





Всем директорам по обслуживанию клиентов или маркетингу: если ваш начальник задаст вам следующий вопрос, отправьте им эту статью:
“Почему NLU на основе намерений/сущностей устарел, а NLU на основе LLM/GenAI является очевидным трендом?”
Системы понимания естественного языка (NLU) направлены на обработку и анализ входных данных на естественном языке, таких как текст или речь, для извлечения смысла, извлечения релевантной информации и понимания основной интенции, стоящей за коммуникацией. NLU является фундаментальным компонентом различных приложений ИИ, включая виртуальных помощников, чат-ботов, инструменты анализа настроений, системы машинного перевода и многое другое. Он играет критически важную роль в обеспечении взаимодействия человека с компьютером и облегчении разработки интеллектуальных систем, способных понимать и реагировать на входные данные на естественном языке.
Этот вопрос исходит от устоявшихся клиентов, которые переосмысливают свой подход к IVR и чат-ботам. Они застряли в предыдущем поколении технологического стека на основе NLU, обычно предлагаемого крупными технологическими игроками, такими как: Microsoft Bot Framework (или luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
Проблема заключается в том, что крупные клиенты, такие как страховые компании, финансовые учреждения, правительства, авиакомпании/автосалоны и другие крупные сделки, уже развернули технологии последнего поколения. Но поскольку NLU на основе намерений/сущностей не масштабируется, клиентам приходится тратить сотни тысяч до миллионов долларов ежегодно на обслуживание и обновление своей системы NLU. Этот недостаток масштабируемости способствует росту затрат на обслуживание, что в конечном итоге приносит пользу поставщикам NLU последнего поколения за счет их клиентов. Поскольку они не масштабируются, затраты на обслуживание растут из года в год.
Почему NLU на основе намерений/сущностей не масштабируется эффективно?
Основная причина кроется в ограниченной дискриминационной способности модели. Вот почему это так:
-
Минимальные требования к намерениям: Модели NLU требуют как минимум двух различных намерений для эффективного обучения. Например, при запросе о погоде намерение может быть ясным, но за каждым запросом скрывается множество потенциальных намерений, таких как запасной вариант или запросы, не связанные с погодой, например, «как дела?»
-
Требования к обучающим данным: Крупные технологические компании обычно требуют тысячи положительных примеров для каждого намерения для эффективного обучения. Этот обширный набор данных необходим для того, чтобы модель могла точно изучать и различать различные намерения.
-
Балансировка положительных и отрицательных примеров: Добавление положительных примеров к одному намерению требует включения отрицательных примеров для других намерений. Этот сбалансированный подход гарантирует, что модель NLU может эффективно обучаться как на положительных, так и на отрицательных примерах.
-
Разнообразные наборы примеров: Как положительные, так и отрицательные примеры должны быть разнообразными, чтобы предотвратить переобучение и улучшить способность модели к обобщению в различных контекстах.
-
Сложность добавления новых намерений: Добавление нового намерения в существующую модель NLU — трудоемкий процесс. Необходимо добавить тысячи положительных и отрицательных примеров, а затем переобучить модель для поддержания ее базовой производительности. Этот процесс становится все более сложным по мере роста числа намерений.
Эффект предписания: ловушка NLU на основе намерений/сущностей

Эффект предписания NLU на основе намерений/сущностей
Подобно явлению в медицине, известному как «каскад предписаний», проблемы масштабируемости NLU на основе намерений/сущностей можно сравнить с пугающим каскадом предписаний. Представьте себе пожилого человека, обремененного множеством ежедневных лекарств, каждое из которых предписано для устранения побочных эффектов предыдущего. Этот сценарий слишком знаком, когда введение Лекарства А приводит к побочным эффектам, требующим назначения Лекарства Б для их устранения. Однако Лекарство Б вводит свой собственный набор побочных эффектов, что вызывает необходимость в Лекарстве В и так далее. Следовательно, пожилой человек оказывается заваленным горой таблеток, которыми нужно управлять — каскад предписаний.
Еще одна наглядная метафора — это строительство башни из блоков, где каждый блок представляет собой лекарство. Изначально помещается Лекарство А, но его нестабильность (побочные эффекты) побуждает к добавлению Лекарства Б для его стабилизации. Однако это новое добавление может не интегрироваться бесшовно, что приводит к еще большему наклону башни (побочный эффект Б). В попытке исправить эту нестабильность добавляются новые блоки (Лекарства В, Г и т. д.), что усугубляет нестабильность башни и ее подверженность обрушению — представление о потенциальных осложнениях для здоровья, возникающих из-за множества лекарств.

Еще одна наглядная метафора для NLU на основе намерений/сущностей — это строительство башни из блоков
Аналогично, с каждым новым намерением, добавляемым в систему NLU, метафорическая башня из блоков становится выше, увеличивая нестабильность. Потребность в усилении возрастает, что приводит к увеличению затрат на обслуживание. Следовательно, хотя NLU на основе намерений/сущностей может показаться привлекательным для поставщиков изначально, реальность такова, что его поддержание становится чрезмерно обременительным для клиентов. Эти системы не обладают масштабируемостью, что создает значительные проблемы как для поставщиков, так и для клиентов. В последующих разделах мы рассмотрим, как NLU на основе GenAI/LLM предлагает более устойчивую и масштабируемую альтернативу для эффективного решения этих проблем.
NLU на основе GenAI/LLM: устойчивое решение
NLU на основе GenAI/LLM предлагает надежное решение проблем масштабируемости, с которыми сталкиваются системы на основе намерений/сущностей. Это в основном объясняется двумя ключевыми факторами:
-
Предварительное обучение и мировые знания: Модели GenAI/LLM предварительно обучаются на огромных объемах данных, что позволяет им наследовать обширные мировые знания. Эти накопленные знания играют решающую роль в различении различных намерений, тем самым повышая дискриминационные способности модели в отношении отрицательных примеров.
-
Обучение с малым количеством примеров (Few-Shot Learning): Одной из отличительных особенностей NLU на основе GenAI/LLM является его способность использовать методы обучения с малым количеством примеров. В отличие от традиционных методов, которые требуют обширных обучающих данных для каждого намерения, обучение с малым количеством примеров позволяет модели обучаться всего на нескольких примерах. Этот эффективный подход к обучению усиливает намеченные цели с минимальным количеством данных, значительно снижая нагрузку на обучение.
Рассмотрим этот сценарий: когда вам, как читателю, предлагается запрос «Какая сегодня погода?», вы инстинктивно распознаете его как запрос о погоде среди множества предложений, встречающихся ежедневно. Эта врожденная способность различать намерения сродни концепции обучения с малым количеством примеров.
Будучи взрослыми, наш мозг предварительно обучен обширному словарному запасу, который к 20 годам оценивается примерно в 150 миллионов слов. Это обширное языковое воздействие позволяет нам быстро усваивать новые намерения при их встрече, требуя лишь нескольких примеров для закрепления.
Urban Dictionary служит отличным ресурсом для изучения примеров обучения с малым количеством примеров в действии, что еще больше иллюстрирует его эффективность в содействии быстрому пониманию.
Возможность обучения с малым количеством примеров, присущая NLU на основе GenAI/LLM, имеет решающее значение для снижения затрат и обеспечения масштабируемости. Поскольку большая часть обучения уже завершена во время предварительного обучения, тонкая настройка модели с минимальным количеством примеров становится основным фокусом, что упрощает процесс и повышает масштабируемость.
NLU на основе GenAI/LLM: предоставление результатов и доказательств
По состоянию на март 2024 года ландшафт обработки естественного языка (NLP) претерпел значительные изменения, отмеченные появлением NLU на основе GenAI/LLM как переломного момента. Ранее доминирующий прогресс в инновациях NLP застопорился за последние 2-3 года, о чем свидетельствует стагнация в передовых достижениях. Если вы проверите некогда самый популярный прогресс NLP для современного состояния, то он в основном остановился 2-3 года назад:
Мы раньше отслеживали инновации NLP в этом репозитории Github. Обновление в основном остановилось 2-3 года назад.
Одним из примечательных показателей, который подчеркивает этот сдвиг парадигмы, является таблица лидеров SuperGlue, с ее последней записью в декабре 2022 года. Интересно, что этот временной интервал совпадает с появлением ChatGPT (3.5), который вызвал шок во всем сообществе NLP.
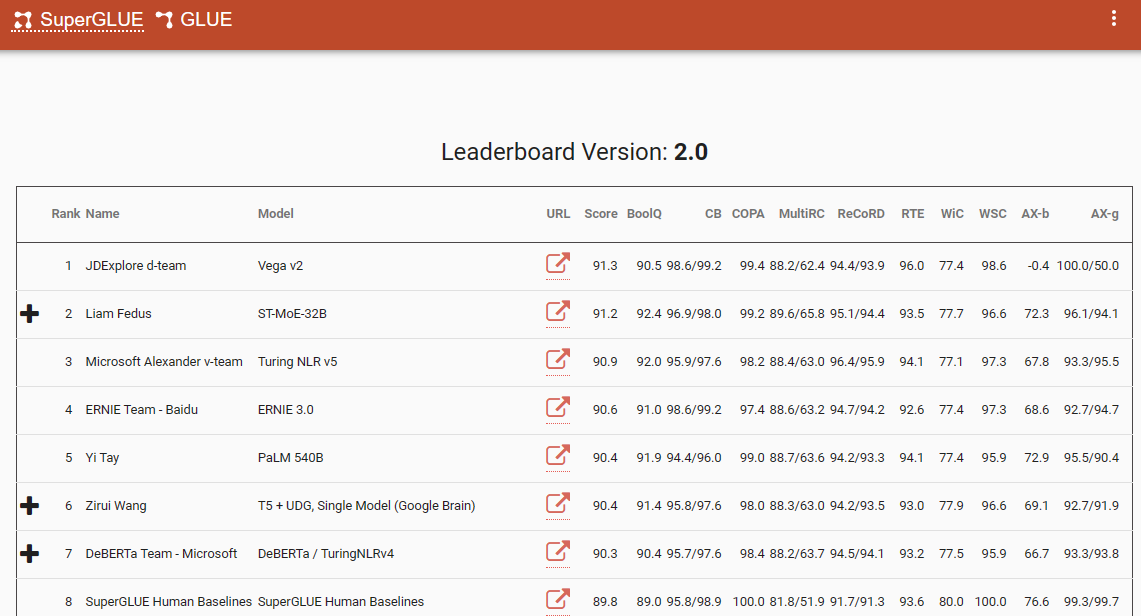
Таблица лидеров SuperGlue была популярна до появления ChatGPT
Основополагающая статья GPT-3, метко названная «Языковые модели — это обучающиеся с малым количеством примеров», предоставляет убедительные доказательства эффективности обучения с малым количеством примеров. Рисунок 2.1 на странице 7 статьи разграничивает различия между подходами к обучению с нулевым, одним и малым количеством примеров, подчеркивая превосходство последнего с точки зрения эффективности и результативности обучения.

Различия между подходами к обучению с нулевым, одним и малым количеством примеров
Далее, подтверждая эффективность NLU на основе GenAI/LLM, Таблица 3.8 на странице 19 предоставляет прямое сравнение между традиционными методами NLU с учителем и обучением GPT-3 Few-Shot. В этом сравнении GPT-3 Few-Shot превосходит Fine-tuned BERT-Large, представление обучения с учителем, используемое системами NLU на основе намерений/сущностей, в различных задачах.
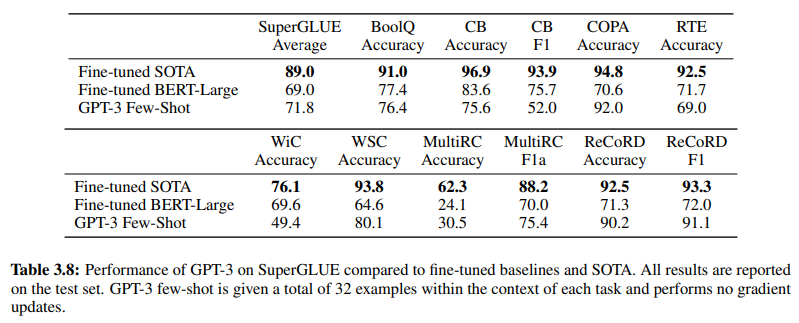
GPT-3 Few-Shot превосходит Fine-tuned BERT-Large в различных задачах
Превосходство GPT-3 Few-Shot очевидно не только в его точности, но и в его экономической эффективности. Как первоначальные затраты на настройку, так и затраты на обслуживание, связанные с NLU на основе GenAI/LLM, значительно ниже по сравнению с традиционными методами.
Эмпирические данные, представленные в сообществе NLP, подчеркивают преобразующее влияние NLU на основе GenAI/LLM. Он уже продемонстрировал свою беспрецедентную точность и эффективность. Далее, давайте проверим его экономическую эффективность.
Требования к обучающим данным: сравнительный анализ
Раскрывающее сравнение NLU на основе намерений/сущностей и NLU на основе GenAI/LLM проливает свет на их различные требования к обучающим данным. Рисунок 3.8 на странице 20 представляет собой разительный контраст:
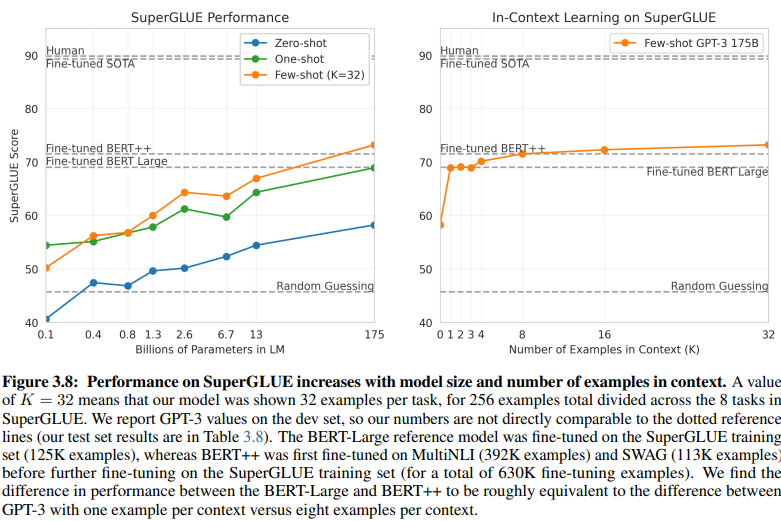
NLU на основе GenAI/LLM требует гораздо меньше данных для обучения
-
NLU с обучением с учителем: Этот традиционный подход требует обширного набора данных, с более чем полумиллионом примеров (630K), необходимых для эффективного обучения.
-
GPT-3 Few-Shot: В отличие от этого, NLU на основе GenAI/LLM демонстрирует замечательную эффективность, при этом всего 32 примеров на задачу достаточно для эффективной тонкой настройки.
Масштаб этой разницы поразителен: 630 000 примеров против всего 32. Это резкое сокращение требований к обучающим данным приводит к значительной экономии средств для предприятий, внедряющих NLU на основе GenAI/LLM.
Более того, подразумеваемое влияние на сроки разработки глубоко. С NLU на основе GenAI/LLM, сокращенный процесс обучения ускоряет развертывание систем NLU в несколько раз, способствуя быстрой адаптации и инновациям в области обработки естественного языка.
По сути, это сравнение подчеркивает преобразующий потенциал NLU на основе GenAI/LLM, предлагая беспрецедентную эффективность и экономичность в требованиях к обучающим данным и сроках разработки.
Принятие эволюции: почему NLU на основе GenAI/LLM преобладает
В области понимания естественного языка переход от систем на основе намерений/сущностей к решениям на основе GenAI/LLM, несомненно, идет полным ходом. Этот сдвиг обусловлен множеством факторов, которые подчеркивают ограничения традиционного NLU на основе намерений/сущностей и убедительные преимущества, предлагаемые подходами на основе GenAI/LLM.
NLU на основе намерений/сущностей все чаще считается устаревшим по нескольким убедительным причинам:
-
Ограниченная гибкость: Традиционные системы NLU зависят от предопределенных намерений и сущностей, что ограничивает адаптивность чат-ботов и IVR к вводам пользователя, которые отклоняются от этих предопределенных категорий.
-
Проблемы с обслуживанием: По мере масштабирования этих систем и увеличения числа намерений и сущностей, сложность и время, необходимые для обслуживания и обновлений, экспоненциально возрастают.
-
Отсутствие контекстного понимания: Эти системы часто не справляются с пониманием сложных контекстных нюансов разговоров, что приводит к неточным ответам или необходимости дополнительного ввода пользователя для уточнения намерений.
-
Отсутствие генерации: Системы NLU на основе намерений и сущностей по своей сути ограничены в своей способности генерировать текст, что ограничивает их задачами, сосредоточенными на классификации намерений и извлечении сущностей. Это ограничивает адаптивность чат-ботов и IVR, часто приводя к монотонным ответам, которые не соответствуют контексту разговора.
В отличие от этого, NLU на основе GenAI/LLM становится преобладающей тенденцией благодаря своим преобразующим атрибутам:
-
Адаптивное обучение: Модели GenAI обладают способностью динамически обучаться на основе разговоров в реальном времени, что позволяет им автономно адаптироваться к новым темам и поведению пользователей без необходимости ручных обновлений.
-
Контекстное понимание: Эти модели превосходно понимают сложные контекстные нюансы разговоров, что приводит к более точным и релевантным ответам, которые находят отклик у пользователей.
-
Обучение с малым количеством примеров: Модели GenAI могут быть обучены с минимальным количеством примеров, что упрощает процесс обучения и снижает зависимость от явных определений намерений и сущностей.
-
Генерация естественного языка: GenAI/LLM обладают способностью генерировать текст, что позволяет им создавать чат-боты и другие приложения NLP, которые предоставляют естественные и контекстно релевантные ответы.
Будущее разговорного ИИ зависит от систем, которые могут органично учиться и адаптироваться, предоставляя пользователям бесшовный и интуитивно понятный опыт. NLU на основе GenAI/LLM воплощает эту эволюцию, предлагая динамичный и гибкий подход, который превосходит ограничения традиционных систем на основе намерений/сущностей.
По сути, преобладающая траектория NLU однозначно определяется восхождением подходов на основе GenAI/LLM, предвещая новую эру разговорного ИИ, которая отдает приоритет адаптивности, контекстуальности и ориентированности на пользователя.


