





致所有客户服务或营销总监,如果您的老板问您以下问题,请将此文章发送给他们:
“为什么基于意图/实体的 NLU 已经过时,而基于 LLM/GenAI 的 NLU 是显而易见的趋势?”
自然语言理解 (NLU) 系统旨在处理和分析自然语言输入,例如文本或语音,以提取含义、提取相关信息并理解通信背后的潜在意图。NLU 是各种 AI 应用程序的基本组成部分,包括虚拟助手、聊天机器人、情感分析工具、语言翻译系统等。它在实现人机交互和促进能够理解和响应自然语言输入的智能系统开发方面发挥着关键作用。
这个问题来自那些正在重新思考其 IVR 和聊天机器人方法的成熟客户。他们被锁定在上一代基于 NLU 的技术栈中,这些技术栈通常由大型科技公司提供,例如:Microsoft Bot Framework(或 luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU。
挑战在于,保险公司、金融机构、政府、航空公司/汽车经销商等主要客户已经部署了上一代技术。但由于基于意图/实体的 NLU 无法扩展,客户每年必须花费数十万到数百万美元来维护和升级其 NLU 系统。这种缺乏可扩展性导致维护成本不断上升,最终以牺牲客户为代价,使上一代 NLU 提供商受益。由于它们无法扩展,维护成本逐年增加。
为什么基于意图/实体的 NLU 无法有效扩展?
主要原因在于模型有限的判别能力。以下是原因的细分:
-
最小意图要求:NLU 模型需要至少两个不同的意图才能有效训练。例如,当询问天气时,意图可能很明确,但每个查询背后都有多个潜在意图,例如回退或与天气无关的查询,例如“你好吗?”
-
训练数据需求:大型科技公司通常要求每个意图提供数千个正面示例才能进行有效训练。这种广泛的数据集对于模型准确学习和区分不同意图是必要的。
-
平衡正面和负面示例:向一个意图添加正面示例需要为其他意图包含负面示例。这种平衡的方法确保 NLU 模型可以有效地从正面和负面实例中学习。
-
多样化的示例集:正面和负面示例都必须多样化,以防止过拟合并增强模型在不同上下文中泛化的能力。
-
添加新意图的复杂性:向现有 NLU 模型添加新意图涉及一个繁琐的过程。必须添加数千个正面和负面示例,然后重新训练模型以保持其基线性能。随着意图数量的增加,此过程变得越来越具有挑战性。
处方效应:基于意图/实体 NLU 的陷阱

基于意图/实体 NLU 的处方效应
类似于医学中被称为“处方级联”的现象,基于意图/实体的 NLU 的可扩展性挑战可以比作令人望而生畏的处方级联。想象一位老年人背负着大量日常药物,每种药物都是为了解决前一种药物的副作用而开的。这种情景太常见了,药物 A 的引入导致副作用,需要开药物 B 来抵消它们。然而,药物 B 又引入了自己的一系列副作用,从而需要药物 C,依此类推。因此,老年人发现自己被管理着堆积如山的药片——一个处方级联。
另一个形象的比喻是建造一座积木塔,每个积木代表一种药物。最初,药物 A 被放置,但其不稳定性(副作用)促使添加药物 B 来稳定它。然而,这种新添加可能无法无缝集成,导致塔进一步倾斜(B 的副作用)。为了纠正这种不稳定性,添加了更多的积木(药物 C、D 等),从而加剧了塔的不稳定性和倒塌的脆弱性——这代表了多种药物可能引起的健康并发症。

基于意图/实体 NLU 的另一个形象比喻是建造一座积木塔
同样,随着 NLU 系统中添加的每个新意图,比喻性的积木塔会越来越高,增加不稳定性。对强化的需求不断升级,导致更高的维护成本。因此,虽然基于意图/实体的 NLU 最初可能对提供商有吸引力,但现实是它对客户来说维护成本过高。这些系统缺乏可扩展性,给提供商和客户都带来了重大挑战。 在接下来的部分中,我们将探讨基于 GenAI/LLM 的 NLU 如何提供更可持续和可扩展的替代方案,以有效解决这些挑战。
基于 GenAI/LLM 的 NLU:弹性解决方案
基于 GenAI/LLM 的 NLU 为基于意图/实体的系统所面临的可扩展性挑战提供了强大的解决方案。这主要归因于两个关键因素:
-
预训练和世界知识:GenAI/LLM 模型在大量数据上进行预训练,使它们能够继承丰富的世界知识。这种积累的知识在区分各种意图方面发挥着关键作用,从而增强了模型对抗负面示例的判别能力。
-
少样本学习:基于 GenAI/LLM 的 NLU 的一个显著特点是它能够采用少样本学习技术。与需要大量训练数据才能实现每个意图的传统方法不同,少样本学习使模型能够仅从几个示例中学习。这种高效的学习方法以最少的数据强化了预期目标,显著降低了训练负担。
考虑这个场景:当您作为读者被问到“今天天气怎么样?”时,您会本能地将其识别为关于天气的询问,而不是每天遇到的众多句子中的一个。这种识别意图的内在能力类似于少样本学习的概念。
作为成年人,我们的大脑经过大量词汇的预训练,估计到 20 岁时词汇量约为 1.5 亿。这种广泛的语言接触使我们能够快速掌握新意图,只需少量示例即可进行强化。
Urban Dictionary 是探索少样本学习实际应用示例的绝佳资源,进一步说明了其在促进快速理解方面的有效性。
GenAI/LLM-based NLU 中固有的少样本学习能力对于降低成本和实现可扩展性至关重要。由于大部分训练已在预训练期间完成,因此使用最少数量的示例对模型进行微调成为主要焦点,从而简化了流程并提高了可扩展性。
基于 GenAI/LLM 的 NLU:提供结果和证据
截至 2024 年 3 月,自然语言处理 (NLP) 领域发生了重大转变,以基于 GenAI/LLM 的 NLU 的出现为标志。NLP 创新中曾经占据主导地位的进展在过去 2-3 年中停滞不前,这从最先进技术进展的停滞中可见一斑。如果您查看曾经最热门的 NLP 进展,就会发现它在 2-3 年前就基本停止了:
我们曾经在这个 Github 仓库中跟踪 NLP 创新。更新在 2-3 年前就基本停止了。
一个值得注意的基准,强调了这种范式转变的是 SuperGlue 排行榜,其最新条目在 2022 年 12 月。有趣的是,这个时间框架与 ChatGPT (3.5) 的引入相吻合,后者在整个 NLP 社区引起了轰动。
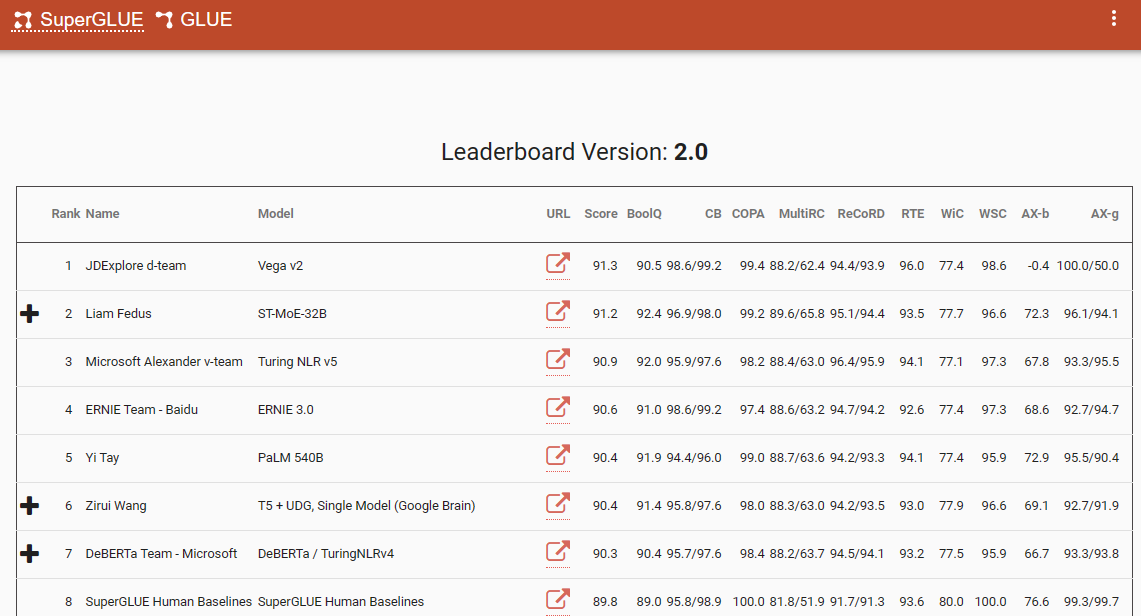
SuperGlue 排行榜在 ChatGPT 引入之前很受欢迎
开创性的 GPT-3 论文,恰当地命名为“语言模型是少样本学习者”,提供了少样本学习有效性的令人信服的证据。论文第 7 页的图 2.1 描绘了零样本、单样本和少样本学习方法之间的区别,强调了后者在学习效率和有效性方面的优越性。

零样本、单样本和少样本学习方法之间的区别
此外,为证实基于 GenAI/LLM 的 NLU 的有效性,第 19 页的表 3.8 直接比较了传统的监督式 NLU 方法和 GPT-3 少样本学习。在此比较中,GPT-3 少样本在各种任务中都超越了 Fine-tuned BERT-Large,后者是基于意图/实体的 NLU 系统所采用的监督式学习的代表。
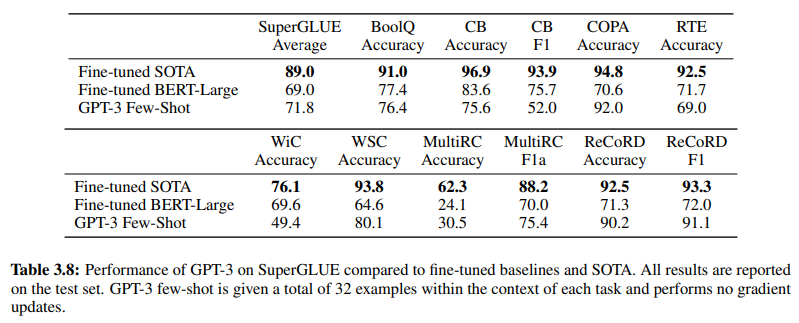
GPT-3 少样本在各种任务中超越了 Fine-tuned BERT-Large
GPT-3 少样本的优越性不仅体现在其准确性上,还体现在其成本效益上。与传统方法相比,基于 GenAI/LLM 的 NLU 的初始设置和维护成本都显著降低。
NLP 社区中提供的经验证据强调了基于 GenAI/LLM 的 NLU 的变革性影响。它已经展示了其无与伦比的准确性和效率。接下来,让我们检查其成本效益。
训练数据要求:比较分析
基于意图/实体的 NLU 和基于 GenAI/LLM 的 NLU 之间的一个揭示性比较揭示了它们不同的训练数据要求。第 20 页的图 3.8 呈现出鲜明的对比:
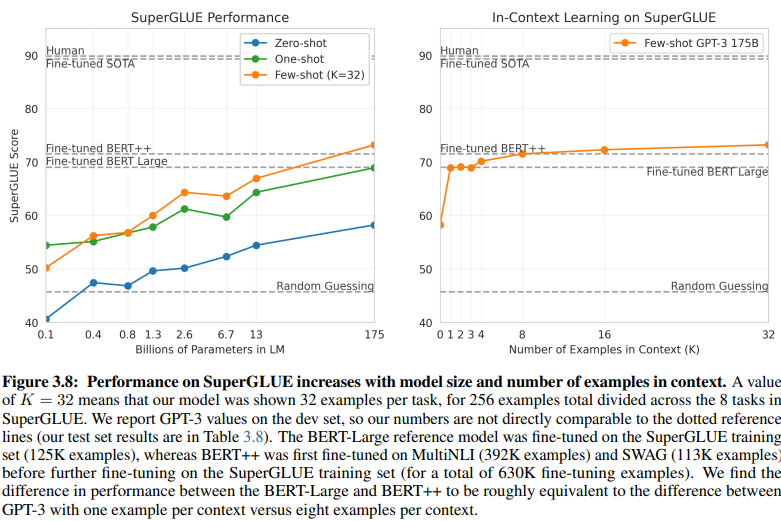
基于 GenAI/LLM 的 NLU 训练所需数据量少得多
-
监督学习 NLU:这种传统方法需要大量数据集,有效训练需要超过五十万个示例 (630K)。
-
少样本 GPT-3:相比之下,基于 GenAI/LLM 的 NLU 表现出卓越的效率,每个任务只需 32 个示例即可有效微调。
这种差异的 magnitud 令人震惊:630,000 个示例与仅仅 32 个。训练数据需求的这种急剧减少为采用基于 GenAI/LLM 的 NLU 的企业带来了显著的成本节约。
此外,对开发时间表的隐含影响是深远的。借助基于 GenAI/LLM 的 NLU,缩短的训练过程将 NLU 系统的部署速度提高了多个数量级,从而促进了自然语言处理领域的快速适应和创新。
本质上,这种比较强调了基于 GenAI/LLM 的 NLU 的变革潜力,在训练数据需求和开发时间表方面提供了无与伦比的效率和成本效益。
拥抱进化:为什么基于 GenAI/LLM 的 NLU 盛行
在自然语言理解领域,从基于意图/实体的系统向基于 GenAI/LLM 的解决方案的转变正在毫无疑问地进行中。这种转变是由众多因素推动的,这些因素强调了传统基于意图/实体的 NLU 的局限性以及基于 GenAI/LLM 的方法所提供的令人信服的优势。
基于意图/实体的 NLU 越来越被认为是过时的,原因有几个令人信服:
-
有限的灵活性:传统的 NLU 系统依赖于预定义的意图和实体,这限制了聊天机器人和 IVR 对偏离这些预定义类别的用户输入的适应性。
-
维护挑战:随着这些系统的扩展以及意图和实体数量的激增,维护和更新所需的复杂性和时间呈指数级增长。
-
缺乏上下文理解:这些系统通常无法理解对话中复杂的上下文细微差别,导致不准确的响应或需要额外的用户输入来澄清意图。
-
缺乏生成能力:基于意图和实体的 NLU 系统在生成文本的能力上固有地受到限制,这使得它们仅限于围绕意图分类和实体提取的任务。这限制了聊天机器人和 IVR 的适应性,通常导致单调的响应,无法与对话上下文保持一致。
相比之下,基于 GenAI/LLM 的 NLU 因其变革性属性而成为主流趋势:
-
自适应学习:GenAI 模型具有从实时对话中动态学习的能力,使它们能够自主适应新主题和用户行为,而无需手动更新。
-
上下文理解:这些模型擅长理解对话中复杂的上下文细微差别,从而产生更准确和相关的响应,与用户产生共鸣。
-
少样本学习:GenAI 模型可以用最少的示例进行训练,从而简化训练过程并减少对显式意图和实体定义的依赖。
-
自然语言生成:GenAI/LLM 拥有生成文本的能力,使它们能够创建聊天机器人和其他 NLP 应用程序,提供自然且上下文相关的响应。
对话式 AI 的未来取决于能够有机地学习和适应的系统,为用户提供无缝和直观的体验。基于 GenAI/LLM 的 NLU 体现了这一演变,提供了一种动态灵活的方法,超越了传统基于意图/实体的系统的限制。
本质上,NLU 的主要轨迹无疑是由基于 GenAI/LLM 的方法的兴起所定义的,预示着一个以适应性、上下文性和以用户为中心为优先的对话式 AI 新时代。