





De-a lungul acestei serii de bloguri, urmăriți călătoria Seasalt.ai către crearea unei experiențe complete de întâlniri moderne, începând cu începuturile sale umile, până la optimizarea serviciului nostru pe diferite hardware și modele, la integrarea sistemelor NLP de ultimă generație și, în final, la realizarea completă a SeaMeet, soluțiile noastre colaborative pentru întâlniri moderne.
Dincolo de algoritm
Întâlnirile moderne au fost o demonstrație fantastică, dar cumva a rămas o demonstrație. Mai este un drum lung de parcurs pentru a o face gata de producție. Am implementat cu succes mai întâi versiunea demo cu stiva Microsoft Azure. Dar recunoscând toate capcanele software-ului, am decis să înlocuim algoritmii cu ai noștri și, de asemenea, să facem întreaga experiență mult mai fluidă și mai ușoară, cu mai multă flexibilitate. Există patru componente majore ale întâlnirilor moderne, așa cum este ilustrat mai jos:
- Procesarea semnalului pe matricea de microfoane, cel mai vizibil, formarea fasciculului
- Diarizarea și identificarea vorbitorului
- Recunoașterea vorbirii personalizată
- O interfață de utilizator mai bună
În continuare vom detalia toate componentele importante.

Am adaptat toate cele 4 componente majore ale întâlnirilor moderne cu propria noastră stivă tehnologică: 1. Procesarea semnalului cu matricea de microfoane; 2. Diarizarea și identificarea vorbitorului; 3. Recunoașterea vorbirii personalizată; 4. O interfață web modernă.
Procesarea semnalului pe matricea de microfoane
Matricea de microfoane, în comparație cu un singur microfon de aproape, captează vocile dintr-un unghi de 360 de grade, până la o distanță de 5 metri. Astfel, o singură matrice de microfoane este capabilă să colecteze vocea într-o sală de conferințe de dimensiuni medii, de 10 pe 10 metri. Deoarece toate microfoanele sunt grupate pe un singur dispozitiv, reduce semnificativ cantitatea de fire care aglomerează sala de conferințe și simplifică configurarea și întreținerea. Pe de altă parte, scopul final al utilizării unei matrice de microfoane este de a oferi modelelor noastre cele mai bune date posibile. Așadar, înainte de a introduce sunetul prin recunoașterea automată a vorbirii, efectuăm mai întâi mai mulți algoritmi de procesare a semnalului. Componenta principală a pipeline-ului nostru de preprocesare implică un algoritm cunoscut sub numele de beamforming. Deoarece lucrăm cu matrice de microfoane circulare, multiple, putem utiliza diferența de timp minusculă necesară pentru ca sunetul să ajungă la diferitele microfoane. Ceea ce face beamforming-ul este să determine principalele caracteristici ale semnalului — cunoscut și sub numele de cel mai bun fascicul — și să accentueze aceste frecvențe, atenuând în același timp sunetele nedorite. Efectul este denoising și dereverberation, în timp ce semnalul principal, în cazul nostru vorbirea, devine mai puternic și mai clar.
Pentru o performanță optimă a multor algoritmi de beamforming, ar trebui să cunoaștem poziția exactă a sursei (vorbitorului) în raport cu microfonul. Dar, deoarece într-o aplicație reală acest lucru este imposibil, calculăm mai întâi ceea ce sunt cunoscute sub numele de ponderi de câmp îndepărtat, determinând direcția sursei. Acest prim pas, cunoscut sub numele de localizare a sursei, sau mai precis Direcția de sosire (DOA), s-a dovedit a fi dificil. Principala problemă cu care ne-am confruntat a fost netezirea. Algoritmul ne-a dat aproximativ rezultatul corect, dar sursa determinată fluctua constant între 30 de grade de fiecare parte a direcției reale, ceea ce a afectat beamforming-ul. Soluția pe care am găsit-o a fost să permitem algoritmului de localizare a sursei să utilizeze doar gama de frecvențe care codifică cea mai mare parte a vorbirii umane. Am cuplat acest lucru cu o tehnică de netezire în care am păstrat un „istoric” al rezultatelor DOA pentru a face o medie. Cu rezultate DOA mai fiabile, am putut apoi calcula ponderile de câmp îndepărtat și le-am folosit pentru a determina cel mai bun fascicul.
Cu seria de algoritmi efectuați pe Kinect DK: beamforming, denoising, dereverberation, localizare a sursei, am reușit să producem vorbire umană clară și îmbunătățită în timp real, indicând în același timp direcția aproximativă de unde se află vorbitorul. Acest lucru va ajuta foarte mult la identificarea vorbitorului în pasul următor.
Diarizarea și identificarea vorbitorului
Următoarea componentă a unui sistem de transcriere a întâlnirilor de ultimă generație este recunoașterea sau identificarea automată a vorbitorului. Așa cum s-a menționat în ultima trimitere a acestei serii, citirea unei grămezi neorganizate de text conversațional fără informații despre cine a spus ce este frustrant și anulează complet scopul de a avea un astfel de sistem. Aici intervine recunoașterea vorbitorului, cunoscută și sub numele de identificarea vorbitorului.
Cu această componentă putem alinia automat transcrierile și sunetul cu numele vorbitorului. Pentru a realiza acest lucru, folosim un proces cunoscut sub numele de diarizare care grupează segmentele audio într-un număr dat de grupuri reprezentând numărul de vorbitori din acea înregistrare. Acest lucru funcționează prin utilizarea unui sistem de Detectare a activității vocale (VAD) pentru a determina segmentele de vorbire, din care putem extrage o reprezentare vectorială a unei ferestre scurte. Fiecare vector extras din ferestre se numește xvector la nivel de enunț și, atunci când este mediat, obținem un x-vector la nivel de vorbitor. Acești x-vectori sunt apoi rulați printr-un algoritm de grupare, unde fiecare grup reprezintă segmentele de vorbire care aparțin aceluiași vorbitor. Merită menționat că alegerea algoritmului de grupare afectează foarte mult performanța diarizării și am obținut o rată de eroare de diarizare (DER) optimă cu gruparea spectrală folosind o matrice de afinitate pragată auto-reglată cu valori Normalized Maximum Eigengap (NME). În cele din urmă, trebuie să decidem ce vorbitor reprezintă fiecare grup. Înainte de întâlnire, am putea efectua un proces de înregistrare pentru a extrage x-vectori din înregistrări de 40 de secunde ale fiecărui vorbitor, pe care le putem compara cu grupurile pentru a identifica vorbitorul corespunzător.
Frumusețea acestui pipeline constă în flexibilitatea sa. Pentru multe scenarii de întâlniri, este nepractic și adesea imposibil să obții înregistrări pentru fiecare vorbitor în avans. Luați în considerare întâlnirile de afaceri cu clienți VIP sau simpozioane mari cu 50 de vorbitori. În acest caz, sărind peste pasul de înregistrare, sistemul nostru de diarizare poate totuși să sorteze segmentele de vorbire și să le grupeze pe cele care aparțin aceluiași vorbitor. Tot ce este nevoie este ca un om să eșantioneze câteva secunde din fiecare grup pentru a determina identitatea vorbitorului. Împreună cu o interfață de utilizator modernă dedicată, putem oferi aceeași funcționalitate, dar cu mai multă flexibilitate.
Recunoașterea vorbirii personalizată
După ce am cunoscut transcriptorul de întâlniri al Microsoft și ceea ce îl face atât de puternic, am fost gata să facem sistemul nostru complet independent și să depășim un produs deja revoluționar. Forța motrice din spatele întâlnirilor moderne și a oricărui produs de transcriere sunt modelele de Recunoaștere automată a vorbirii (ASR). Astfel, în mod natural, acest lucru ne-a atras cea mai mare atenție. Azure Cognitive Services a oferit o multitudine de modele din care să alegem, din multe limbi și dialecte. Cu toate acestea, performanța dintre diferitele dialecte a fost greu de distins. Pentru dialectele engleze separate, este probabil ca cel mai mult efort și date să fi fost depuse în modelul de engleză americană, care a fost apoi ajustat pe date accentuate pentru a crea diversele modele de dialect. Am vrut să ne asigurăm că, dacă oferim un model distinct, acesta este adaptat unui caz de utilizare specific. Acest lucru a însemnat procurarea a mii de ore de audio și transcrieri localizate și săptămâni de antrenament și ajustare fină. Dar a meritat satisfacția de a vedea modelele noastre îmbunătățindu-se la fiecare epocă și de a livra ceea ce am promis.
Odată ce am avut un model fundamental solid, următorul pas a fost extinderea utilizabilității și personalizării. Fiecare industrie vine cu o mulțime de jargon propriu, ceea ce face dificil pentru modelele ASR să descifreze între vocabularul ezoteric și un șir de cuvinte comune, fonetic similare.
Răspunsul nostru este SeaVoice, care oferă o locație centralizată unde utilizatorii pot ajusta cu ușurință modelele pentru nevoile lor specifice.
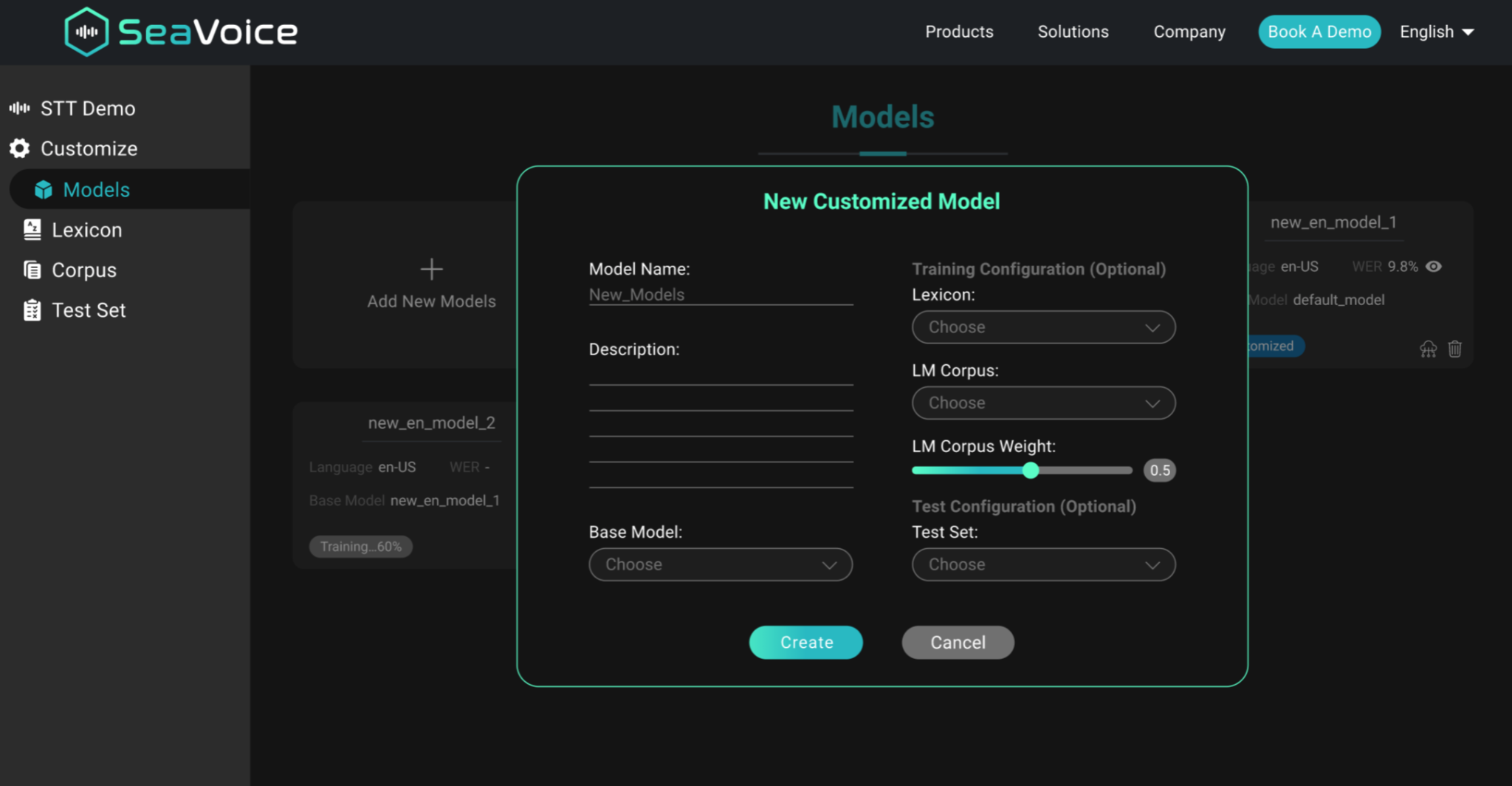
Produsul de recunoaștere a vorbirii SeaVoice de la Seasalt.ai oferă o personalizare profundă a modelelor de vorbire.
SeaVoice permite utilizatorilor să personalizeze cu ușurință fiecare componentă dintr-un pipeline ASR: lexicon, modele lingvistice și modele acustice. Predarea unui vocabular nou modelului este la fel de simplă ca asocierea noilor cuvinte cu o transcriere fonetică.
Cu GPU-uri și CPU-uri moderne, am reușit să ajustăm un model de vorbire în câteva minute și, de asemenea, să oferim decodare în timp real, astfel încât să nu existe întârzieri la recunoașterea vorbirii primite.
Până acum, am înlocuit toți algoritmii interni de bază ai Azure Speech Services cu soluția noastră internă. Acest lucru a făcut sistemul extrem de versatil și independent. Clienții enterprise favorizează acest lucru și datorită capacităților de implementare on-premise pentru a proteja confidențialitatea. După ce am lucrat din greu la backend, am ajuns în cele din urmă la punctul de a îmbunătăți experiența utilizatorului frontend.
O interfață de utilizator modernă și SeaMeet se naște
A mai rămas o singură piesă pentru a finaliza plecarea noastră de la Azure Speech Service: o interfață de utilizator proaspătă care să fie fața definitivă a întâlnirilor moderne. Ne-am propus să depășim designul pur funcțional de la Azure și interfața „curată” de la prezentarea Microsoft Build 2019. De data aceasta am vizat eleganța și valoarea adăugată.

Mai întâi, oferim transcrieri în timp real, urmate de procesare offline suplimentară pentru a efectua diarizarea și identificarea vorbitorului. În cele din urmă, am făcut un efort suplimentar pentru a extrage informații din întâlnire, extragând subiectele întâlnirii, acțiunile, minutele și rezumatele. Vom detalia aceste informații în următorul blog.
În cele din urmă, SeaMeet, o reimplementare și îmbunătățire modernă a întâlnirilor moderne Microsoft, s-a născut. Interfața de utilizator este receptivă și informativă, oferind mult mai multă valoare decât propunerea inițială.
 | 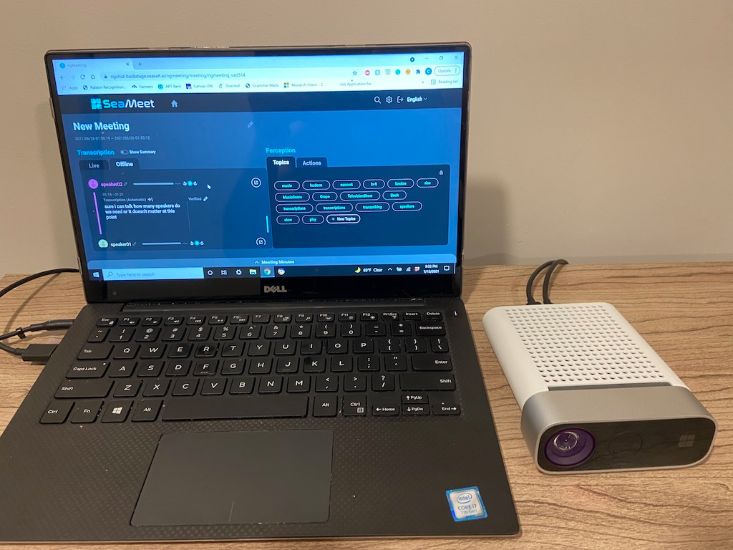 |
|---|
O comparație alăturată a implementării originale a întâlnirilor moderne Microsoft (stânga) și a interfeței noastre SeaMeet (dreapta).
În continuare, vă vom duce prin călătoria pe care am parcurs-o dincolo de întâlnirile moderne: aceasta depășește vocea, dar atinge inteligența vocală. Vă rugăm să citiți următorul blog din această serie.


