





Do wszystkich dyrektorów obsługi klienta lub marketingu: jeśli szef zada Ci następujące pytanie, wyślij im ten artykuł:
“Dlaczego NLU oparte na intencjach/encji jest przestarzałe, a NLU oparte na LLM/GenAI jest oczywistym trendem?”
Systemy rozumienia języka naturalnego (NLU) mają na celu przetwarzanie i analizowanie danych wejściowych w języku naturalnym, takich jak tekst lub mowa, w celu wydobycia znaczenia, wyodrębnienia istotnych informacji i zrozumienia podstawowej intencji komunikacji. NLU jest fundamentalnym składnikiem różnych aplikacji AI, w tym wirtualnych asystentów, chatbotów, narzędzi do analizy sentymentu, systemów tłumaczenia języka i wielu innych. Odgrywa kluczową rolę w umożliwianiu interakcji człowiek-komputer i ułatwianiu rozwoju inteligentnych systemów zdolnych do rozumienia i reagowania na dane wejściowe w języku naturalnym.
To pytanie pochodzi od uznanych klientów, którzy ponownie przemyślają swoje podejście do IVR i chatbotów. Są oni uwięzieni w poprzedniej generacji stosu technologicznego opartego na NLU, zazwyczaj oferowanego przez dużych graczy technologicznych, takich jak: Microsoft Bot Framework (lub luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
Wyzwaniem jest to, że główni klienci, tacy jak firmy ubezpieczeniowe, instytucje finansowe, rządy, linie lotnicze/dealerzy samochodowi i inne duże firmy, już wdrożyli technologię poprzedniej generacji. Ale ponieważ NLU oparte na intencjach/encji nie jest skalowalne, klienci muszą wydawać setki tysięcy do milionów dolarów rocznie na utrzymanie i modernizację swojego systemu NLU. Ten brak skalowalności przyczynia się do wzrostu kosztów utrzymania, co ostatecznie przynosi korzyści dostawcom NLU poprzedniej generacji kosztem ich klientów. Ponieważ nie skalują się, koszty utrzymania są wyższe z roku na rok.
Dlaczego NLU oparte na intencjach/encji nie skaluje się skutecznie?
Podstawową przyczyną jest ograniczona zdolność dyskryminacyjna modelu. Oto dlaczego tak jest:
-
Minimalne wymagania dotyczące intencji: Modele NLU wymagają co najmniej dwóch odrębnych intencji, aby skutecznie trenować. Na przykład, pytając o pogodę, intencja może być jasna, ale za każdym zapytaniem kryje się wiele potencjalnych intencji, takich jak awaryjne lub niezwiązane z pogodą zapytania, takie jak „jak się masz?”
-
Wymagania dotyczące danych treningowych: Duże firmy technologiczne zazwyczaj wymagają tysięcy pozytywnych przykładów na intencję do skutecznego treningu. Ten obszerny zestaw danych jest niezbędny, aby model mógł dokładnie uczyć się i rozróżniać różne intencje.
-
Równoważenie przykładów pozytywnych i negatywnych: Dodanie przykładów pozytywnych do jednej intencji wymaga włączenia przykładów negatywnych dla innych intencji. To zrównoważone podejście zapewnia, że model NLU może skutecznie uczyć się zarówno z pozytywnych, jak i negatywnych instancji.
-
Zróżnicowane zestawy przykładów: Zarówno przykłady pozytywne, jak i negatywne muszą być zróżnicowane, aby zapobiec przeuczeniu i zwiększyć zdolność modelu do generalizowania w różnych kontekstach.
-
Złożoność dodawania nowych intencji: Dodanie nowej intencji do istniejącego modelu NLU wiąże się z żmudnym procesem. Należy dodać tysiące przykładów pozytywnych i negatywnych, a następnie ponownie wytrenować model, aby utrzymać jego podstawową wydajność. Proces ten staje się coraz trudniejszy wraz ze wzrostem liczby intencji.
Efekt przepisywania: pułapka NLU opartego na intencjach/encji

Efekt przepisywania NLU opartego na intencjach/encji
Analogicznie do zjawiska w medycynie znanego jako „kaskada przepisywania”, wyzwania skalowalności NLU opartego na intencjach/encji można porównać do zniechęcającej kaskady recept. Wyobraźmy sobie starszą osobę obciążoną mnóstwem codziennych leków, z których każdy jest przepisywany w celu złagodzenia skutków ubocznych poprzedniego. Ten scenariusz jest zbyt dobrze znany, gdzie wprowadzenie leku A prowadzi do skutków ubocznych wymagających przepisania leku B w celu ich zwalczania. Jednak lek B wprowadza własny zestaw skutków ubocznych, co powoduje potrzebę leku C i tak dalej. W konsekwencji osoba starsza znajduje się w sytuacji, w której musi zarządzać górą pigułek – kaskada przepisywania.
Inną ilustracyjną metaforą jest budowanie wieży z klocków, gdzie każdy klocek reprezentuje lek. Początkowo umieszcza się lek A, ale jego niestabilność (skutki uboczne) skłania do dodania leku B w celu jego stabilizacji. Jednak ten nowy dodatek może nie integrować się płynnie, powodując dalsze przechylanie się wieży (skutek uboczny B). W celu naprawienia tej niestabilności dodaje się więcej klocków (leki C, D itp.), co pogarsza niestabilność wieży i jej podatność na zawalenie – reprezentacja potencjalnych komplikacji zdrowotnych wynikających z wielu leków.

Inną ilustracyjną metaforą dla NLU opartego na intencjach/encji jest budowanie wieży z klocków
Podobnie, z każdą nową intencją dodaną do systemu NLU, metaforyczna wieża z klocków rośnie, zwiększając niestabilność. Potrzeba wzmocnienia eskaluje, co skutkuje wyższymi kosztami utrzymania. W konsekwencji, choć NLU oparte na intencjach/encji może początkowo wydawać się atrakcyjne dla dostawców, rzeczywistość jest taka, że staje się ono nadmiernie uciążliwe dla klientów w utrzymaniu. Systemy te nie są skalowalne, co stwarza znaczne wyzwania zarówno dla dostawców, jak i klientów. W kolejnych sekcjach zbadamy, w jaki sposób NLU oparte na GenAI/LLM oferuje bardziej zrównoważoną i skalowalną alternatywę, aby skutecznie sprostać tym wyzwaniom.
NLU oparte na GenAI/LLM: Odporne rozwiązanie
NLU oparte na GenAI/LLM oferuje solidne rozwiązanie problemów skalowalności, z którymi borykają się systemy oparte na intencjach/encji. Wynika to przede wszystkim z dwóch kluczowych czynników:
-
Wstępne szkolenie i wiedza o świecie: Modele GenAI/LLM są wstępnie szkolone na ogromnych ilościach danych, co pozwala im dziedziczyć bogactwo wiedzy o świecie. Ta zgromadzona wiedza odgrywa kluczową rolę w rozróżnianiu różnych intencji, zwiększając tym samym zdolności dyskryminacyjne modelu wobec przykładów negatywnych.
-
Uczenie się z kilku przykładów (Few-Shot Learning): Jedną z charakterystycznych cech NLU opartego na GenAI/LLM jest jego zdolność do stosowania technik uczenia się z kilku przykładów. W przeciwieństwie do tradycyjnych metod, które wymagają obszernych danych treningowych dla każdej intencji, uczenie się z kilku przykładów umożliwia modelowi uczenie się z zaledwie kilku przykładów. To efektywne podejście do uczenia się wzmacnia zamierzone cele przy minimalnej ilości danych, znacznie zmniejszając obciążenie treningowe.
Rozważmy ten scenariusz: gdy jako czytelnik przedstawione zostanie zapytanie „Jaka jest dziś pogoda?”, instynktownie rozpoznajesz je jako zapytanie o pogodę wśród wielu zdań napotykanych codziennie. Ta wrodzona zdolność do rozróżniania intencji jest podobna do koncepcji uczenia się z kilku przykładów.
Jako dorośli, nasze mózgi są wstępnie trenowane z ogromnym zasobem słownictwa, szacowanym na około 150 milionów słów w wieku 20 lat. Ta obszerna ekspozycja językowa pozwala nam szybko pojmować nowe intencje po ich napotkaniu, wymagając jedynie kilku przykładów do wzmocnienia.
Urban Dictionary służy jako doskonałe źródło do eksploracji przykładów uczenia się z kilku przykładów w działaniu, dodatkowo ilustrując jego skuteczność w ułatwianiu szybkiego zrozumienia.
Zdolność uczenia się z kilku przykładów, wrodzona w NLU opartym na GenAI/LLM, jest kluczowa dla obniżenia kosztów i umożliwienia skalowalności. Ponieważ większość szkolenia została już zakończona podczas wstępnego szkolenia, dostrajanie modelu z minimalną liczbą przykładów staje się głównym celem, usprawniając proces i zwiększając skalowalność.
NLU oparte na GenAI/LLM: Dostarczanie wyników i dowodów
Od marca 2024 roku krajobraz przetwarzania języka naturalnego (NLP) uległ znaczącej zmianie, naznaczonej pojawieniem się NLU opartego na GenAI/LLM jako przełomowego rozwiązania. Dominujący niegdyś postęp w innowacjach NLP zatrzymał się w ciągu ostatnich 2-3 lat, o czym świadczy stagnacja w najnowocześniejszych osiągnięciach. Jeśli sprawdzisz niegdyś najgorętszy postęp NLP pod kątem stanu sztuki, to w większości zatrzymał się on 2-3 lata temu:
Kiedyś śledziliśmy innowacje NLP w tym repozytorium Github. Aktualizacja w większości zatrzymała się 2-3 lata temu.
Jednym z godnych uwagi punktów odniesienia, który podkreśla tę zmianę paradygmatu, jest tabela wyników SuperGlue, z jej najnowszym wpisem w grudniu 2022 roku. Co ciekawe, ten okres zbiega się z wprowadzeniem ChatGPT (3.5), które wywołało falę uderzeniową w całej społeczności NLP.
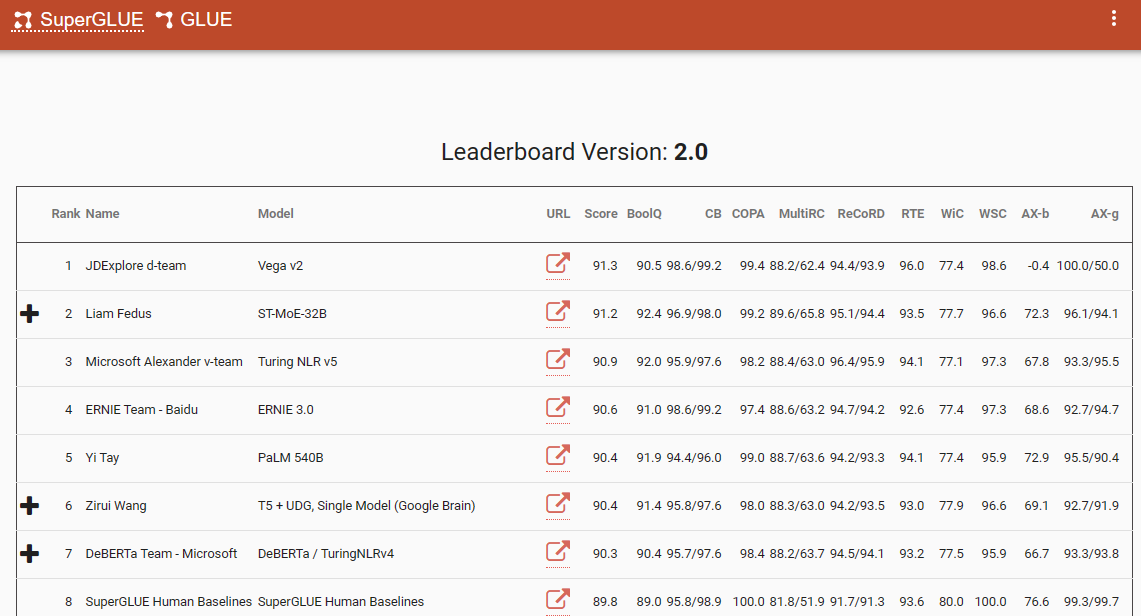
Tabela wyników SuperGlue była popularna do czasu wprowadzenia ChatGPT
Przełomowy artykuł GPT-3, trafnie zatytułowany „Modele językowe to uczący się z kilku przykładów”, dostarcza przekonujących dowodów na skuteczność uczenia się z kilku przykładów. Rysunek 2.1 na stronie 7 artykułu przedstawia rozróżnienia między podejściami do uczenia się z zerowym, jednym i kilkoma przykładami, podkreślając wyższość tego ostatniego pod względem efektywności i skuteczności uczenia się.

Rozróżnienia między podejściami do uczenia się z zerowym, jednym i kilkoma przykładami
Dodatkowo, potwierdzając skuteczność NLU opartego na GenAI/LLM, Tabela 3.8 na stronie 19 przedstawia bezpośrednie porównanie tradycyjnych nadzorowanych metod NLU i uczenia się z kilku przykładów GPT-3. W tym porównaniu GPT-3 Few-Shot przewyższa Fine-tuned BERT-Large, reprezentację uczenia nadzorowanego stosowanego przez systemy NLU oparte na intencjach/encji, w różnych zadaniach.
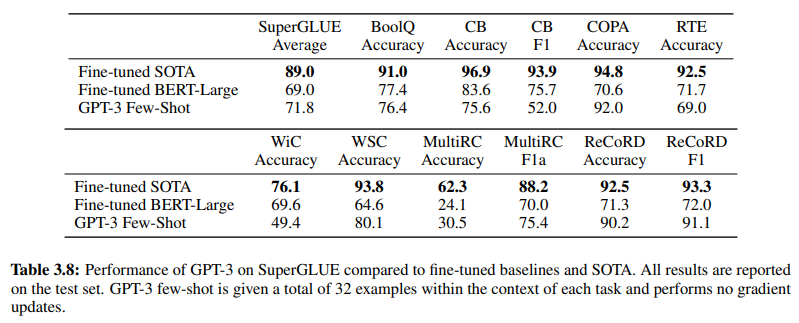
GPT-3 Few-Shot przewyższa Fine-tuned BERT-Large w różnych zadaniach
Wyższość GPT-3 Few-Shot jest widoczna nie tylko w jego dokładności, ale także w jego efektywności kosztowej. Zarówno początkowe koszty konfiguracji, jak i utrzymania związane z NLU opartym na GenAI/LLM są znacznie niższe w porównaniu z tradycyjnymi metodami.
Dowody empiryczne przedstawione w społeczności NLP podkreślają transformacyjny wpływ NLU opartego na GenAI/LLM. Już wykazało ono swoją niezrównaną dokładność i wydajność. Następnie sprawdzimy jego efektywność kosztową.
Wymagania dotyczące danych treningowych: Analiza porównawcza
Odkrywcza porównanie NLU opartego na intencjach/encji i NLU opartego na GenAI/LLM rzuca światło na ich odmienne wymagania dotyczące danych treningowych. Rysunek 3.8 na stronie 20 przedstawia wyraźny kontrast:
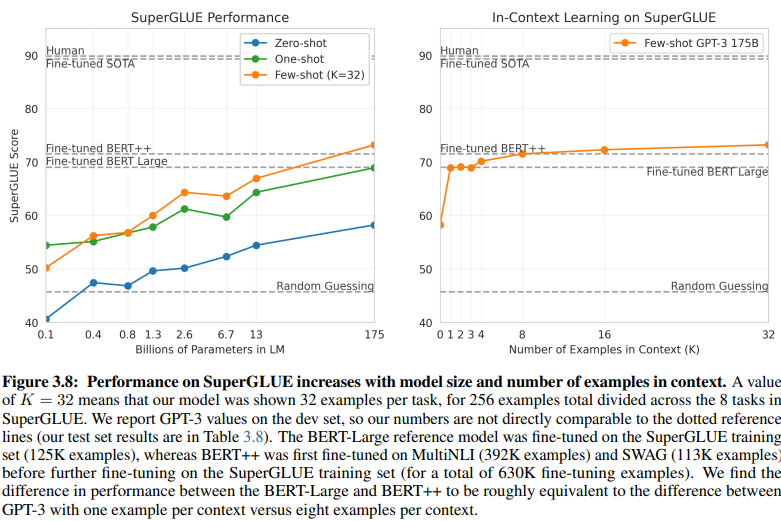
NLU oparte na GenAI/LLM wymaga znacznie mniej danych do treningu
-
Nadzorowane uczenie NLU: To tradycyjne podejście wymaga obszernego zbioru danych, z ponad pół milionem przykładów (630 tys.) potrzebnych do skutecznego treningu.
-
Few-Shot GPT-3: W przeciwieństwie do tego, NLU oparte na GenAI/LLM wykazuje niezwykłą wydajność, z zaledwie 32 przykładami na zadanie wystarczającymi do skutecznego dostrojenia.
Skala tej różnicy jest uderzająca: 630 000 przykładów w porównaniu z zaledwie 32. Ta drastyczna redukcja wymagań dotyczących danych treningowych przekłada się na znaczne oszczędności kosztów dla firm przyjmujących NLU oparte na GenAI/LLM.
Ponadto, implikowany wpływ na harmonogramy rozwoju jest głęboki. Dzięki NLU opartemu na GenAI/LLM, skrócony proces treningowy przyspiesza wdrażanie systemów NLU o wiele rzędów wielkości, ułatwiając szybką adaptację i innowacje w dziedzinie przetwarzania języka naturalnego.
Zasadniczo, to porównanie podkreśla transformacyjny potencjał NLU opartego na GenAI/LLM, oferując niezrównaną wydajność i efektywność kosztową w zakresie wymagań dotyczących danych treningowych i harmonogramów rozwoju.
Przyjęcie ewolucji: Dlaczego NLU oparte na GenAI/LLM przeważa
W dziedzinie rozumienia języka naturalnego, przejście z systemów opartych na intencjach/encji na rozwiązania oparte na GenAI/LLM jest bezsprzecznie w toku. Ta zmiana jest napędzana przez wiele czynników, które podkreślają ograniczenia tradycyjnego NLU opartego na intencjach/encji oraz przekonujące zalety oferowane przez podejścia oparte na GenAI/LLM.
NLU oparte na intencjach/encji jest coraz częściej uważane za przestarzałe z kilku przekonujących powodów:
-
Ograniczona elastyczność: Tradycyjne systemy NLU opierają się na predefiniowanych intencjach i encjach, co ogranicza adaptowalność chatbotów i IVR do danych wejściowych użytkownika, które odbiegają od tych predefiniowanych kategorii.
-
Wyzwania związane z konserwacją: W miarę skalowania tych systemów i proliferacji liczby intencji i encji, złożoność i czas wymagany do konserwacji i aktualizacji rosną wykładniczo.
-
Brak zrozumienia kontekstowego: Systemy te często zawodzą w uchwyceniu złożonych niuansów kontekstowych rozmów, co skutkuje niedokładnymi odpowiedziami lub potrzebą dodatkowego wkładu użytkownika w celu wyjaśnienia intencji.
-
Brak generacji: Systemy NLU oparte na intencjach i encjach są z natury ograniczone w swojej zdolności do generowania tekstu, co ogranicza je do zadań skoncentrowanych na klasyfikacji intencji i ekstrakcji encji. Ogranicza to adaptowalność chatbotów i IVR, często prowadząc do monotonnych odpowiedzi, które nie są zgodne z kontekstem rozmowy.
W przeciwieństwie do tego, NLU oparte na GenAI/LLM jawi się jako dominujący trend ze względu na swoje transformacyjne atrybuty:
-
Adaptacyjne uczenie się: Modele GenAI posiadają zdolność dynamicznego uczenia się z rozmów w czasie rzeczywistym, co pozwala im autonomicznie dostosowywać się do nowych tematów i zachowań użytkowników, bez konieczności ręcznych aktualizacji.
-
Zrozumienie kontekstowe: Modele te doskonale rozumieją złożone niuanse kontekstowe rozmów, co skutkuje bardziej precyzyjnymi i trafnymi odpowiedziami, które rezonują z użytkownikami.
-
Uczenie się z kilku przykładów: Modele GenAI mogą być trenowane z minimalną liczbą przykładów, co usprawnia proces treningowy i zmniejsza zależność od jawnych definicji intencji i encji.
-
Generowanie języka naturalnego: GenAI/LLM szczycą się zdolnością do generowania tekstu, co pozwala im tworzyć chatboty i inne aplikacje NLP, które dostarczają naturalne i kontekstowo istotne odpowiedzi.
Przyszłość konwersacyjnej AI zależy od systemów, które potrafią organicznie uczyć się i adaptować, zapewniając użytkownikom płynne i intuicyjne doświadczenie. NLU oparte na GenAI/LLM ucieleśnia tę ewolucję, oferując dynamiczne i elastyczne podejście, które wykracza poza ograniczenia tradycyjnych systemów opartych na intencjach/encji.
Zasadniczo, dominująca trajektoria NLU jest jednoznacznie określona przez wzrost znaczenia podejść opartych na GenAI/LLM, zwiastując nową erę konwersacyjnej AI, która priorytetowo traktuje adaptowalność, kontekstowość i zorientowanie na użytkownika.


