





An alle Direktoren für Kundenservice oder Marketing: Wenn Ihr Chef Ihnen die folgende Frage stellt, senden Sie ihm diesen Artikel:
“Warum ist Intent/Entity-basiertes NLU veraltet und LLM/GenAI der offensichtliche Trend?”
Natural Language Understanding (NLU)-Systeme zielen darauf ab, natürliche Sprachinputs wie Text oder Sprache zu verarbeiten und zu analysieren, um Bedeutung abzuleiten, relevante Informationen zu extrahieren und die zugrunde liegende Absicht hinter der Kommunikation zu verstehen. NLU ist eine grundlegende Komponente verschiedener KI-Anwendungen, darunter virtuelle Assistenten, Chatbots, Tools zur Stimmungsanalyse, Sprachübersetzungssysteme und vieles mehr. Es spielt eine entscheidende Rolle bei der Ermöglichung der Mensch-Computer-Interaktion und der Erleichterung der Entwicklung intelligenter Systeme, die natürliche Sprachinputs verstehen und darauf reagieren können.
Diese Frage kommt von etablierten Kunden, die ihren IVR- und Chatbot-Ansatz überdenken. Sie sind an die vorherige Generation der NLU-basierten Tech-Stacks gebunden, die normalerweise von großen Technologieunternehmen wie Microsoft Bot Framework (oder luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU angeboten werden.
Die Herausforderung besteht darin, dass große Kunden wie Versicherungsgesellschaften, Finanzinstitute, Regierungen, Fluggesellschaften/Autohändler und andere große Unternehmen bereits die Technologie der letzten Generation eingesetzt haben. Da das Intent/Entity-basierte NLU jedoch nicht skalierbar ist, müssen Kunden jedes Jahr Hunderttausende bis Millionen von Dollar für die Wartung und Aktualisierung ihres NLU-Systems ausgeben. Dieser Mangel an Skalierbarkeit trägt zu steigenden Wartungskosten bei, was letztendlich den NLU-Anbietern der letzten Generation auf Kosten ihrer Kunden zugutekommt. Da sie nicht skalieren, steigen die Wartungskosten von Jahr zu Jahr.
Warum scheitert Intent/Entity-basiertes NLU an einer effektiven Skalierung?
Der Hauptgrund liegt in der begrenzten Diskriminierungsfähigkeit des Modells. Hier ist eine Aufschlüsselung, warum dies der Fall ist:
-
Mindestanforderungen an Intents: NLU-Modelle benötigen mindestens zwei unterschiedliche Intents, um effektiv trainiert zu werden. Wenn beispielsweise nach dem Wetter gefragt wird, mag die Absicht klar sein, aber jeder Abfrage liegen mehrere potenzielle Absichten zugrunde, wie z. B. ein Fallback oder nicht wetterbezogene Anfragen wie „Wie geht es Ihnen?“
-
Anforderungen an Trainingsdaten: Große Technologieunternehmen benötigen typischerweise Tausende von positiven Beispielen pro Intent für ein effektives Training. Dieser umfangreiche Datensatz ist notwendig, damit das Modell verschiedene Intents genau lernen und unterscheiden kann.
-
Ausgleich von positiven und negativen Beispielen: Das Hinzufügen positiver Beispiele zu einem Intent erfordert die Aufnahme negativer Beispiele für andere Intents. Dieser ausgewogene Ansatz stellt sicher, dass das NLU-Modell sowohl aus positiven als auch aus negativen Instanzen effektiv lernen kann.
-
Vielfältige Beispielsätze: Sowohl positive als auch negative Beispiele müssen vielfältig sein, um Overfitting zu vermeiden und die Fähigkeit des Modells zu verbessern, über verschiedene Kontexte hinweg zu generalisieren.
-
Komplexität beim Hinzufügen neuer Intents: Das Hinzufügen eines neuen Intents zu einem bestehenden NLU-Modell ist ein mühsamer Prozess. Tausende von positiven und negativen Beispielen müssen hinzugefügt werden, gefolgt von einem erneuten Training des Modells, um seine Basisleistung aufrechtzuerhalten. Dieser Prozess wird mit zunehmender Anzahl von Intents immer schwieriger.
Der Verschreibungseffekt: Die Falle des Intent/Entity-basierten NLU

Der Verschreibungseffekt des Intent/Entity-basierten NLU
Analog zum Phänomen in der Medizin, bekannt als „Verschreibungskaskade“, können die Skalierbarkeitsprobleme des Intent/Entity-basierten NLU mit einer beängstigenden Kaskade von Verschreibungen verglichen werden. Stellen Sie sich eine ältere Person vor, die mit einer Vielzahl täglicher Medikamente belastet ist, wobei jedes Medikament verschrieben wird, um die Nebenwirkungen des vorherigen zu behandeln. Dieses Szenario ist nur allzu bekannt, wo die Einführung von Medikament A zu Nebenwirkungen führt, die die Verschreibung von Medikament B zur Gegenwirkung erforderlich machen. Medikament B führt jedoch seine eigenen Nebenwirkungen ein, was die Notwendigkeit von Medikament C usw. nach sich zieht. Folglich findet sich die ältere Person mit einem Berg von Pillen wieder, die sie verwalten muss – eine Verschreibungskaskade.
Eine weitere anschauliche Metapher ist die des Bauens eines Turms aus Bauklötzen, wobei jeder Bauklotz ein Medikament darstellt. Zunächst wird Medikament A platziert, aber seine Instabilität (Nebenwirkungen) führt zur Zugabe von Medikament B, um es zu stabilisieren. Diese neue Ergänzung lässt sich jedoch möglicherweise nicht nahtlos integrieren, wodurch der Turm weiter kippt (Nebenwirkung von B). Um diese Instabilität zu beheben, werden weitere Bauklötze (Medikamente C, D usw.) hinzugefügt, was die Instabilität des Turms und seine Anfälligkeit für den Zusammenbruch verschärft – eine Darstellung der potenziellen gesundheitlichen Komplikationen, die sich aus mehreren Medikamenten ergeben.

Eine weitere anschauliche Metapher für Intent/Entity-basiertes NLU ist der Bau eines Turms aus Bauklötzen
Ähnlich wächst mit jedem neuen Intent, der einem NLU-System hinzugefügt wird, der metaphorische Turm aus Bauklötzen höher, was die Instabilität erhöht. Der Bedarf an Verstärkung steigt, was zu höheren Wartungskosten führt. Folglich mag Intent/Entity-basiertes NLU für Anbieter zunächst attraktiv erscheinen, die Realität ist jedoch, dass es für Kunden übermäßig aufwendig wird, es zu warten. Diese Systeme sind nicht skalierbar und stellen sowohl Anbieter als auch Kunden vor erhebliche Herausforderungen. In den folgenden Abschnitten werden wir untersuchen, wie GenAI/LLM-basiertes NLU eine nachhaltigere und skalierbarere Alternative bietet, um diese Herausforderungen effektiv zu bewältigen.
GenAI/LLM-basiertes NLU: Eine robuste Lösung
GenAI/LLM-basiertes NLU bietet eine robuste Lösung für die Skalierbarkeitsprobleme, mit denen Intent/Entity-basierte Systeme konfrontiert sind. Dies ist hauptsächlich auf zwei Schlüsselfaktoren zurückzuführen:
-
Vortraining und Weltwissen: GenAI/LLM-Modelle werden auf riesigen Datenmengen vortrainiert, wodurch sie eine Fülle von Weltwissen erben können. Dieses angesammelte Wissen spielt eine entscheidende Rolle bei der Unterscheidung zwischen verschiedenen Intents und verbessert dadurch die Diskriminierungsfähigkeiten des Modells gegenüber negativen Beispielen.
-
Few-Shot Learning: Eines der herausragenden Merkmale des GenAI/LLM-basierten NLU ist seine Fähigkeit, Few-Shot-Learning-Techniken einzusetzen. Im Gegensatz zu traditionellen Methoden, die umfangreiche Trainingsdaten für jeden Intent erfordern, ermöglicht Few-Shot Learning dem Modell, aus nur wenigen Beispielen zu lernen. Dieser effiziente Lernansatz verstärkt die beabsichtigten Ziele mit minimalen Daten, wodurch der Trainingsaufwand erheblich reduziert wird.
Betrachten Sie dieses Szenario: Wenn Ihnen die Frage „Wie ist das Wetter heute?“ als Leser gestellt wird, erkennen Sie instinktiv, dass es sich um eine Anfrage zum Wetter handelt, inmitten der Vielzahl von Sätzen, denen Sie täglich begegnen. Diese angeborene Fähigkeit, die Absicht zu erkennen, ähnelt dem Konzept des Few-Shot Learning.
Als Erwachsene sind unsere Gehirne mit einem riesigen Wortschatz vortrainiert, der bis zum Alter von 20 Jahren auf etwa 150 Millionen Wörter geschätzt wird. Diese umfassende sprachliche Exposition ermöglicht es uns, neue Absichten schnell zu erfassen, sobald wir ihnen begegnen, wobei nur wenige Beispiele zur Verstärkung erforderlich sind.
Das Urban Dictionary dient als hervorragende Ressource, um Beispiele für Few-Shot Learning in Aktion zu erkunden und seine Wirksamkeit bei der Erleichterung eines schnellen Verständnisses weiter zu veranschaulichen.
Die im GenAI/LLM-basierten NLU inhärente Few-Shot-Learning-Fähigkeit ist entscheidend für die Kostensenkung und die Ermöglichung der Skalierbarkeit. Da der Großteil des Trainings bereits während des Vortrainings abgeschlossen ist, wird die Feinabstimmung des Modells mit einer minimalen Anzahl von Beispielen zum Hauptaugenmerk, wodurch der Prozess rationalisiert und die Skalierbarkeit verbessert wird.
GenAI/LLM-basiertes NLU: Ergebnisse und Beweise liefern
Ab März 2024 hat sich die Landschaft der natürlichen Sprachverarbeitung (NLP) erheblich verändert, gekennzeichnet durch das Aufkommen von GenAI/LLM-basiertem NLU als Game-Changer. Der einst dominierende Fortschritt in der NLP-Innovation stagnierte in den letzten 2-3 Jahren, wie die Stagnation der State-of-the-Art-Fortschritte zeigt. Wenn Sie den einst heißesten NLP-Fortschritt für den Stand der Technik überprüfen, so stoppte er größtenteils vor 2-3 Jahren:
Wir haben früher den NLP-Fortschritt in diesem Github-Repo verfolgt. Die Aktualisierung wurde größtenteils vor 2-3 Jahren eingestellt.
Ein bemerkenswerter Benchmark, der diesen Paradigmenwechsel unterstreicht, ist die SuperGlue-Bestenliste mit ihrem letzten Eintrag im Dezember 2022. Interessanterweise fällt dieser Zeitraum mit der Einführung von ChatGPT (3.5) zusammen, das die NLP-Community schockierte.
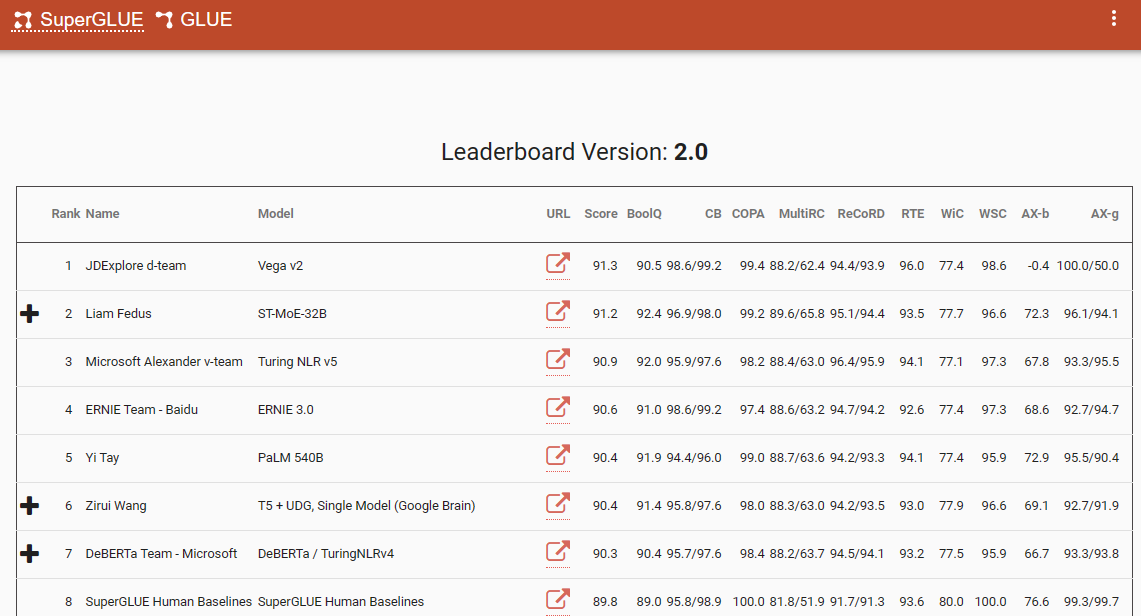
Die SuperGlue-Bestenliste war bis zur Einführung von ChatGPT beliebt
Das wegweisende GPT-3-Papier mit dem treffenden Titel „Sprachmodelle sind Few-Shot-Learner“ liefert überzeugende Beweise für die Wirksamkeit des Few-Shot-Learnings. Abbildung 2.1 auf Seite 7 des Papiers beschreibt die Unterschiede zwischen Zero-Shot-, One-Shot- und Few-Shot-Lernansätzen und hebt die Überlegenheit letzterer in Bezug auf Lerneffizienz und -effektivität hervor.

Die Unterschiede zwischen Zero-Shot-, One-Shot- und Few-Shot-Lernansätzen
Die Wirksamkeit des GenAI/LLM-basierten NLU wird zusätzlich durch Tabelle 3.8 auf Seite 19 bestätigt, die einen direkten Vergleich zwischen traditionellen überwachten NLU-Methoden und dem GPT-3 Few-Shot-Learning bietet. In diesem Vergleich übertrifft GPT-3 Few-Shot das feinabgestimmte BERT-Large, eine Darstellung des überwachten Lernens, das von Intent/Entity-basierten NLU-Systemen verwendet wird, bei verschiedenen Aufgaben.
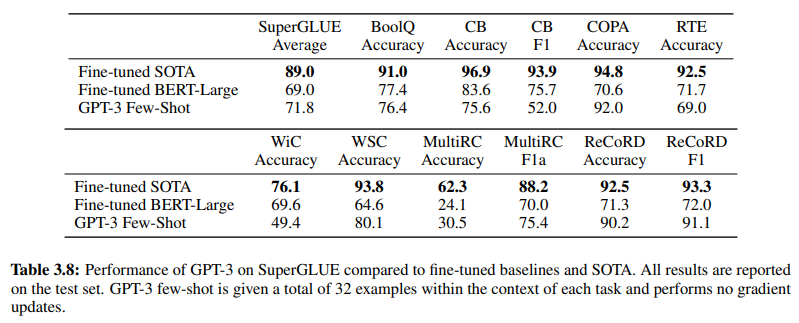
GPT-3 Few-Shot übertrifft feinabgestimmtes BERT-Large bei verschiedenen Aufgaben
Die Überlegenheit von GPT-3 Few-Shot zeigt sich nicht nur in seiner Genauigkeit, sondern auch in seiner Kosteneffizienz. Sowohl die anfänglichen Einrichtungs- als auch die Wartungskosten, die mit GenAI/LLM-basiertem NLU verbunden sind, sind im Vergleich zu herkömmlichen Methoden erheblich geringer.
Die in der NLP-Community präsentierten empirischen Beweise unterstreichen die transformative Wirkung des GenAI/LLM-basierten NLU. Es hat bereits seine unübertroffene Genauigkeit und Effizienz unter Beweis gestellt. Als Nächstes werden wir seine Kosteneffizienz überprüfen.
Anforderungen an Trainingsdaten: Eine vergleichende Analyse
Ein aufschlussreicher Vergleich zwischen Intent/Entity-basiertem NLU und GenAI/LLM-basiertem NLU beleuchtet deren unterschiedliche Anforderungen an Trainingsdaten. Abbildung 3.8 auf Seite 20 zeigt einen deutlichen Kontrast:
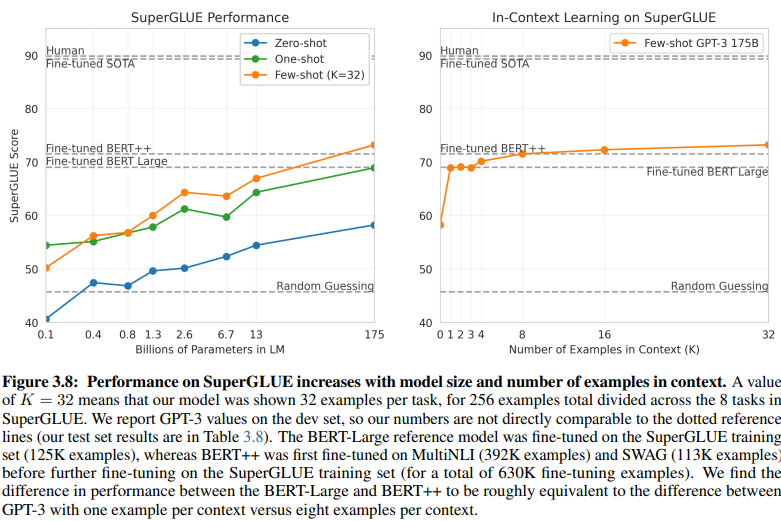
GenAI/LLM-basiertes NLU benötigt deutlich weniger Daten für das Training
-
Überwachtes Lernen NLU: Dieser traditionelle Ansatz erfordert einen umfangreichen Datensatz, wobei über eine halbe Million Beispiele (630.000) für ein effektives Training erforderlich sind.
-
Few-Shot GPT-3: Im Gegensatz dazu zeigt GenAI/LLM-basiertes NLU eine bemerkenswerte Effizienz, wobei nur 32 Beispiele pro Aufgabe für eine effektive Feinabstimmung ausreichen.
Das Ausmaß dieses Unterschieds ist frappierend: 630.000 Beispiele gegenüber nur 32. Diese drastische Reduzierung der Anforderungen an Trainingsdaten führt zu erheblichen Kosteneinsparungen für Unternehmen, die GenAI/LLM-basiertes NLU einführen.
Darüber hinaus sind die impliziten Auswirkungen auf die Entwicklungszeiten tiefgreifend. Mit GenAI/LLM-basiertem NLU beschleunigt der verkürzte Trainingsprozess die Bereitstellung von NLU-Systemen um ein Vielfaches, was eine schnelle Anpassung und Innovation im Bereich der natürlichen Sprachverarbeitung ermöglicht.
Im Wesentlichen unterstreicht dieser Vergleich das transformative Potenzial des GenAI/LLM-basierten NLU, das eine unübertroffene Effizienz und Kosteneffizienz bei den Anforderungen an Trainingsdaten und den Entwicklungszeiten bietet.
Die Evolution annehmen: Warum GenAI/LLM-basiertes NLU vorherrscht
Im Bereich des Natural Language Understanding (NLU) ist der Übergang von Intent/Entity-basierten Systemen zu GenAI/LLM-basierten Lösungen unbestreitbar im Gange. Dieser Wandel wird durch eine Vielzahl von Faktoren vorangetrieben, die die Einschränkungen des traditionellen Intent/Entity-basierten NLU und die überzeugenden Vorteile der GenAI/LLM-basierten Ansätze unterstreichen.
Intent/Entity-basiertes NLU wird aus mehreren überzeugenden Gründen zunehmend als veraltet angesehen:
-
Begrenzte Flexibilität: Traditionelle NLU-Systeme basieren auf vordefinierten Intents und Entities, was die Anpassungsfähigkeit von Chatbots und IVRs an Benutzereingaben einschränkt, die von diesen vordefinierten Kategorien abweichen.
-
Wartungsherausforderungen: Mit der Skalierung dieser Systeme und der Zunahme der Anzahl von Intents und Entities steigen die Komplexität und der Zeitaufwand für Wartung und Updates exponentiell.
-
Mangelndes Kontextverständnis: Diese Systeme scheitern oft daran, die komplexen kontextuellen Nuancen von Gesprächen zu erfassen, was zu ungenauen Antworten oder der Notwendigkeit zusätzlicher Benutzereingaben zur Klärung von Absichten führt.
-
Mangelnde Generierung: Intent- und Entity-basierte NLU-Systeme sind von Natur aus in ihrer Fähigkeit zur Textgenerierung begrenzt, was sie auf Aufgaben beschränkt, die sich auf die Klassifizierung von Intents und die Extraktion von Entities konzentrieren. Dies schränkt die Anpassungsfähigkeit von Chatbots und IVRs ein und führt oft zu monotonen Antworten, die nicht zum Gesprächskontext passen.
Im krassen Gegensatz dazu erweist sich GenAI/LLM-basiertes NLU aufgrund seiner transformativen Eigenschaften als vorherrschender Trend:
-
Adaptives Lernen: GenAI-Modelle besitzen die Fähigkeit, dynamisch aus Echtzeitgesprächen zu lernen, wodurch sie sich autonom an neue Themen und Benutzerverhalten anpassen können, ohne manuelle Updates zu erfordern.
-
Kontextuelles Verständnis: Diese Modelle zeichnen sich durch das Verständnis der komplexen kontextuellen Nuancen von Gesprächen aus, was zu präziseren und relevanteren Antworten führt, die bei den Benutzern Anklang finden.
-
Few-Shot Learning: GenAI-Modelle können mit minimalen Beispielen trainiert werden, was den Trainingsprozess rationalisiert und die Abhängigkeit von expliziten Intent- und Entity-Definitionen reduziert.
-
Natürliche Sprachgenerierung: GenAI/LLMs verfügen über die Fähigkeit, Text zu generieren, wodurch sie Chatbots und andere NLP-Anwendungen erstellen können, die natürliche und kontextuell relevante Antworten liefern.
Die Zukunft der Konversations-KI hängt von Systemen ab, die organisch lernen und sich anpassen können und den Benutzern ein nahtloses und intuitives Erlebnis bieten. GenAI/LLM-basiertes NLU verkörpert diese Entwicklung und bietet einen dynamischen und flexiblen Ansatz, der die Einschränkungen traditioneller Intent/Entity-basierter Systeme überwindet.
Im Wesentlichen wird die vorherrschende Entwicklung des NLU unmissverständlich durch den Aufstieg der GenAI/LLM-basierten Ansätze definiert, die eine neue Ära der Konversations-KI einläuten, die Anpassungsfähigkeit, Kontextualität und Benutzerzentrierung priorisiert.


