
Throughout this blog series, follow Seasalt.ai’s journey to creating a well rounded Modern Meetings Experience, starting with its humble beginnings, to optimizing our service on different hardware and models, to integrating state-of-the-art NLP systems and finally ending on the full realization of SeaMeet, our collaborative modern meeting solutions.
Beyond Algorithm
Modern Meetings was a fantastic demo, but somehow it stayed as a demo. There is still a long way to go to make it production-ready. We first successfully implemented the demo version with the Microsoft Azure stack. But recognizing all the pitfalls of the software, we decided to swap the algorithms out with our own, and also make the whole experience a lot smoother and lightweight with more flexibility. There are four major components of Modern Meetings, as illustrated below:
- Signal processing on the microphone array, most noticeably, beam forming
- Speaker diarization and identification
- Customized speech recognition
- A better UI
Next we will detail all the important components.

We adapted all 4 major components of Modern Meetings with our own tech stack: 1. Signal processing with the microphone array; 2. Speaker diarization and identification; 3. Customized speech recognition; 4. A modern web UI.
Signal Processing on the Microphone Array
The microphone array, when compared with a single close-talking microphone, picks up voices from a full 360 degree range, up to a distance of 5 meters. Thus a single microphone array is capable of voice collection in a medium-sized 10 meter by 10 meter conference room. Because all the microphones are clustered on a single device, it significantly reduces the amount of wires cluttering the conference room and simplifies the setup and maintenance. On the other hand, the downstream goal of using a microphone array is to give our models the best quality data possible. So before feeding the audio through automatic speech recognition, we first perform several signal processing algorithms. The main component of our preprocessing pipeline involves an algorithm known as beamforming. Because we are working with circular, multi microphone arrays, we are able to utilize the minute time difference that it takes for the sound to hit the various microphones. What beamforming does is determine the main characteristics of the signal — also known as the best beam — and accentuates these frequencies while attenuating the unwanted sounds. The effect is denoising and dereverberation while the main signal, in our case speech, becomes louder and clearer.
For optimal performance of many beamforming algorithms, we would need to know the exact position of the source (the speaker) relative to the microphone. But because in a real application this is impossible, we first calculate what are known as far field weights by determining the direction of the source. This first step, known as source localization, or more specifically Direction of Arrival (DOA), proved to be tricky. The main issue we faced was smoothing. The algorithm gave us approximately the correct result but the determined source would constantly fluctuate between 30 degrees on either side of the true direction which threw off beamforming. The solution we came up with was only letting the source localization algorithm use the range of frequencies that encode the bulk of human speech. We coupled this with a smoothing technique where we kept a “history” of DOA results to average over. With more reliable DOA results, we could then calculate the far field weights and use these to determine the best beam.
With the series of algorithms performed on the Kinect DK: beamforming, denoising, dereverberation, source localization, we were able to produce clear and enhanced human speech in real time while also pinpointing the approximate direction where the speaker is. This will greatly help speaker identification in the next step.
Speaker Diarization and Identification
The next component of a state-of-the-art meeting transcription system is automatic speaker recognition or identification. As stated in the last submission of this series, reading through an unorganized mess of conversational text with no information about who said what is frustrating and completely defeats the purpose of having such a system. This is where speaker recognition, also known as speaker identification, comes into play.
With this component we can automatically align the transcriptions and audio with the speaker’s name. In order to accomplish this, we use a process known as diarization that clusters audio segments into a given number of groups representing the number of speakers in that recording. This works by leveraging a Voice Activity Detection (VAD) system to determine speech segments, from which we can extract a vector representation of a short window. Each vector extracted from the windows is called an utterance-level xvector and when averaged we get a speaker-level x-vector. These x-vectors are then run through a clustering algorithm, where each cluster represents the speech segments that belong to the same speaker. It is worth mentioning that the choice of clustering algorithm greatly affects the diarization performance, and we’ve achieved optimal Diarization Error Rate (DER) with spectral clustering using a thresholded affinity matrix auto-tuned with Normalized Maximum Eigengap (NME) values. Finally, we need to decide which speaker represents each cluster. Prior to the meeting, we could perform an enrollment process to extract x-vectors from 40-second recordings of each speaker, which we can compare with the clusters to identify the corresponding speaker.
The beauty of this pipeline lies in its flexibility. For many meeting scenarios, it is impractical and often impossible to obtain recordings for each speaker in advance. Consider business meetings with VIP clients or large symposia with 50 speakers. In that case, skipping the step of enrollment, our diarization system can still sort out the speech segments and group up the ones belonging to the same speaker. All it takes is a human to sample a few seconds from each cluster to determine the speaker identity. Along with a dedicated modern user interface, we can provide the same functionality but with more flexibility.
Customized speech recognition
After getting to know Microsoft’s meeting transcriber and what makes it so powerful, we were ready to make our system fully independent and go beyond an already revolutionary product. The driving force behind Modern Meetings, and any transcription product, are the Automatic Speech Recognition (ASR) models. Thus naturally this earned most of our attention. Azure Cognitive Services offered a plethora of models to choose from across many languages and dialects. However, the performance between the different dialects was hard to distinguish. For the separate English dialects, it’s likely that most effort and data went into the US English model which was then fine-tuned on accented data to create the various dialect models. We wanted to make sure that if we offered a distinct model that it’s tuned to a specific use case. This meant sourcing thousands of hours of localized audio and transcriptions, and putting in weeks of training and finetuning. But it was worth the satisfaction of watching our models get better every epoch and delivering on what we promised.
Once we had a solid foundational model, the next step was expanding useability and customizability. Every industry comes with a host of its own jargon making it difficult for ASR models to decipher between esoteric vocabulary and a string of common, phonetically similar words.
Our response is SeaVoice, which provides a centralized location where users can easily tune models for their particular needs.
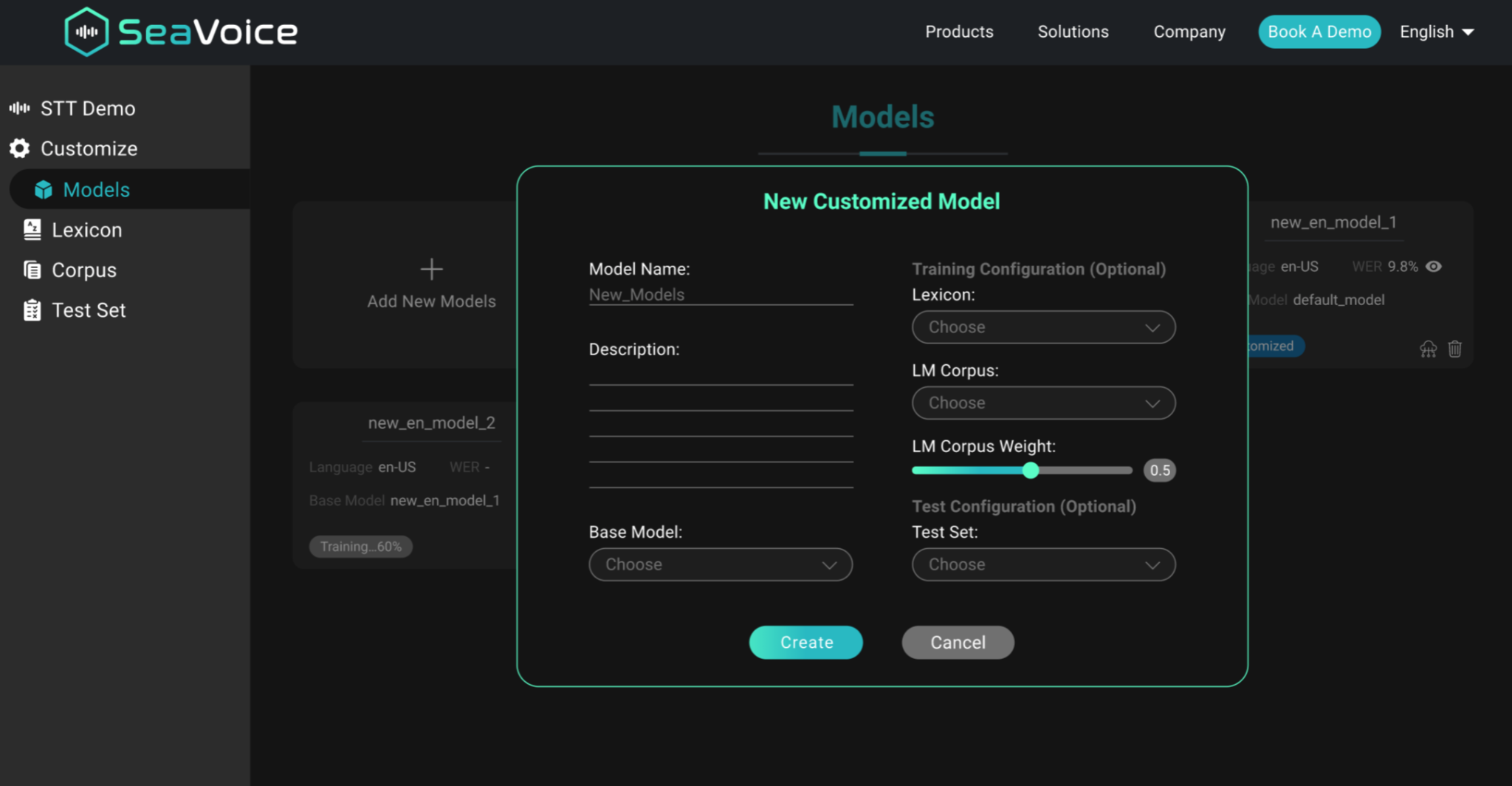
Seasalt.ai’s speech recognition product SeaVoice provides deep customization of speech models.
SeaVoice allows users to easily customize every component in an ASR pipeline: lexicon, language models, and acoustic models. Teaching the model new vocabulary is as simple as pairing the new words with a phonetic transcription.
With modern GPUs and CPUs, we were able to tune a speech model in a matter of minutes, and also provide real-time decoding so there was no lagging when recognizing incoming speech.
So far, we have swapped out all the internal core algorithms of Azure Speech Services with our in-house solution. This made the system extremely versatile and independent. Enterprise customers favor this also due to the capabilities of on-premise deployment to protect privacy. After working hard on the backend, we finally came to the point of improving the frontend user experience.
A Modern UI and SeaMeet is Born
There was just one piece left for us to finally complete our departure from Azure’s Speech Service: a fresh user interface that would be the definitive face of Modern Meetings. We set our sights beyond the merely functional design from Azure and the “clean” interface from the Microsoft Build 2019 showcase. This time we aimed for elegance and added value.

We first deliver real time transcriptions followed by additional offline processing to perform speaker diarization and identification. Finally, we walked the extra mile to draw insights from the meeting by extracting meeting topics, actions, minutes, and summaries . We will detail these insights in the next blog.
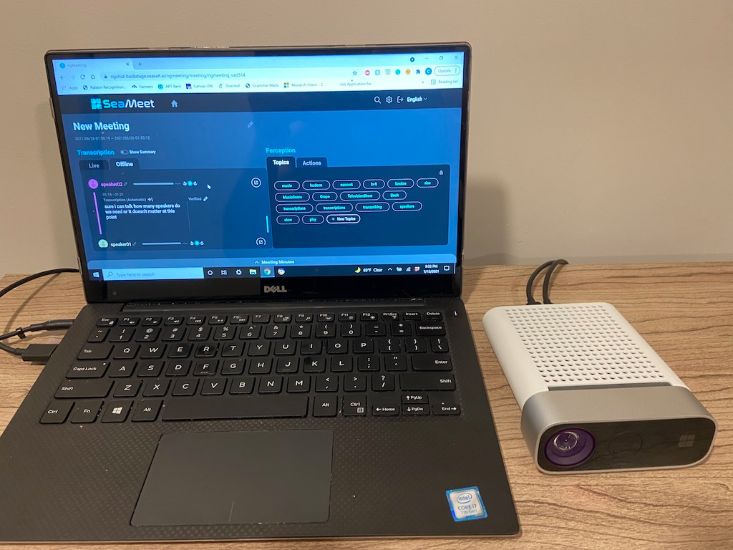
Finally, SeaMeet, a modern meeting re-implementation and enhancement of Microsoft Modern Meetings was born. The user interface is responsive and informative, providing much more value than the original proposition.
 |
 |
|---|
A side-by-side comparison of Microsoft’s original Modern Meetings implementation (left) and our own SeaMeet interface (right).
Next, we will take you through the journey that we went beyond Modern Meetings: this goes beyond voice but touches voice intelligence. Please go ahead to read the next blog in this series.
 Subscribe
Subscribe