงให้เห็นถึงประสิทธิภาพในการอำนวยความสะดวกในการทำความเข้าใจอย่างรวดเร็ว
ความสามารถในการเรียนรู้แบบ few-shot ที่มีอยู่ใน NLU ที่อิงตาม GenAI/LLM มีความสำคัญอย่างยิ่งในการลดต้นทุนและเปิดใช้งานความสามารถในการปรับขนาด ด้วยการฝึกอบรมส่วนใหญ่ที่เสร็จสมบูรณ์แล้วในระหว่างการฝึกอบรมล่วงหน้า การปรับแต่งโมเดลด้วยจำนวนตัวอย่างที่น้อยที่สุดจึงกลายเป็นจุดสนใจหลัก ซึ่งช่วยปรับปรุงกระบวนการและเพิ่มความสามารถในการปรับขนาด
NLU ที่อิงตาม GenAI/LLM: การส่งมอบผลลัพธ์และหลักฐาน
ณ เดือนมีนาคม 2567 ภูมิทัศน์ของการประมวลผลภาษาธรรมชาติ (NLP) ได้มีการเปลี่ยนแปลงอย่างมีนัยสำคัญ โดยมี NLU ที่อิงตาม GenAI/LLM เกิดขึ้นในฐานะผู้เปลี่ยนเกม ความก้าวหน้าในการสร้างสรรค์ NLP ที่เคยโดดเด่นได้หยุดนิ่งในช่วง 2-3 ปีที่ผ่านมา ดังที่เห็นได้จากความซบเซาในความก้าวหน้าทางเทคโนโลยี หากคุณตรวจสอบ ความก้าวหน้าของ NLP ที่เคยได้รับความนิยมสูงสุดสำหรับสถานะปัจจุบัน ส่วนใหญ่หยุดนิ่งไปเมื่อ 2-3 ปีที่แล้ว:
เราเคยติดตามนวัตกรรม NLP ใน Github Repo นี้ การอัปเดตส่วนใหญ่หยุดนิ่งไปเมื่อ 2-3 ปีที่แล้ว
หนึ่งในเกณฑ์มาตรฐานที่น่าสังเกตที่เน้นย้ำถึงการเปลี่ยนแปลงกระบวนทัศน์นี้คือ กระดานผู้นำ SuperGlue ซึ่งมีรายการล่าสุดในเดือนธันวาคม 2565 ที่น่าสนใจคือ กรอบเวลานี้ตรงกับการเปิดตัว ChatGPT (3.5) ซึ่งสร้างความตกตะลึงไปทั่วชุมชน NLP
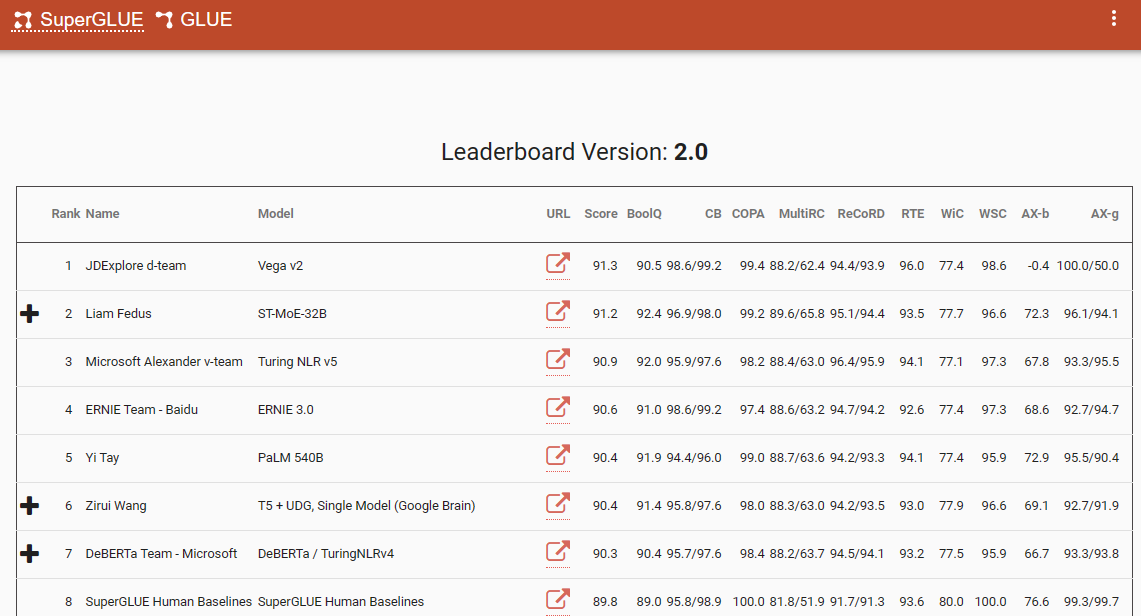
กระดานผู้นำ SuperGlue เป็นที่นิยมจนกระทั่งมีการเปิดตัว ChatGPT
บทความสำคัญของ GPT-3 ซึ่งมีชื่อว่า “โมเดลภาษาคือผู้เรียนแบบ Few-Shot” นำเสนอหลักฐานที่น่าเชื่อถือถึงประสิทธิภาพของการเรียนรู้แบบ few-shot รูปที่ 2.1 ในหน้า 7 ของบทความระบุความแตกต่างระหว่างแนวทางการเรียนรู้แบบ zero-shot, one-shot และ few-shot โดยเน้นย้ำถึงความเหนือกว่าของแนวทางหลังในแง่ของประสิทธิภาพและประสิทธิผลของการเรียนรู้

ความแตกต่างระหว่างแนวทางการเรียนรู้แบบ zero-shot, one-shot และ few-shot
นอกจากนี้ เพื่อยืนยันประสิทธิภาพของ NLU ที่อิงตาม GenAI/LLM ตารางที่ 3.8 ในหน้า 19 ได้ให้การเปรียบเทียบโดยตรงระหว่างวิธีการ NLU แบบมีผู้ดูแลแบบดั้งเดิมกับการเรียนรู้แบบ Few-Shot ของ GPT-3 ในการเปรียบเทียบนี้ GPT-3 Few-Shot เหนือกว่า Fine-tuned BERT-Large ซึ่งเป็นการแสดงถึงการเรียนรู้แบบมีผู้ดูแลที่ใช้โดยระบบ NLU ที่อิงตามเจตนา/เอนทิตี ในงานต่างๆ
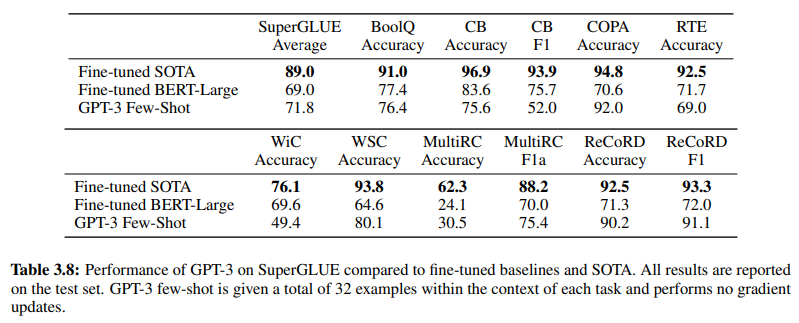
GPT-3 Few-Shot เหนือกว่า Fine-tuned BERT-Large ในงานต่างๆ
ความเหนือกว่าของ GPT-3 Few-Shot ไม่เพียงแต่ชัดเจนในความแม่นยำเท่านั้น แต่ยังรวมถึงประสิทธิภาพด้านต้นทุนด้วย ทั้งการตั้งค่าเริ่มต้นและต้นทุนการบำรุงรักษาที่เกี่ยวข้องกับ NLU ที่อิงตาม GenAI/LLM นั้นต่ำกว่าวิธีการดั้งเดิมอย่างมาก
หลักฐานเชิงประจักษ์ที่นำเสนอในชุมชน NLP เน้นย้ำถึงผลกระทบที่เปลี่ยนแปลงของ NLU ที่อิงตาม GenAI/LLM ได้แสดงให้เห็นถึงความแม่นยำและประสิทธิภาพที่ไม่มีใครเทียบได้แล้ว ถัดไป เราจะตรวจสอบประสิทธิภาพด้านต้นทุน
ข้อกำหนดข้อมูลการฝึกอบรม: การวิเคราะห์เชิงเปรียบเทียบ
การเปรียบเทียบที่เปิดเผยระหว่าง NLU ที่อิงตามเจตนา/เอนทิตี และ NLU ที่อิงตาม GenAI/LLM เผยให้เห็นถึงข้อกำหนดข้อมูลการฝึกอบรมที่แตกต่างกัน รูปที่ 3.8 ในหน้า 20 แสดงความแตกต่างที่ชัดเจน:
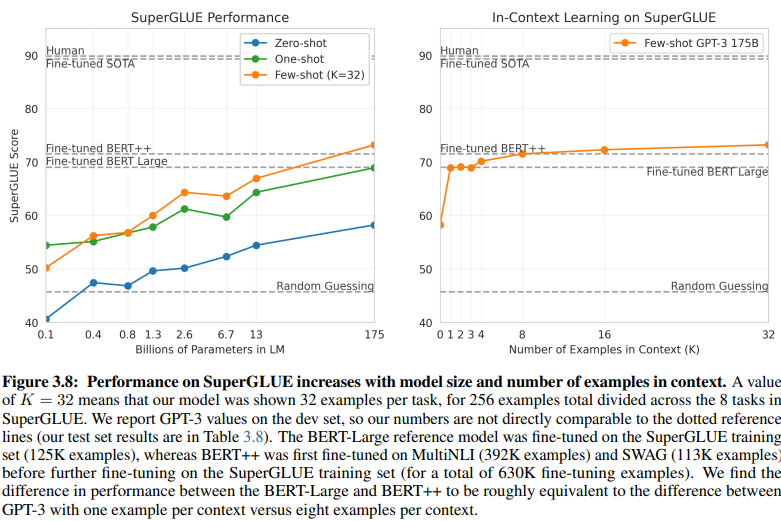
NLU ที่อิงตาม GenAI/LLM ต้องการข้อมูลน้อยกว่ามากสำหรับการฝึกอบรม
-
NLU การเรียนรู้แบบมีผู้ดูแล: แนวทางดั้งเดิมนี้ต้องการชุดข้อมูลที่กว้างขวาง โดยมีตัวอย่างมากกว่าครึ่งล้าน (630K) ที่จำเป็นสำหรับการฝึกอบรมที่มีประสิทธิภาพ
-
GPT-3 Few-Shot: ในทางตรงกันข้าม NLU ที่อิงตาม GenAI/LLM แสดงให้เห็นถึงประสิทธิภาพที่โดดเด่น โดยมีเพียง 32 ตัวอย่างต่อภารกิจก็เพียงพอสำหรับการปรับแต่งที่มีประสิทธิภาพ
ขนาดของความแตกต่างนี้โดดเด่น: 630,000 ตัวอย่างเทียบกับเพียง 32 ตัวอย่าง การลดลงอย่างมากในข้อกำหนดข้อมูลการฝึกอบรมนี้ส่งผลให้ประหยัดต้นทุนได้อย่างมากสำหรับธุรกิจที่นำ NLU ที่อิงตาม GenAI/LLM มาใช้
นอกจากนี้ ผลกระทบโดยนัยต่อไทม์ไลน์การพัฒนาลึกซึ้งมาก ด้วย NLU ที่อิงตาม GenAI/LLM กระบวนการฝึกอบรมที่สั้นลงจะเร่งการปรับใช้ระบบ NLU ด้วยปัจจัยขนาดหลายเท่า อำนวยความสะดวกในการปรับตัวและนวัตกรรมอย่างรวดเร็วในขอบเขตของการประมวลผลภาษาธรรมชาติ
โดยสรุป การเปรียบเทียบนี้เน้นย้ำถึงศักยภาพในการเปลี่ยนแปลงของ NLU ที่อิงตาม GenAI/LLM ซึ่งนำเสนอประสิทธิภาพและประสิทธิผลด้านต้นทุนที่ไม่มีใครเทียบได้ในข้อกำหนดข้อมูลการฝึกอบรมและไทม์ไลน์การพัฒนา
การยอมรับวิวัฒนาการ: เหตุใด NLU ที่อิงตาม GenAI/LLM จึงมีชัย
ในขอบเขตของการทำความเข้าใจภาษาธรรมชาติ การเปลี่ยนจากระบบที่อิงตามเจตนา/เอนทิตีไปสู่โซลูชันที่อิงตาม GenAI/LLM กำลังดำเนินไปอย่างไม่มีข้อโต้แย้ง การเปลี่ยนแปลงนี้ขับเคลื่อนโดยปัจจัยหลายประการที่เน้นย้ำถึงข้อจำกัดของ NLU ที่อิงตามเจตนา/เอนทิตีแบบดั้งเดิม และข้อได้เปรียบที่น่าสนใจที่นำเสนอโดยแนวทางที่อิงตาม GenAI/LLM
NLU ที่อิงตามเจตนา/เอนทิตีถูกมองว่าล้าสมัยมากขึ้นเรื่อยๆ ด้วยเหตุผลที่น่าสนใจหลายประการ:
-
ความยืดหยุ่นที่จำกัด: ระบบ NLU แบบดั้งเดิมขึ้นอยู่กับเจตนาและเอนทิตีที่กำหนดไว้ล่วงหน้า ซึ่งจำกัดความสามารถในการปรับตัวของแชทบอทและ IVR ต่อข้อมูลที่ผู้ใช้ป้อนซึ่งเบี่ยงเบนไปจากหมวดหมู่ที่กำหนดไว้ล่วงหน้าเหล่านี้
-
ความท้าทายในการบำรุงรักษา: เมื่อระบบเหล่านี้ปรับขนาดและจำนวนเจตนาและเอนทิตีเพิ่มขึ้น ความซับซ้อนและเวลาที่จำเป็นสำหรับการบำรุงรักษาและการอัปเดตจะเพิ่มขึ้นอย่างทวีคูณ
-
การขาดความเข้าใจตามบริบท: ระบบเหล่านี้มักจะล้มเหลวในการทำความเข้าใจความแตกต่างทางบริบทที่ซับซ้อนของการสนทนา ส่งผลให้เกิดการตอบสนองที่ไม่ถูกต้อง หรือความจำเป็นในการป้อนข้อมูลเพิ่มเติมจากผู้ใช้เพื่อชี้แจงเจตนา
-
การขาดการสร้าง: ระบบ NLU ที่อิงตามเจตนาและเอนทิตีมีข้อจำกัดโดยธรรมชาติในความสามารถในการสร้างข้อความ ซึ่งจำกัดให้ทำงานที่เน้นการจำแนกเจตนาและการแยกเอนทิตี สิ่งนี้จำกัดความสามารถในการปรับตัวของแชทบอทและ IVR ซึ่งมักนำไปสู่การตอบสนองที่ซ้ำซากจำเจซึ่งไม่สอดคล้องกับบริบทการสนทนา
ในทางตรงกันข้าม NLU ที่อิงตาม GenAI/LLM กลายเป็นเทรนด์ที่โดดเด่นเนื่องจากคุณสมบัติที่เปลี่ยนแปลงไป:
-
การเรียนรู้แบบปรับตัว: โมเดล GenAI มีความสามารถในการเรียนรู้แบบไดนามิกจากการสนทนาแบบเรียลไทม์ ทำให้สามารถปรับตัวเข้ากับหัวข้อใหม่ๆ และพฤติกรรมของผู้ใช้ได้โดยอัตโนมัติ โดยไม่จำเป็นต้องอัปเดตด้วยตนเอง
-
ความเข้าใจตามบริบท: โมเดลเหล่านี้มีความโดดเด่นในการทำความเข้าใจความแตกต่างทางบริบทที่ซับซ้อนของการสนทนา ส่งผลให้เกิดการตอบสนองที่แม่นยำและเกี่ยวข้องมากขึ้นซึ่งสอดคล้องกับผู้ใช้
-
การเรียนรู้แบบ Few-Shot: โมเดล GenAI สามารถฝึกอบรมด้วยตัวอย่างที่น้อยที่สุด ซึ่งช่วยปรับปรุงกระบวนการฝึกอบรมและลดการพึ่งพาคำจำกัดความของเจตนาและเอนทิตีที่ชัดเจน
-
การสร้างภาษาธรรมชาติ: GenAI/LLM มีความสามารถในการสร้างข้อความ ซึ่งช่วยให้สามารถสร้างแชทบอทและแอปพลิเคชัน NLP อื่นๆ ที่ให้การตอบสนองที่เป็นธรรมชาติและเกี่ยวข้องกับบริบท
อนาคตของ AI การสนทนาขึ้นอยู่กับระบบที่สามารถเรียนรู้และปรับตัวได้อย่างเป็นธรรมชาติ ซึ่งมอบประสบการณ์ที่ราบรื่นและใช้งานง่ายให้กับผู้ใช้ NLU ที่อิงตาม GenAI/LLM รวบรวมวิวัฒนาการนี้ โดยนำเสนอแนวทางแบบไดนามิกและยืดหยุ่นที่ก้าวข้ามข้อจำกัดของระบบที่อิงตามเจตนา/เอนทิตีแบบดั้งเดิม
โดยสรุป วิถีที่โดดเด่นของ NLU ถูกกำหนดไว้อย่างชัดเจนโดยการเพิ่มขึ้นของแนวทางที่อิงตาม GenAI/LLM ซึ่งเป็นจุดเริ่มต้นของยุคใหม่ของ AI การสนทนาที่ให้ความสำคัญกับการปรับตัว ความเกี่ยวข้องกับบริบท และการมุ่งเน้นผู้ใช้เป็นศูนย์กลาง


