





सभी ग्राहक सेवा या विपणन निदेशकों को, यदि आपका बॉस आपसे निम्नलिखित प्रश्न पूछता है, तो उन्हें यह लेख भेजें:
“इंटेंट/एंटिटी-आधारित NLU अप्रचलित क्यों है और LLM/GenAI स्पष्ट प्रवृत्ति क्यों है?”
प्राकृतिक भाषा समझ (NLU) प्रणालियों का उद्देश्य प्राकृतिक भाषा इनपुट, जैसे टेक्स्ट या भाषण को संसाधित और विश्लेषण करना है, ताकि अर्थ निकाला जा सके, प्रासंगिक जानकारी निकाली जा सके और संचार के पीछे की अंतर्निहित मंशा को समझा जा सके। NLU विभिन्न AI अनुप्रयोगों का एक मूलभूत घटक है, जिसमें वर्चुअल असिस्टेंट, चैटबॉट, भावना विश्लेषण उपकरण, भाषा अनुवाद प्रणाली और बहुत कुछ शामिल हैं। यह मानव-कंप्यूटर इंटरैक्शन को सक्षम करने और प्राकृतिक भाषा इनपुट को समझने और प्रतिक्रिया देने में सक्षम बुद्धिमान प्रणालियों के विकास को सुविधाजनक बनाने में महत्वपूर्ण भूमिका निभाता है।
यह प्रश्न स्थापित ग्राहकों से आता है जो अपने IVR और चैटबॉट दृष्टिकोण पर फिर से विचार कर रहे हैं। वे NLU-आधारित तकनीक स्टैक की पिछली पीढ़ी में बंद हैं, जो आमतौर पर बड़े तकनीकी खिलाड़ियों जैसे: Microsoft Bot Framework (या luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU द्वारा पेश किए जाते हैं।
चुनौती यह है कि बीमा कंपनियों, वित्तीय संस्थानों, सरकारों, एयरलाइंस/कार डीलरशिप और अन्य बड़े सौदों जैसे प्रमुख ग्राहकों ने पहले ही पिछली पीढ़ी की तकनीक तैनात कर दी है। लेकिन चूंकि इंटेंट/एंटिटी-आधारित NLU स्केलेबल नहीं है, इसलिए ग्राहकों को अपने NLU सिस्टम को बनाए रखने और अपग्रेड करने के लिए हर साल लाखों डॉलर खर्च करने पड़ते हैं। स्केलेबिलिटी की यह कमी रखरखाव लागत में वृद्धि में योगदान करती है, अंततः पिछली पीढ़ी के NLU प्रदाताओं को उनके ग्राहकों की कीमत पर लाभ पहुंचाती है। क्योंकि वे स्केल नहीं करते हैं, रखरखाव लागत साल-दर-साल अधिक होती है।
इंटेंट/एंटिटी-आधारित NLU प्रभावी ढंग से स्केल करने में विफल क्यों होता है?
मुख्य कारण मॉडल की सीमित भेदभावपूर्ण शक्ति में निहित है। ऐसा क्यों है, इसका विवरण यहां दिया गया है:
-
न्यूनतम इंटेंट आवश्यकता: NLU मॉडल को प्रभावी ढंग से प्रशिक्षित करने के लिए कम से कम दो अलग-अलग इंटेंट की आवश्यकता होती है। उदाहरण के लिए, मौसम के बारे में पूछते समय, इंटेंट स्पष्ट हो सकता है, लेकिन प्रत्येक क्वेरी के पीछे कई संभावित इंटेंट होते हैं, जैसे कि एक फॉलबैक या गैर-मौसम संबंधी पूछताछ जैसे “आप कैसे हैं?”
-
प्रशिक्षण डेटा की मांग: बड़ी तकनीकी कंपनियां प्रभावी प्रशिक्षण के लिए प्रति इंटेंट हजारों सकारात्मक उदाहरणों की मांग करती हैं। यह व्यापक डेटासेट मॉडल के लिए विभिन्न इंटेंट के बीच सटीक रूप से सीखने और भेदभाव करने के लिए आवश्यक है।
-
सकारात्मक और नकारात्मक उदाहरणों को संतुलित करना: एक इंटेंट में सकारात्मक उदाहरण जोड़ने के लिए अन्य इंटेंट के लिए नकारात्मक उदाहरणों को शामिल करना आवश्यक है। यह संतुलित दृष्टिकोण सुनिश्चित करता है कि NLU मॉडल सकारात्मक और नकारात्मक दोनों उदाहरणों से प्रभावी ढंग से सीख सके।
-
विविध उदाहरण सेट: ओवरफिटिंग को रोकने और विभिन्न संदर्भों में सामान्यीकरण करने की मॉडल की क्षमता को बढ़ाने के लिए सकारात्मक और नकारात्मक दोनों उदाहरण विविध होने चाहिए।
-
नए इंटेंट जोड़ने की जटिलता: मौजूदा NLU मॉडल में एक नया इंटेंट जोड़ना एक श्रमसाध्य प्रक्रिया है। हजारों सकारात्मक और नकारात्मक उदाहरणों को जोड़ा जाना चाहिए, जिसके बाद इसके आधारभूत प्रदर्शन को बनाए रखने के लिए मॉडल को फिर से प्रशिक्षित किया जाना चाहिए। इंटेंट की संख्या बढ़ने के साथ यह प्रक्रिया तेजी से चुनौतीपूर्ण होती जाती है।
प्रिस्क्राइबिंग इफेक्ट: इंटेंट/एंटिटी-आधारित NLU का नुकसान

इंटेंट/एंटिटी-आधारित NLU का प्रिस्क्राइबिंग इफेक्ट
चिकित्सा में “प्रिस्क्राइबिंग कैस्केड” के रूप में जानी जाने वाली घटना के अनुरूप, इंटेंट/एंटिटी-आधारित NLU की स्केलेबिलिटी चुनौतियों की तुलना प्रिस्क्रिप्शन के एक भयावह कैस्केड से की जा सकती है। एक बुजुर्ग व्यक्ति की कल्पना करें जो ढेर सारी दैनिक दवाओं से बोझिल है, प्रत्येक को पिछली दवा के दुष्प्रभावों को दूर करने के लिए निर्धारित किया गया है। यह परिदृश्य बहुत परिचित है, जहां दवा ए की शुरुआत से ऐसे दुष्प्रभाव होते हैं जिनके लिए दवा बी को निर्धारित करने की आवश्यकता होती है। हालांकि, दवा बी अपने स्वयं के दुष्प्रभावों का एक सेट पेश करती है, जिससे दवा सी की आवश्यकता होती है, और इसी तरह। नतीजतन, बुजुर्ग व्यक्ति खुद को प्रबंधित करने के लिए ढेर सारी गोलियों से घिरा पाता है - एक प्रिस्क्राइबिंग कैस्केड।
एक और दृष्टांत रूपक ब्लॉक के एक टॉवर के निर्माण का है, जिसमें प्रत्येक ब्लॉक एक दवा का प्रतिनिधित्व करता है। प्रारंभ में, दवा ए रखी जाती है, लेकिन इसकी अस्थिरता (दुष्प्रभाव) इसे स्थिर करने के लिए दवा बी को जोड़ने के लिए प्रेरित करती है। हालांकि, यह नया जोड़ सहजता से एकीकृत नहीं हो सकता है, जिससे टॉवर और अधिक झुक जाता है (बी का दुष्प्रभाव)। इस अस्थिरता को ठीक करने के प्रयास में, अधिक ब्लॉक (दवाएं सी, डी, आदि) जोड़े जाते हैं, जिससे टॉवर की अस्थिरता और ढहने की संवेदनशीलता बढ़ जाती है - कई दवाओं से उत्पन्न होने वाली संभावित स्वास्थ्य जटिलताओं का एक प्रतिनिधित्व।

इंटेंट/एंटिटी-आधारित NLU के लिए एक और दृष्टांत रूपक ब्लॉक के एक टॉवर का निर्माण है
इसी तरह, NLU प्रणाली में जोड़े गए प्रत्येक नए इंटेंट के साथ, ब्लॉक का रूपक टॉवर लंबा होता जाता है, जिससे अस्थिरता बढ़ती है। सुदृढीकरण की आवश्यकता बढ़ती है, जिसके परिणामस्वरूप रखरखाव लागत अधिक होती है। नतीजतन, जबकि इंटेंट/एंटिटी-आधारित NLU शुरू में प्रदाताओं के लिए आकर्षक लग सकता है, वास्तविकता यह है कि ग्राहकों के लिए इसे बनाए रखना अत्यधिक बोझिल हो जाता है। इन प्रणालियों में स्केलेबिलिटी की कमी होती है, जिससे प्रदाताओं और ग्राहकों दोनों के लिए महत्वपूर्ण चुनौतियां पैदा होती हैं। अगले खंडों में, हम यह पता लगाएंगे कि GenAI/LLM-आधारित NLU इन चुनौतियों को प्रभावी ढंग से संबोधित करने के लिए अधिक टिकाऊ और स्केलेबल विकल्प कैसे प्रदान करता है।
GenAI/LLM-आधारित NLU: एक लचीला समाधान
GenAI/LLM-आधारित NLU इंटेंट/एंटिटी-आधारित प्रणालियों द्वारा सामना की जाने वाली स्केलेबिलिटी चुनौतियों का एक मजबूत समाधान प्रदान करता है। यह मुख्य रूप से दो प्रमुख कारकों के लिए जिम्मेदार है:
-
पूर्व-प्रशिक्षण और विश्व ज्ञान: GenAI/LLM मॉडल को बड़ी मात्रा में डेटा पर पूर्व-प्रशिक्षित किया जाता है, जिससे वे विश्व ज्ञान का खजाना प्राप्त कर सकते हैं। यह संचित ज्ञान विभिन्न इंटेंट के बीच अंतर करने में महत्वपूर्ण भूमिका निभाता है, जिससे नकारात्मक उदाहरणों के खिलाफ मॉडल की भेदभावपूर्ण क्षमताओं में वृद्धि होती है।
-
फ्यू-शॉट लर्निंग: GenAI/LLM-आधारित NLU की एक विशिष्ट विशेषता इसकी फ्यू-शॉट लर्निंग तकनीकों का उपयोग करने की क्षमता है। पारंपरिक तरीकों के विपरीत, जिन्हें प्रत्येक इंटेंट के लिए व्यापक प्रशिक्षण डेटा की आवश्यकता होती है, फ्यू-शॉट लर्निंग मॉडल को केवल कुछ उदाहरणों से सीखने में सक्षम बनाता है। यह कुशल सीखने का दृष्टिकोण न्यूनतम डेटा के साथ इच्छित उद्देश्यों को पुष्ट करता है, जिससे प्रशिक्षण का बोझ काफी कम हो जाता है।
इस परिदृश्य पर विचार करें: जब आपको पाठक के रूप में “आज मौसम कैसा है?” क्वेरी प्रस्तुत की जाती है, तो आप स्वाभाविक रूप से इसे दैनिक रूप से सामना किए जाने वाले कई वाक्यों के बीच मौसम के बारे में एक पूछताछ के रूप में पहचानते हैं। इरादे को समझने की यह जन्मजात क्षमता फ्यू-शॉट लर्निंग की अवधारणा के समान है।
वयस्कों के रूप में, हमारे दिमाग को एक विशाल शब्दावली के साथ पूर्व-प्रशिक्षित किया जाता है, जो 20 साल की उम्र तक लगभग 150 मिलियन शब्दों का अनुमान है। यह व्यापक भाषाई जोखिम हमें नए इरादों का सामना करने पर उन्हें जल्दी से समझने में सक्षम बनाता है, सुदृढीकरण के लिए केवल कुछ उदाहरणों की आवश्यकता होती है।
अर्बन डिक्शनरी कार्रवाई में फ्यू-शॉट लर्निंग के उदाहरणों की खोज के लिए एक उत्कृष्ट संसाधन के रूप में कार्य करती है, जो त्वरित समझ को सुविधाजनक बनाने में इसकी प्रभावकारिता को और अधिक दर्शाती है।
GenAI/LLM-आधारित NLU में निहित फ्यू-शॉट लर्निंग क्षमता लागत को कम करने और स्केलेबिलिटी को सक्षम करने में महत्वपूर्ण है। पूर्व-प्रशिक्षण के दौरान प्रशिक्षण का अधिकांश भाग पहले ही पूरा हो जाने के कारण, न्यूनतम संख्या में उदाहरणों के साथ मॉडल को ठीक करना प्राथमिक ध्यान केंद्रित हो जाता है, जिससे प्रक्रिया सुव्यवस्थित होती है और स्केलेबिलिटी बढ़ती है।
GenAI/LLM-आधारित NLU: परिणाम और साक्ष्य प्रदान करना
मार्च 2024 तक, प्राकृतिक भाषा प्रसंस्करण (NLP) के परिदृश्य में एक महत्वपूर्ण बदलाव आया है, जिसे GenAI/LLM-आधारित NLU के उद्भव से चिह्नित किया गया है। NLP नवाचार में एक बार की प्रमुख प्रगति पिछले 2-3 वर्षों में स्थिर हो गई है, जैसा कि अत्याधुनिक प्रगति में ठहराव से स्पष्ट है। यदि आप अत्याधुनिक के लिए एक बार के सबसे हॉट NLP प्रगति की जांच करते हैं, तो यह ज्यादातर 2-3 साल पहले रुक गया था:
हम इस Github रेपो पर NLP नवाचार को ट्रैक करते थे। अपडेट ज्यादातर 2-3 साल पहले रुक गया था।
एक उल्लेखनीय बेंचमार्क जो इस प्रतिमान बदलाव को रेखांकित करता है, वह सुपरग्लू लीडरबोर्ड है, जिसमें दिसंबर 2022 में इसकी नवीनतम प्रविष्टि है। दिलचस्प बात यह है कि यह समय सीमा चैटजीपीटी (3.5) की शुरुआत के साथ मेल खाती है, जिसने एनएलपी समुदाय में झटके भेजे।
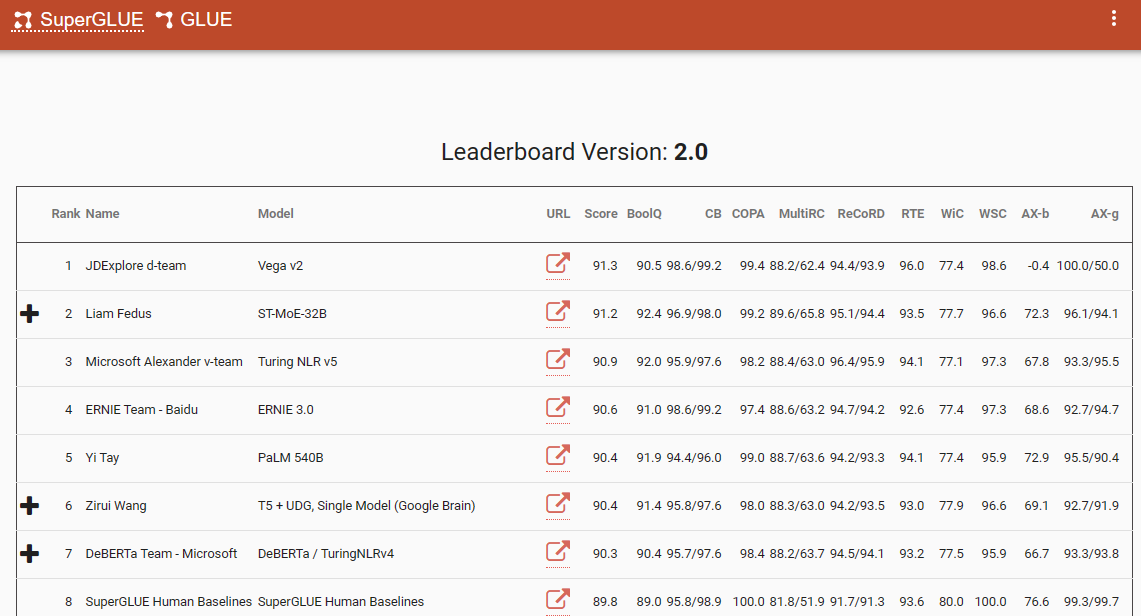
चैटजीपीटी की शुरुआत तक सुपरग्लू लीडरबोर्ड लोकप्रिय था
सेमिनल GPT-3 पेपर, जिसका उपयुक्त शीर्षक “भाषा मॉडल फ्यू-शॉट लर्नर हैं” है, फ्यू-शॉट लर्निंग की प्रभावकारिता का सम्मोहक प्रमाण प्रदान करता है। पेपर में पृष्ठ 7 पर चित्र 2.1 शून्य-शॉट, वन-शॉट और फ्यू-शॉट लर्निंग दृष्टिकोणों के बीच के अंतरों को दर्शाता है, जो सीखने की दक्षता और प्रभावशीलता के संदर्भ में बाद वाले की श्रेष्ठता पर प्रकाश डालता है।

शून्य-शॉट, वन-शॉट और फ्यू-शॉट लर्निंग दृष्टिकोणों के बीच के अंतर
इसके अलावा, GenAI/LLM-आधारित NLU की प्रभावकारिता की पुष्टि करते हुए, पृष्ठ 19 पर तालिका 3.8 पारंपरिक पर्यवेक्षित NLU विधियों और GPT-3 फ्यू-शॉट लर्निंग के बीच सीधी तुलना प्रदान करती है। इस तुलना में, GPT-3 फ्यू-शॉट विभिन्न कार्यों में फाइन-ट्यून किए गए BERT-लार्ज को पार करता है, जो इंटेंट/एंटिटी-आधारित NLU सिस्टम द्वारा नियोजित पर्यवेक्षित सीखने का एक प्रतिनिधित्व है।
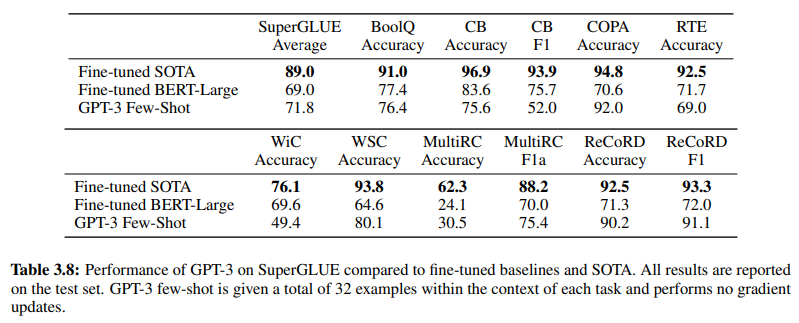
GPT-3 फ्यू-शॉट विभिन्न कार्यों में फाइन-ट्यून किए गए BERT-लार्ज को पार करता है
GPT-3 फ्यू-शॉट की श्रेष्ठता न केवल इसकी सटीकता में स्पष्ट है, बल्कि इसकी लागत-दक्षता में भी है। GenAI/LLM-आधारित NLU से जुड़ी प्रारंभिक सेटअप और रखरखाव लागत दोनों पारंपरिक तरीकों की तुलना में काफी कम हैं।
एनएलपी समुदाय में प्रस्तुत अनुभवजन्य साक्ष्य GenAI/LLM-आधारित NLU के परिवर्तनकारी प्रभाव को रेखांकित करते हैं। इसने पहले ही अपनी अद्वितीय सटीकता और दक्षता का प्रदर्शन किया है। अगला, आइए इसकी लागत-दक्षता की जांच करें।
प्रशिक्षण डेटा आवश्यकताएँ: एक तुलनात्मक विश्लेषण
इंटेंट/एंटिटी-आधारित NLU और GenAI/LLM-आधारित NLU के बीच एक खुलासा करने वाली तुलना उनके अलग-अलग प्रशिक्षण डेटा आवश्यकताओं पर प्रकाश डालती है। पृष्ठ 20 पर चित्र 3.8 एक स्पष्ट विरोधाभास प्रस्तुत करता है:
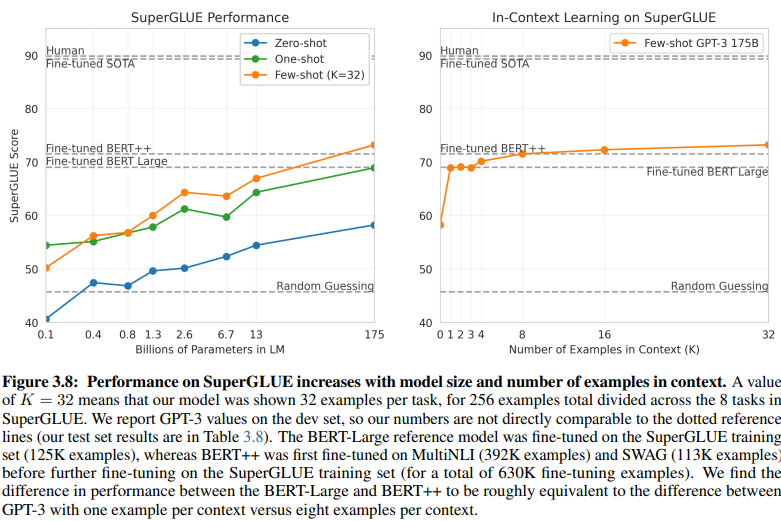
GenAI/LLM-आधारित NLU को प्रशिक्षण के लिए बहुत कम डेटा की आवश्यकता होती है
-
पर्यवेक्षित शिक्षण NLU: इस पारंपरिक दृष्टिकोण को एक व्यापक डेटासेट की आवश्यकता होती है, जिसमें प्रभावी प्रशिक्षण के लिए आधे मिलियन से अधिक उदाहरण (630K) की आवश्यकता होती है।
-
फ्यू-शॉट GPT-3: इसके विपरीत, GenAI/LLM-आधारित NLU उल्लेखनीय दक्षता प्रदर्शित करता है, जिसमें प्रभावी ट्यूनिंग के लिए प्रति कार्य केवल 32 उदाहरण पर्याप्त होते हैं।
इस अंतर का परिमाण चौंकाने वाला है: 630,000 उदाहरण बनाम केवल 32। प्रशिक्षण डेटा आवश्यकताओं में यह नाटकीय कमी GenAI/LLM-आधारित NLU को अपनाने वाले व्यवसायों के लिए महत्वपूर्ण लागत बचत में तब्दील होती है।
इसके अलावा, विकास समय-सीमा पर निहित प्रभाव गहरा है। GenAI/LLM-आधारित NLU के साथ, छोटा प्रशिक्षण प्रक्रिया प्राकृतिक भाषा प्रसंस्करण के क्षेत्र में तेजी से अनुकूलन और नवाचार की सुविधा प्रदान करते हुए NLU प्रणालियों की तैनाती को कई गुना तेज करती है।
संक्षेप में, यह तुलना GenAI/LLM-आधारित NLU की परिवर्तनकारी क्षमता को रेखांकित करती है, जो प्रशिक्षण डेटा आवश्यकताओं और विकास समय-सीमा में अद्वितीय दक्षता और लागत-दक्षता प्रदान करती है।
विकास को अपनाना: GenAI/LLM-आधारित NLU क्यों प्रबल है
प्राकृतिक भाषा समझ के क्षेत्र में, इंटेंट/एंटिटी-आधारित प्रणालियों से GenAI/LLM-आधारित समाधानों में संक्रमण निर्विवाद रूप से चल रहा है। यह बदलाव कई कारकों से प्रेरित है जो पारंपरिक इंटेंट/एंटिटी-आधारित NLU की सीमाओं और GenAI/LLM-आधारित दृष्टिकोणों द्वारा प्रदान किए गए सम्मोहक लाभों को रेखांकित करते हैं।
इंटेंट/एंटिटी-आधारित NLU को कई सम्मोहक कारणों से तेजी से अप्रचलित माना जा रहा है:
-
सीमित लचीलापन: पारंपरिक NLU सिस्टम पूर्वनिर्धारित इंटेंट और एंटिटी पर निर्भर करते हैं, जो चैटबॉट और IVR की अनुकूलनशीलता को उपयोगकर्ता इनपुट तक सीमित करते हैं जो इन पूर्वनिर्धारित श्रेणियों से विचलित होते हैं।
-
रखरखाव चुनौतियां: जैसे-जैसे ये सिस्टम स्केल करते हैं और इंटेंट और एंटिटी की संख्या बढ़ती है, रखरखाव और अपडेट के लिए आवश्यक जटिलता और समय तेजी से बढ़ता है।
-
प्रासंगिक समझ की कमी: ये सिस्टम अक्सर बातचीत के जटिल प्रासंगिक बारीकियों को समझने में विफल रहते हैं, जिसके परिणामस्वरूप गलत प्रतिक्रियाएं होती हैं या इरादों को स्पष्ट करने के लिए अतिरिक्त उपयोगकर्ता इनपुट की आवश्यकता होती है।
-
उत्पत्ति की कमी: इंटेंट और एंटिटी-आधारित NLU सिस्टम स्वाभाविक रूप से टेक्स्ट उत्पन्न करने की अपनी क्षमता में सीमित हैं, जो उन्हें इंटेंट को वर्गीकृत करने और एंटिटी निकालने के आसपास केंद्रित कार्यों तक सीमित करते हैं। यह चैटबॉट और IVR की अनुकूलनशीलता को प्रतिबंधित करता है, जिससे अक्सर नीरस प्रतिक्रियाएं होती हैं जो संवादी संदर्भ के अनुरूप नहीं होती हैं।
इसके विपरीत, GenAI/LLM-आधारित NLU अपने परिवर्तनकारी गुणों के कारण प्रमुख प्रवृत्ति के रूप में उभरता है:
-
अनुकूली शिक्षण: GenAI मॉडल में वास्तविक समय की बातचीत से गतिशील रूप से सीखने की क्षमता होती है, जिससे वे मैन्युअल अपडेट की आवश्यकता के बिना नए विषयों और उपयोगकर्ता व्यवहारों के अनुकूल हो सकते हैं।
-
प्रासंगिक समझ: ये मॉडल बातचीत के जटिल प्रासंगिक बारीकियों को समझने में उत्कृष्ट हैं, जिसके परिणामस्वरूप अधिक सटीक और प्रासंगिक प्रतिक्रियाएं होती हैं जो उपयोगकर्ताओं के साथ प्रतिध्वनित होती हैं।
-
फ्यू-शॉट लर्निंग: GenAI मॉडल को न्यूनतम उदाहरणों के साथ प्रशिक्षित किया जा सकता है, जिससे प्रशिक्षण प्रक्रिया सुव्यवस्थित होती है और स्पष्ट इंटेंट और एंटिटी परिभाषाओं पर निर्भरता कम होती है।
-
प्राकृतिक भाषा पीढ़ी: GenAI/LLM में टेक्स्ट उत्पन्न करने की क्षमता होती है, जिससे वे चैटबॉट और अन्य एनएलपी एप्लिकेशन बना सकते हैं जो प्राकृतिक और प्रासंगिक रूप से प्रासंगिक प्रतिक्रियाएं प्रदान करते हैं।
संवादी एआई का भविष्य उन प्रणालियों पर निर्भर करता है जो स्वाभाविक रूप से सीख और अनुकूलित हो सकती हैं, जिससे उपयोगकर्ताओं को एक सहज और सहज अनुभव मिलता है। GenAI/LLM-आधारित NLU इस विकास का प्रतीक है, जो एक गतिशील और लचीला दृष्टिकोण प्रदान करता है जो पारंपरिक इंटेंट/एंटिटी-आधारित प्रणालियों की बाधाओं को पार करता है।
संक्षेप में, NLU का प्रचलित प्रक्षेपवक्र GenAI/LLM-आधारित दृष्टिकोणों के उदय से स्पष्ट रूप से परिभाषित होता है, जो संवादी एआई के एक नए युग की शुरुआत करता है जो अनुकूलनशीलता, प्रासंगिकता और उपयोगकर्ता-केंद्रितता को प्राथमिकता देता है।


