





Kính gửi tất cả các Giám đốc Dịch vụ khách hàng hoặc Tiếp thị, nếu sếp của bạn hỏi bạn câu hỏi sau, hãy gửi cho họ bài viết này:
“Tại sao NLU dựa trên ý định/thực thể đã lỗi thời và LLM/GenAI là xu hướng rõ ràng?”
Các hệ thống Hiểu ngôn ngữ tự nhiên (NLU) nhằm mục đích xử lý và phân tích các đầu vào ngôn ngữ tự nhiên, chẳng hạn như văn bản hoặc giọng nói, để suy ra ý nghĩa, trích xuất thông tin liên quan và hiểu ý định cơ bản đằng sau giao tiếp. NLU là một thành phần cơ bản của các ứng dụng AI khác nhau, bao gồm trợ lý ảo, chatbot, công cụ phân tích cảm xúc, hệ thống dịch ngôn ngữ, v.v. Nó đóng một vai trò quan trọng trong việc cho phép tương tác giữa người và máy tính và tạo điều kiện phát triển các hệ thống thông minh có khả năng hiểu và phản hồi các đầu vào ngôn ngữ tự nhiên.
Câu hỏi này đến từ các khách hàng đã thành lập đang xem xét lại cách tiếp cận IVR và chatbot của họ. Họ bị khóa vào thế hệ trước của ngăn xếp công nghệ dựa trên NLU, thường được cung cấp bởi các ông lớn công nghệ như: Microsoft Bot Framework (hoặc luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
Thách thức là các khách hàng lớn như công ty bảo hiểm, tổ chức tài chính, chính phủ, hãng hàng không/đại lý ô tô và các giao dịch lớn khác đã triển khai công nghệ thế hệ trước. Nhưng vì NLU dựa trên ý định/thực thể không thể mở rộng quy mô, khách hàng phải chi hàng trăm nghìn đến hàng triệu đô la mỗi năm để duy trì và nâng cấp hệ thống NLU của họ. Việc thiếu khả năng mở rộng này góp phần làm tăng chi phí bảo trì, cuối cùng mang lại lợi ích cho các nhà cung cấp NLU thế hệ trước với chi phí của khách hàng. Vì chúng không mở rộng quy mô, chi phí bảo trì cao hơn theo từng năm.
Tại sao NLU dựa trên ý định/thực thể không thể mở rộng quy mô hiệu quả?
Lý do chính nằm ở khả năng phân biệt hạn chế của mô hình. Dưới đây là phân tích lý do tại sao lại như vậy:
-
Yêu cầu ý định tối thiểu: Các mô hình NLU yêu cầu ít nhất hai ý định riêng biệt để đào tạo hiệu quả. Ví dụ, khi hỏi về thời tiết, ý định có thể rõ ràng, nhưng đằng sau mỗi truy vấn là nhiều ý định tiềm năng, chẳng hạn như dự phòng hoặc các câu hỏi không liên quan đến thời tiết như “bạn khỏe không?”
-
Nhu cầu dữ liệu đào tạo: Các công ty công nghệ lớn thường yêu cầu hàng nghìn ví dụ tích cực cho mỗi ý định để đào tạo hiệu quả. Tập dữ liệu mở rộng này là cần thiết để mô hình học và phân biệt chính xác giữa các ý định khác nhau.
-
Cân bằng ví dụ tích cực và tiêu cực: Thêm ví dụ tích cực vào một ý định đòi hỏi phải bao gồm các ví dụ tiêu cực cho các ý định khác. Cách tiếp cận cân bằng này đảm bảo rằng mô hình NLU có thể học hỏi hiệu quả từ cả các trường hợp tích cực và tiêu cực.
-
Bộ ví dụ đa dạng: Cả ví dụ tích cực và tiêu cực phải đa dạng để ngăn chặn việc học quá mức (overfitting) và nâng cao khả năng tổng quát hóa của mô hình trên các ngữ cảnh khác nhau.
-
Độ phức tạp khi thêm ý định mới: Thêm một ý định mới vào mô hình NLU hiện có là một quá trình tốn nhiều công sức. Hàng nghìn ví dụ tích cực và tiêu cực phải được thêm vào, sau đó là đào tạo lại mô hình để duy trì hiệu suất cơ bản của nó. Quá trình này ngày càng trở nên khó khăn hơn khi số lượng ý định tăng lên.
Hiệu ứng kê đơn: Cạm bẫy của NLU dựa trên ý định/thực thể

Hiệu ứng kê đơn của NLU dựa trên ý định/thực thể
Tương tự như hiện tượng trong y học được gọi là “thác kê đơn”, những thách thức về khả năng mở rộng của NLU dựa trên ý định/thực thể có thể được ví như một thác kê đơn đáng sợ. Hãy hình dung một người cao tuổi phải gánh vác vô số loại thuốc hàng ngày, mỗi loại được kê đơn để giải quyết các tác dụng phụ của loại thuốc trước đó. Kịch bản này quá quen thuộc, khi việc giới thiệu Thuốc A dẫn đến các tác dụng phụ đòi hỏi phải kê đơn Thuốc B để chống lại chúng. Tuy nhiên, Thuốc B lại gây ra một loạt các tác dụng phụ riêng, thúc đẩy nhu cầu về Thuốc C, v.v. Do đó, người cao tuổi thấy mình bị ngập trong một núi thuốc phải quản lý — một thác kê đơn.
Một phép ẩn dụ minh họa khác là việc xây dựng một tòa tháp bằng các khối, với mỗi khối đại diện cho một loại thuốc. Ban đầu, Thuốc A được đặt, nhưng sự bất ổn của nó (tác dụng phụ) thúc đẩy việc thêm Thuốc B để ổn định nó. Tuy nhiên, việc bổ sung mới này có thể không tích hợp liền mạch, khiến tòa tháp nghiêng thêm (tác dụng phụ của B). Trong nỗ lực khắc phục sự bất ổn này, nhiều khối hơn (Thuốc C, D, v.v.) được thêm vào, làm trầm trọng thêm sự bất ổn của tòa tháp và khả năng sụp đổ — một biểu hiện của các biến chứng sức khỏe tiềm ẩn phát sinh từ nhiều loại thuốc.

Một phép ẩn dụ minh họa khác cho NLU dựa trên ý định/thực thể là xây dựng một tòa tháp bằng các khối
Tương tự, với mỗi ý định mới được thêm vào hệ thống NLU, tòa tháp khối ẩn dụ càng cao, làm tăng sự bất ổn. Nhu cầu tăng cường leo thang, dẫn đến chi phí bảo trì cao hơn. Do đó, mặc dù NLU dựa trên ý định/thực thể có vẻ hấp dẫn đối với các nhà cung cấp ban đầu, nhưng thực tế là nó trở nên quá nặng nề để khách hàng duy trì. Các hệ thống này thiếu khả năng mở rộng, gây ra những thách thức đáng kể cho cả nhà cung cấp và khách hàng. Trong các phần tiếp theo, chúng tôi sẽ khám phá cách NLU dựa trên GenAI/LLM cung cấp một giải pháp thay thế bền vững và có khả năng mở rộng hơn để giải quyết hiệu quả những thách thức này.
NLU dựa trên GenAI/LLM: Một giải pháp linh hoạt
NLU dựa trên GenAI/LLM cung cấp một giải pháp mạnh mẽ cho các thách thức về khả năng mở rộng mà các hệ thống dựa trên ý định/thực thể phải đối mặt. Điều này chủ yếu được quy cho hai yếu tố chính:
-
Tiền đào tạo và Kiến thức thế giới: Các mô hình GenAI/LLM được tiền đào tạo trên một lượng lớn dữ liệu, cho phép chúng kế thừa một kho kiến thức thế giới phong phú. Kiến thức tích lũy này đóng một vai trò quan trọng trong việc phân biệt giữa các ý định khác nhau, từ đó nâng cao khả năng phân biệt của mô hình đối với các ví dụ tiêu cực.
-
Học tập Few-Shot: Một trong những tính năng nổi bật của NLU dựa trên GenAI/LLM là khả năng sử dụng các kỹ thuật học tập few-shot. Không giống như các phương pháp truyền thống yêu cầu dữ liệu đào tạo mở rộng cho mỗi ý định, học tập few-shot cho phép mô hình học từ chỉ một vài ví dụ. Cách tiếp cận học tập hiệu quả này củng cố các mục tiêu dự định với dữ liệu tối thiểu, giảm đáng kể gánh nặng đào tạo.
Hãy xem xét kịch bản này: khi được trình bày với truy vấn “Thời tiết hôm nay thế nào?” với tư cách là người đọc, bạn theo bản năng nhận ra đó là một câu hỏi về thời tiết giữa vô số câu mà bạn gặp hàng ngày. Khả năng bẩm sinh để phân biệt ý định này tương tự như khái niệm học tập few-shot.
Khi trưởng thành, bộ não của chúng ta được đào tạo trước với một vốn từ vựng khổng lồ, ước tính khoảng 150 triệu từ khi 20 tuổi. Việc tiếp xúc ngôn ngữ rộng rãi này cho phép chúng ta nhanh chóng nắm bắt các ý định mới khi gặp chúng, chỉ cần một vài ví dụ để củng cố.
Từ điển đô thị (Urban Dictionary) là một nguồn tài nguyên tuyệt vời để khám phá các ví dụ về học tập few-shot trong thực tế, minh họa thêm hiệu quả của nó trong việc tạo điều kiện hiểu nhanh.
Khả năng học tập few-shot vốn có trong NLU dựa trên GenAI/LLM là công cụ để giảm chi phí và cho phép mở rộng quy mô. Với phần lớn quá trình đào tạo đã hoàn thành trong quá trình tiền đào tạo, việc tinh chỉnh mô hình với số lượng ví dụ tối thiểu trở thành trọng tâm chính, hợp lý hóa quy trình và nâng cao khả năng mở rộng.
NLU dựa trên GenAI/LLM: Mang lại kết quả và bằng chứng
Tính đến tháng 3 năm 2024, bối cảnh xử lý ngôn ngữ tự nhiên (NLP) đã trải qua một sự thay đổi đáng kể, được đánh dấu bằng sự xuất hiện của NLU dựa trên GenAI/LLM như một yếu tố thay đổi cuộc chơi. Sự tiến bộ từng thống trị trong đổi mới NLP đã chững lại trong 2-3 năm qua, bằng chứng là sự trì trệ trong các tiến bộ tiên tiến. Nếu bạn kiểm tra tiến bộ NLP từng nóng nhất cho trạng thái nghệ thuật, nó hầu hết đã dừng lại 2-3 năm trước:
Chúng tôi từng theo dõi đổi mới NLP trên Repo Github này. Bản cập nhật hầu hết đã dừng lại 2-3 năm trước.
Một điểm chuẩn đáng chú ý nhấn mạnh sự thay đổi mô hình này là bảng xếp hạng SuperGlue, với mục nhập mới nhất vào tháng 12 năm 2022. Điều thú vị là khung thời gian này trùng khớp với sự ra đời của ChatGPT (3.5), đã gây ra làn sóng chấn động trong toàn bộ cộng đồng NLP.
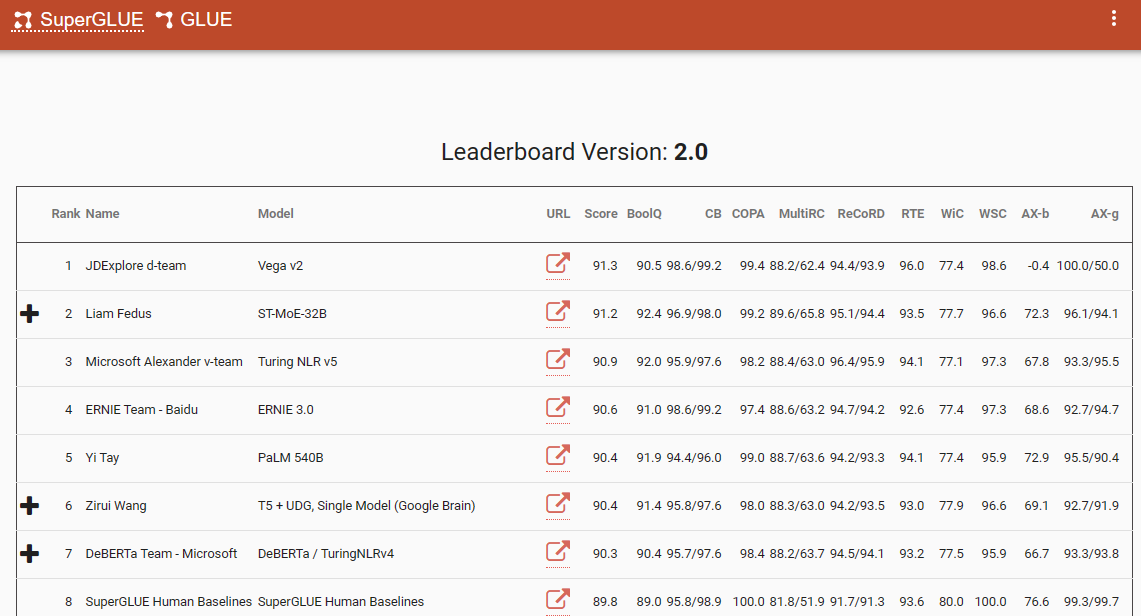
Bảng xếp hạng SuperGlue phổ biến cho đến khi ChatGPT ra đời
Bài báo nền tảng GPT-3, có tiêu đề phù hợp “Các mô hình ngôn ngữ là người học Few-Shot”, cung cấp bằng chứng thuyết phục về hiệu quả của học tập few-shot. Hình 2.1 trên trang 7 trong bài báo phân định sự khác biệt giữa các phương pháp học tập zero-shot, one-shot và few-shot, làm nổi bật sự vượt trội của phương pháp sau về hiệu quả và hiệu suất học tập.

Sự khác biệt giữa các phương pháp học tập zero-shot, one-shot và few-shot
Hơn nữa, để chứng minh hiệu quả của NLU dựa trên GenAI/LLM, Bảng 3.8 trên trang 19 cung cấp một so sánh trực tiếp giữa các phương pháp NLU có giám sát truyền thống và học tập Few-Shot của GPT-3. Trong so sánh này, GPT-3 Few-Shot vượt trội hơn Fine-tuned BERT-Large, một đại diện của học tập có giám sát được sử dụng bởi các hệ thống NLU dựa trên ý định/thực thể, trên nhiều tác vụ khác nhau.
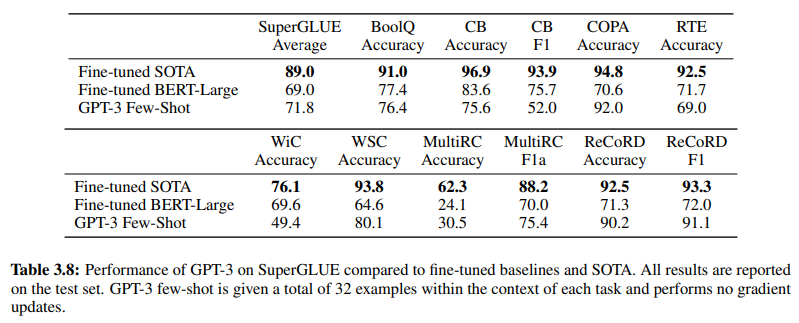
GPT-3 Few-Shot vượt trội hơn Fine-tuned BERT-Large trên nhiều tác vụ khác nhau
Sự vượt trội của GPT-3 Few-Shot không chỉ thể hiện rõ ở độ chính xác mà còn ở hiệu quả chi phí. Cả chi phí thiết lập ban đầu và chi phí bảo trì liên quan đến NLU dựa trên GenAI/LLM đều thấp hơn đáng kể so với các phương pháp truyền thống.
Bằng chứng thực nghiệm được trình bày trong cộng đồng NLP nhấn mạnh tác động biến đổi của NLU dựa trên GenAI/LLM. Nó đã chứng minh độ chính xác và hiệu quả chưa từng có. Tiếp theo, hãy kiểm tra hiệu quả chi phí của nó.
Yêu cầu dữ liệu đào tạo: Một phân tích so sánh
Một so sánh tiết lộ giữa NLU dựa trên ý định/thực thể và NLU dựa trên GenAI/LLM làm sáng tỏ các yêu cầu dữ liệu đào tạo khác nhau của chúng. Hình 3.8 trên trang 20 cho thấy sự tương phản rõ rệt:
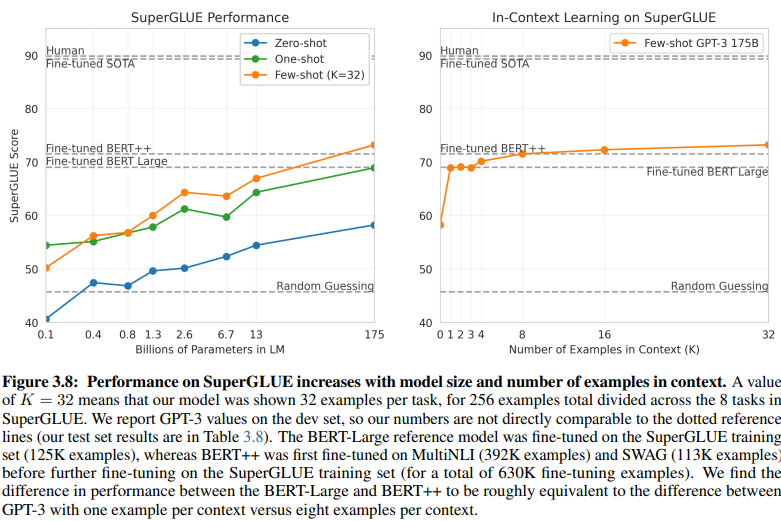
NLU dựa trên GenAI/LLM yêu cầu ít dữ liệu hơn nhiều để đào tạo
-
NLU học có giám sát: Cách tiếp cận truyền thống này yêu cầu một tập dữ liệu mở rộng, với hơn nửa triệu ví dụ (630K) cần thiết cho việc đào tạo hiệu quả.
-
GPT-3 Few-Shot: Ngược lại, NLU dựa trên GenAI/LLM thể hiện hiệu quả đáng kể, chỉ với 32 ví dụ cho mỗi tác vụ là đủ để tinh chỉnh hiệu quả.
Độ lớn của sự khác biệt này rất đáng kinh ngạc: 630.000 ví dụ so với chỉ 32. Việc giảm đáng kể các yêu cầu về dữ liệu đào tạo này giúp các doanh nghiệp áp dụng NLU dựa trên GenAI/LLM tiết kiệm chi phí đáng kể.
Ngoài ra, tác động ngụ ý đến thời gian phát triển là sâu sắc. Với NLU dựa trên GenAI/LLM, quy trình đào tạo rút ngắn sẽ đẩy nhanh việc triển khai các hệ thống NLU lên nhiều bậc, tạo điều kiện thuận lợi cho việc thích ứng và đổi mới nhanh chóng trong lĩnh vực xử lý ngôn ngữ tự nhiên.
Nói tóm lại, so sánh này nhấn mạnh tiềm năng biến đổi của NLU dựa trên GenAI/LLM, mang lại hiệu quả và hiệu quả chi phí chưa từng có trong các yêu cầu dữ liệu đào tạo và thời gian phát triển.
Nắm bắt sự tiến hóa: Tại sao NLU dựa trên GenAI/LLM chiếm ưu thế
Trong lĩnh vực hiểu ngôn ngữ tự nhiên, việc chuyển đổi từ các hệ thống dựa trên ý định/thực thể sang các giải pháp dựa trên GenAI/LLM đang diễn ra không thể chối cãi. Sự thay đổi này được thúc đẩy bởi vô số yếu tố làm nổi bật những hạn chế của NLU dựa trên ý định/thực thể truyền thống và những lợi thế hấp dẫn mà các phương pháp dựa trên GenAI/LLM mang lại.
NLU dựa trên ý định/thực thể ngày càng được coi là lỗi thời vì một số lý do thuyết phục:
-
Tính linh hoạt hạn chế: Các hệ thống NLU truyền thống phụ thuộc vào các ý định và thực thể được xác định trước, hạn chế khả năng thích ứng của chatbot và IVR với các đầu vào của người dùng khác với các danh mục được xác định trước này.
-
Thách thức bảo trì: Khi các hệ thống này mở rộng quy mô và số lượng ý định và thực thể tăng lên, độ phức tạp và thời gian cần thiết cho việc bảo trì và cập nhật tăng lên theo cấp số nhân.
-
Thiếu hiểu biết theo ngữ cảnh: Các hệ thống này thường gặp khó khăn trong việc nắm bắt các sắc thái ngữ cảnh phức tạp của các cuộc hội thoại, dẫn đến các phản hồi không chính xác hoặc cần thêm thông tin đầu vào của người dùng để làm rõ ý định.
-
Thiếu khả năng tạo: Các hệ thống NLU dựa trên ý định và thực thể vốn dĩ bị hạn chế trong khả năng tạo văn bản, giới hạn chúng trong các tác vụ tập trung vào phân loại ý định và trích xuất thực thể. Điều này hạn chế khả năng thích ứng của chatbot và IVR, thường dẫn đến các phản hồi đơn điệu không phù hợp với ngữ cảnh hội thoại.
Ngược lại, NLU dựa trên GenAI/LLM nổi lên như một xu hướng chủ đạo nhờ các thuộc tính biến đổi của nó:
-
Học tập thích ứng: Các mô hình GenAI có khả năng học tập linh hoạt từ các cuộc hội thoại thời gian thực, cho phép chúng tự động thích nghi với các chủ đề mới và hành vi của người dùng, mà không cần cập nhật thủ công.
-
Hiểu biết theo ngữ cảnh: Các mô hình này vượt trội trong việc hiểu các sắc thái ngữ cảnh phức tạp của các cuộc hội thoại, dẫn đến các phản hồi chính xác và phù hợp hơn, gây được tiếng vang với người dùng.
-
Học tập Few-Shot: Các mô hình GenAI có thể được đào tạo với số lượng ví dụ tối thiểu, hợp lý hóa quy trình đào tạo và giảm sự phụ thuộc vào các định nghĩa ý định và thực thể rõ ràng.
-
Tạo ngôn ngữ tự nhiên: GenAI/LLM tự hào có khả năng tạo văn bản, trao quyền cho chúng tạo ra các chatbot và các ứng dụng NLP khác cung cấp các phản hồi tự nhiên và phù hợp với ngữ cảnh.
Tương lai của AI đàm thoại phụ thuộc vào các hệ thống có thể học hỏi và thích ứng một cách hữu cơ, mang lại cho người dùng trải nghiệm liền mạch và trực quan. NLU dựa trên GenAI/LLM thể hiện sự tiến hóa này, cung cấp một cách tiếp cận năng động và linh hoạt vượt qua những hạn chế của các hệ thống dựa trên ý định/thực thể truyền thống.
Nói tóm lại, quỹ đạo chủ đạo của NLU được xác định rõ ràng bởi sự trỗi dậy của các phương pháp dựa trên GenAI/LLM, báo trước một kỷ nguyên mới của AI đàm thoại ưu tiên khả năng thích ứng, tính ngữ cảnh và lấy người dùng làm trung tâm.


