





به همه مدیران خدمات مشتری یا بازاریابی، اگر رئیس شما سوال زیر را از شما پرسید، این مقاله را برای آنها ارسال کنید:
“چرا NLU مبتنی بر قصد/موجودیت منسوخ شده است و LLM/GenAI روند آشکار است؟”
سیستمهای فهم زبان طبیعی (NLU) با هدف پردازش و تحلیل ورودیهای زبان طبیعی، مانند متن یا گفتار، برای استخراج معنا، استخراج اطلاعات مرتبط و درک قصد اصلی پشت ارتباط. NLU یک جزء اساسی از برنامههای کاربردی مختلف هوش مصنوعی است، از جمله دستیارهای مجازی، چتباتها، ابزارهای تحلیل احساسات، سیستمهای ترجمه زبان و موارد دیگر. این سیستم نقش مهمی در فعال کردن تعامل انسان و رایانه و تسهیل توسعه سیستمهای هوشمند قادر به درک و پاسخ به ورودیهای زبان طبیعی ایفا میکند.
این سوال از مشتریان تثبیت شده ای می آید که رویکرد IVR و چت بات خود را دوباره بررسی می کنند. آنها به نسل قبلی از پشته فناوری مبتنی بر NLU محدود شده اند که معمولاً توسط بازیگران بزرگ فناوری مانند: Microsoft Bot Framework (یا luis.ai), IBM Watson NLU، Google DialogFlow، Meta’s wit.ai، Amazon Lex، SAP Conversational AI، Nuance Mix NLU ارائه می شود.
چالش این است که مشتریان اصلی مانند شرکتهای بیمه، موسسات مالی، دولتها، خطوط هوایی/نمایندگیهای خودرو و سایر معاملات بزرگ، قبلاً فناوری نسل گذشته را مستقر کردهاند. اما از آنجایی که NLU مبتنی بر قصد/موجودیت مقیاسپذیر نیست، مشتریان باید هر سال صدها هزار تا میلیونها دلار برای نگهداری و ارتقاء سیستم NLU خود هزینه کنند. این عدم مقیاسپذیری به افزایش هزینههای نگهداری کمک میکند و در نهایت به نفع ارائهدهندگان NLU نسل گذشته به ضرر مشتریانشان است. از آنجایی که آنها مقیاسپذیر نیستند، هزینه نگهداری سال به سال بالاتر میرود.
چرا NLU مبتنی بر قصد/موجودیت در مقیاسبندی مؤثر شکست میخورد؟
دلیل اصلی در قدرت تمایز محدود مدل نهفته است. در اینجا به تفکیک دلیل این امر میپردازیم:
-
حداقل نیاز به قصد: مدلهای NLU برای آموزش مؤثر به حداقل دو قصد متمایز نیاز دارند. به عنوان مثال، هنگام پرسیدن در مورد آب و هوا، قصد ممکن است واضح باشد، اما در زیر هر پرس و جو، چندین قصد بالقوه وجود دارد، مانند یک بازگشت یا پرس و جوهای غیر مرتبط با آب و هوا مانند “حال شما چطور است؟”
-
نیاز به دادههای آموزشی: شرکتهای بزرگ فناوری معمولاً برای آموزش مؤثر، هزاران مثال مثبت برای هر قصد نیاز دارند. این مجموعه داده گسترده برای یادگیری مدل و تمایز دقیق بین قصدهای مختلف ضروری است.
-
تعادل بین مثالهای مثبت و منفی: افزودن مثالهای مثبت به یک قصد، مستلزم گنجاندن مثالهای منفی برای قصدهای دیگر است. این رویکرد متعادل تضمین میکند که مدل NLU میتواند به طور مؤثر از هر دو نمونه مثبت و منفی یاد بگیرد.
-
مجموعههای مثال متنوع: هم مثالهای مثبت و هم منفی باید متنوع باشند تا از بیشبرازش جلوگیری شود و توانایی مدل در تعمیم در زمینههای مختلف افزایش یابد.
-
پیچیدگی افزودن قصدهای جدید: افزودن یک قصد جدید به یک مدل NLU موجود، فرآیندی پر زحمت است. هزاران مثال مثبت و منفی باید اضافه شود و سپس مدل برای حفظ عملکرد پایه خود دوباره آموزش داده شود. این فرآیند با افزایش تعداد قصدهای جدید، به طور فزایندهای چالشبرانگیز میشود.
اثر تجویز: دام NLU مبتنی بر قصد/موجودیت

اثر تجویز NLU مبتنی بر قصد/موجودیت
مشابه پدیدهای در پزشکی که به عنوان “آبشار تجویز” شناخته میشود، چالشهای مقیاسپذیری NLU مبتنی بر قصد/موجودیت را میتوان به آبشار ترسناکی از تجویزها تشبیه کرد. فردی مسن را تصور کنید که با انبوهی از داروهای روزانه دست و پنجه نرم میکند، که هر کدام برای رفع عوارض جانبی داروی قبلی تجویز شدهاند. این سناریو بسیار آشناست، جایی که معرفی داروی A منجر به عوارض جانبی میشود که نیاز به تجویز داروی B برای مقابله با آنها را ایجاب میکند. با این حال، داروی B مجموعه عوارض جانبی خاص خود را معرفی میکند که نیاز به داروی C و غیره را برمیانگیزد. در نتیجه، فرد مسن خود را غرق در انبوهی از قرصها برای مدیریت مییابد - یک آبشار تجویز.
استعاره گویا دیگر، ساختن برجی از بلوکها است که هر بلوک نشاندهنده یک دارو است. در ابتدا، داروی A قرار داده میشود، اما ناپایداری آن (عوارض جانبی) باعث اضافه شدن داروی B برای تثبیت آن میشود. با این حال، این افزودنی جدید ممکن است به طور یکپارچه ادغام نشود و باعث شود برج بیشتر کج شود (عوارض جانبی B). در تلاش برای اصلاح این ناپایداری، بلوکهای بیشتری (داروهای C، D و غیره) اضافه میشوند که ناپایداری برج و آسیبپذیری آن در برابر فروپاشی را تشدید میکند - نمایشی از عوارض بهداشتی بالقوه ناشی از داروهای متعدد.

استعاره گویا دیگر برای NLU مبتنی بر قصد/موجودیت، ساختن برجی از بلوکها است
به طور مشابه، با هر قصد جدیدی که به یک سیستم NLU اضافه میشود، برج استعاری بلوکها بلندتر میشود و ناپایداری را افزایش میدهد. نیاز به تقویت افزایش مییابد که منجر به افزایش هزینههای نگهداری میشود. در نتیجه، در حالی که NLU مبتنی بر قصد/موجودیت ممکن است در ابتدا برای ارائهدهندگان جذاب به نظر برسد، واقعیت این است که نگهداری آن برای مشتریان بیش از حد سنگین میشود. این سیستمها فاقد مقیاسپذیری هستند و چالشهای قابل توجهی را برای ارائهدهندگان و مشتریان به طور یکسان ایجاد میکنند. در بخشهای بعدی، بررسی خواهیم کرد که چگونه NLU مبتنی بر GenAI/LLM جایگزینی پایدارتر و مقیاسپذیرتر برای مقابله مؤثر با این چالشها ارائه میدهد.
NLU مبتنی بر GenAI/LLM: یک راهحل انعطافپذیر
NLU مبتنی بر GenAI/LLM راهحلی قوی برای چالشهای مقیاسپذیری است که سیستمهای مبتنی بر قصد/موجودیت با آن مواجه هستند. این امر عمدتاً به دو عامل کلیدی نسبت داده میشود:
-
پیشآموزش و دانش جهانی: مدلهای GenAI/LLM بر روی مقادیر عظیمی از دادهها پیشآموزش داده میشوند و به آنها امکان میدهد تا ثروت عظیمی از دانش جهانی را به ارث ببرند. این دانش انباشته شده نقش مهمی در تشخیص بین قصدهای مختلف ایفا میکند و در نتیجه قابلیتهای تمایز مدل را در برابر مثالهای منفی افزایش میدهد.
-
یادگیری چند شات (Few-Shot Learning): یکی از ویژگیهای بارز NLU مبتنی بر GenAI/LLM، توانایی آن در استفاده از تکنیکهای یادگیری چند شات است. برخلاف روشهای سنتی که برای هر قصد به دادههای آموزشی گستردهای نیاز دارند، یادگیری چند شات به مدل امکان میدهد تا تنها از چند مثال یاد بگیرد. این رویکرد یادگیری کارآمد، اهداف مورد نظر را با حداقل داده تقویت میکند و بار آموزشی را به طور قابل توجهی کاهش میدهد.
این سناریو را در نظر بگیرید: هنگامی که پرس و جوی “آب و هوای امروز چطور است؟” به عنوان یک خواننده به شما ارائه می شود، شما به طور غریزی آن را به عنوان یک پرس و جو در مورد آب و هوا در میان انبوه جملاتی که روزانه با آنها روبرو می شوید، تشخیص می دهید. این توانایی ذاتی برای تشخیص قصد، شبیه به مفهوم یادگیری چند شات است.
به عنوان بزرگسالان، مغز ما با واژگان وسیعی از قبل آموزش دیده است که تا سن 20 سالگی حدود 150 میلیون کلمه تخمین زده می شود. این مواجهه زبانی گسترده به ما امکان می دهد تا با مواجهه با قصدهای جدید، آنها را به سرعت درک کنیم و برای تقویت فقط به چند مثال نیاز داریم.
فرهنگ لغت شهری (Urban Dictionary) منبعی عالی برای کاوش مثالهایی از یادگیری چند شات در عمل است که اثربخشی آن را در تسهیل درک سریع بیشتر نشان میدهد.
قابلیت یادگیری چند شات ذاتی در NLU مبتنی بر GenAI/LLM در کاهش هزینهها و امکانپذیری مقیاسپذیری نقش اساسی دارد. با تکمیل بخش عمده آموزش در طول پیشآموزش، تنظیم دقیق مدل با حداقل تعداد مثالها به تمرکز اصلی تبدیل میشود که فرآیند را سادهتر کرده و مقیاسپذیری را افزایش میدهد.
NLU مبتنی بر GenAI/LLM: ارائه نتایج و شواهد
از مارس 2024، چشمانداز پردازش زبان طبیعی (NLP) دستخوش تغییرات قابل توجهی شده است که با ظهور NLU مبتنی بر GenAI/LLM به عنوان یک تغییر دهنده بازی مشخص شده است. پیشرفت غالب در نوآوری NLP در 2-3 سال گذشته راکد شده است، همانطور که رکود در پیشرفتهای پیشرفته نشان میدهد. اگر پیشرفت NLP را که زمانی داغترین بود، برای وضعیت هنر بررسی کنید، عمدتاً 2-3 سال پیش متوقف شده است:
ما قبلاً نوآوری NLP را در این مخزن Github ردیابی میکردیم. بهروزرسانی عمدتاً 2-3 سال پیش متوقف شد.
یکی از معیارهای قابل توجهی که این تغییر پارادایم را تأکید میکند، جدول امتیازات SuperGlue است که آخرین ورودی آن در دسامبر 2022 است. جالب توجه است که این بازه زمانی با معرفی ChatGPT (3.5) همزمان است که شوک بزرگی را در جامعه NLP ایجاد کرد.
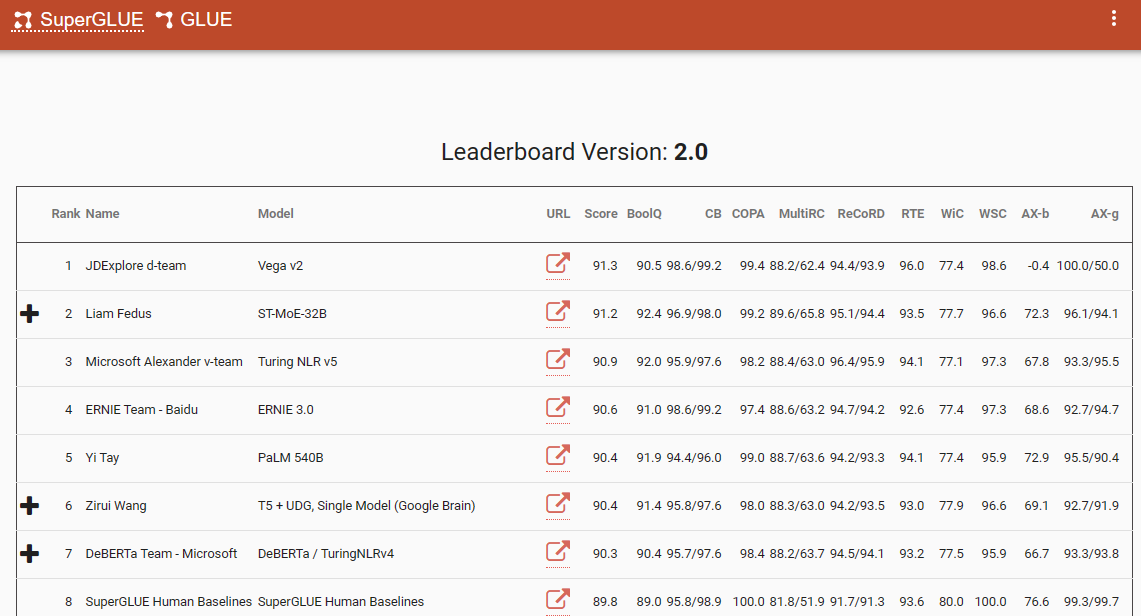
جدول امتیازات SuperGlue تا زمان معرفی ChatGPT محبوب بود
مقاله برجسته GPT-3، با عنوان مناسب “مدلهای زبان، یادگیرندگان چند شات هستند”، شواهد قانعکنندهای از اثربخشی یادگیری چند شات ارائه میدهد. شکل 2.1 در صفحه 7 مقاله، تمایز بین رویکردهای یادگیری صفر شات، یک شات و چند شات را مشخص میکند و برتری رویکرد اخیر را از نظر کارایی و اثربخشی یادگیری برجسته میسازد.

تمایز بین رویکردهای یادگیری صفر شات، یک شات و چند شات
علاوه بر این، برای تأیید اثربخشی NLU مبتنی بر GenAI/LLM، جدول 3.8 در صفحه 19، مقایسه مستقیمی بین روشهای NLU نظارت شده سنتی و یادگیری چند شات GPT-3 ارائه میدهد. در این مقایسه، GPT-3 Few-Shot از Fine-tuned BERT-Large، که نمایشی از یادگیری نظارت شده است که توسط سیستمهای NLU مبتنی بر قصد/موجودیت استفاده میشود، در وظایف مختلف پیشی میگیرد.
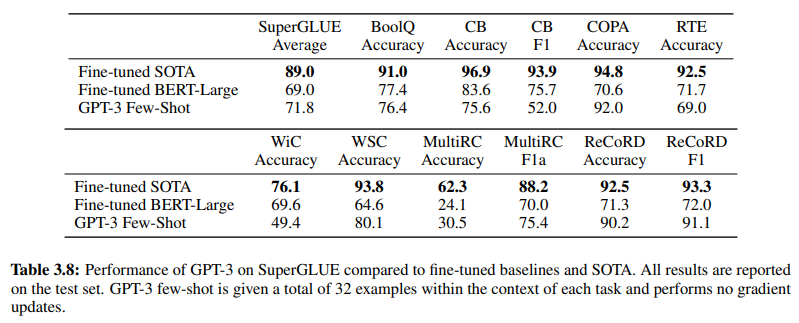
GPT-3 Few-Shot در وظایف مختلف از Fine-tuned BERT-Large پیشی میگیرد
برتری GPT-3 Few-Shot نه تنها در دقت آن، بلکه در کارایی هزینه آن نیز مشهود است. هزینههای راهاندازی اولیه و نگهداری مرتبط با NLU مبتنی بر GenAI/LLM در مقایسه با روشهای سنتی به طور قابل توجهی کمتر است.
شواهد تجربی ارائه شده در جامعه NLP، تأثیر تحولآفرین NLU مبتنی بر GenAI/LLM را تأکید میکند. این سیستم قبلاً دقت و کارایی بینظیر خود را نشان داده است. در ادامه، کارایی هزینه آن را بررسی خواهیم کرد.
الزامات دادههای آموزشی: تحلیل مقایسهای
مقایسهای آشکار بین NLU مبتنی بر قصد/موجودیت و NLU مبتنی بر GenAI/LLM، الزامات دادههای آموزشی متفاوت آنها را روشن میکند. شکل 3.8 در صفحه 20 تضاد شدیدی را نشان میدهد:
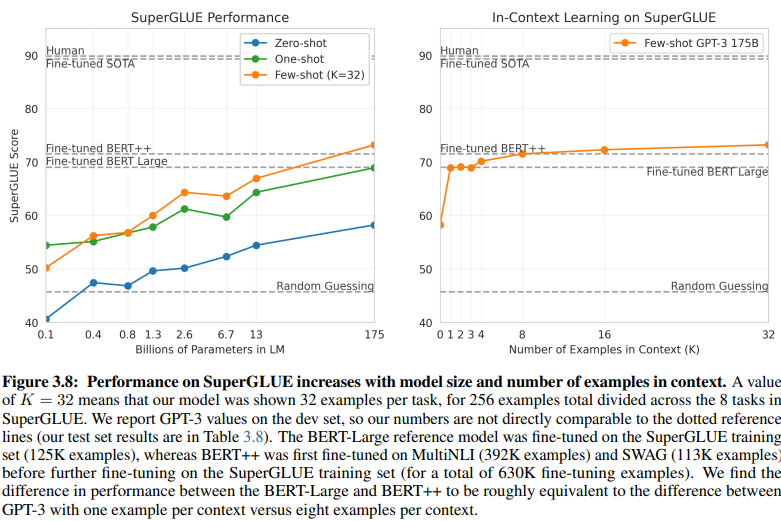
NLU مبتنی بر GenAI/LLM برای آموزش به دادههای بسیار کمتری نیاز دارد
-
NLU یادگیری نظارت شده: این رویکرد سنتی به مجموعه داده گستردهای نیاز دارد، با بیش از نیم میلیون مثال (630 هزار) برای آموزش مؤثر.
-
GPT-3 چند شات: در مقابل، NLU مبتنی بر GenAI/LLM کارایی قابل توجهی را نشان میدهد، با تنها 32 مثال برای هر وظیفه برای تنظیم مؤثر کافی است.
اندازه این تفاوت چشمگیر است: 630,000 مثال در مقابل تنها 32. این کاهش چشمگیر در الزامات دادههای آموزشی منجر به صرفهجویی قابل توجهی در هزینهها برای کسبوکارهایی میشود که NLU مبتنی بر GenAI/LLM را اتخاذ میکنند.
علاوه بر این، تأثیر ضمنی بر زمانبندی توسعه عمیق است. با NLU مبتنی بر GenAI/LLM، فرآیند آموزش کوتاهتر، استقرار سیستمهای NLU را چندین برابر سرعت میبخشد و سازگاری سریع و نوآوری را در حوزه پردازش زبان طبیعی تسهیل میکند.
در اصل، این مقایسه پتانسیل تحولآفرین NLU مبتنی بر GenAI/LLM را برجسته میکند که کارایی و مقرونبهصرفگی بینظیری را در الزامات دادههای آموزشی و زمانبندی توسعه ارائه میدهد.
پذیرش تکامل: چرا NLU مبتنی بر GenAI/LLM غالب است
در حوزه فهم زبان طبیعی، انتقال از سیستمهای مبتنی بر قصد/موجودیت به راهحلهای مبتنی بر GenAI/LLM بدون شک در حال انجام است. این تغییر توسط عوامل متعددی هدایت میشود که محدودیتهای NLU سنتی مبتنی بر قصد/موجودیت و مزایای قانعکننده ارائهشده توسط رویکردهای مبتنی بر GenAI/LLM را برجسته میکنند.
NLU مبتنی بر قصد/موجودیت به دلایل قانعکننده متعددی به طور فزایندهای منسوخ تلقی میشود:
-
انعطافپذیری محدود: سیستمهای NLU سنتی به قصدها و موجودیتهای از پیش تعریفشده متکی هستند، که سازگاری چتباتها و IVRها را با ورودیهای کاربر که از این دستهبندیهای از پیش تعریفشده منحرف میشوند، محدود میکند.
-
چالشهای نگهداری: با مقیاسپذیری این سیستمها و افزایش تعداد قصدها و موجودیتها، پیچیدگی و زمان مورد نیاز برای نگهداری و بهروزرسانی به طور تصاعدی افزایش مییابد.
-
عدم درک متنی: این سیستمها اغلب در درک ظرافتهای متنی پیچیده مکالمات دچار مشکل میشوند که منجر به پاسخهای نادرست یا نیاز به ورودی اضافی کاربر برای روشن شدن قصدها میشود.
-
عدم تولید: سیستمهای NLU مبتنی بر قصد و موجودیت ذاتاً در توانایی خود برای تولید متن محدود هستند و آنها را به وظایفی که حول طبقهبندی قصدها و استخراج موجودیتها متمرکز هستند، محدود میکنند. این امر سازگاری چتباتها و IVRها را محدود میکند و اغلب منجر به پاسخهای یکنواخت میشود که با زمینه مکالمه همخوانی ندارند.
در مقابل، NLU مبتنی بر GenAI/LLM به دلیل ویژگیهای تحولآفرین خود به عنوان روند غالب ظاهر میشود:
-
یادگیری تطبیقی: مدلهای GenAI توانایی یادگیری پویا از مکالمات بیدرنگ را دارند و به آنها امکان میدهند به طور مستقل با موضوعات جدید و رفتارهای کاربر سازگار شوند، بدون نیاز به بهروزرسانی دستی.
-
درک متنی: این مدلها در درک ظرافتهای متنی پیچیده مکالمات برتری دارند که منجر به پاسخهای دقیقتر و مرتبطتر میشود که با کاربران همخوانی دارد.
-
یادگیری چند شات: مدلهای GenAI را میتوان با حداقل مثال آموزش داد که فرآیند آموزش را سادهتر کرده و وابستگی به تعاریف صریح قصد و موجودیت را کاهش میدهد.
-
تولید زبان طبیعی: مدلهای GenAI/LLM توانایی تولید متن را دارند و به آنها امکان میدهند چتباتها و سایر برنامههای NLP را ایجاد کنند که پاسخهای طبیعی و مرتبط با متن را ارائه میدهند.
آینده هوش مصنوعی مکالمهای به سیستمهایی بستگی دارد که میتوانند به طور ارگانیک یاد بگیرند و سازگار شوند و تجربهای یکپارچه و بصری را برای کاربران فراهم کنند. NLU مبتنی بر GenAI/LLM این تکامل را تجسم میبخشد و رویکردی پویا و انعطافپذیر را ارائه میدهد که محدودیتهای سیستمهای سنتی مبتنی بر قصد/موجودیت را فراتر میرود.
در اصل، مسیر غالب NLU به طور غیرقابل انکاری با صعود رویکردهای مبتنی بر GenAI/LLM تعریف میشود که عصر جدیدی از هوش مصنوعی مکالمهای را نوید میدهد که سازگاری، متنی بودن و کاربرمحوری را در اولویت قرار میدهد.


