





Setelah meluncurkan SeaVoice, salah satu bot text-to-speech dan speech-to-text tercepat dan paling akurat di Discord, kami ingin memahami bagaimana pengguna sebenarnya berinteraksi dengan layanan tersebut. Dalam blog ini kami akan membahas temuan kami setelah meninjau data pengguna speech-to-text nyata selama beberapa minggu.
SeaVoice: Bot Discord Text-to-Speech & Speech-to-Text
Discord, sebagai platform yang terutama digunakan untuk kombinasi obrolan berbasis audio dan teks, adalah tempat pengujian yang fantastis untuk layanan kecerdasan suara dan pemrosesan bahasa alami. Kami menerapkan Bot SeaVoice, yang dilengkapi dengan perintah text-to-speech dan speech-to-text, ke Discord pada Agustus 2022. Untuk mempelajari lebih lanjut tentang cara kerja bot, atau melihat demo video singkat, Anda dapat mengunjungi wiki Bot SeaVoice. Pada bulan November di tahun yang sama, kami merilis versi baru dengan peningkatan backend yang signifikan (seperti yang dijelaskan dalam posting blog kami: Bot Discord SeaVoice: Peningkatan Backend & Stabilitas) yang memungkinkan kami merekam data anonim tentang bagaimana pengguna berinteraksi dengan bot SeaVoice. Di blog terakhir kami (Studi Kasus Bot Discord TTS) kami menganalisis data pengguna selama 1 bulan dari perintah text-to-speech. Sebagai tindak lanjut, dalam posting ini kami akan melihat data pengguna speech-to-text selama sekitar 3 minggu.
Penggunaan STT SeaVoice
Pada saat penulisan, Bot SeaVoice telah ditambahkan ke hampir 900 server! Sekitar 260 server dengan total lebih dari 600 peserta telah mencoba perintah STT setidaknya sekali. Dalam 3 minggu terakhir kami telah menyelenggarakan hampir 1.800 sesi STT dan menghasilkan total lebih dari setengah juta baris transkripsi.
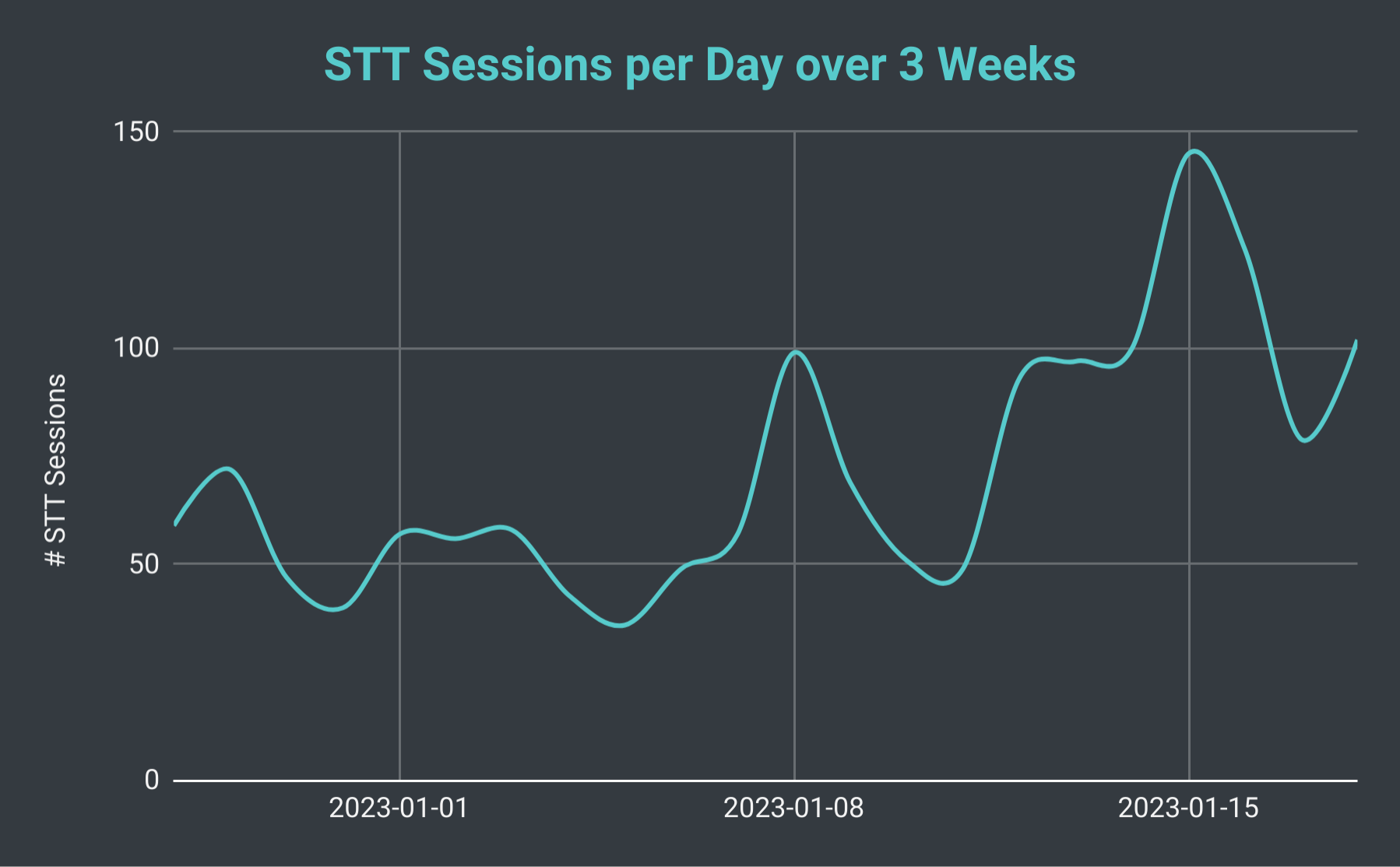
Sesi ucapan-ke-teks harian Bot Discord SeaVoice selama 3 minggu.
Jika kita melihat jumlah total sesi STT per hari, kami menemukan bahwa itu dapat berfluktuasi dari sedikitnya 40 hingga lebih dari 140 (dengan rata-rata sekitar 70). Kita juga dapat mempertimbangkan jumlah total baris transkripsi yang kami hasilkan. Pada hari paling lambat, kami menghasilkan sedikitnya 10 ribu baris, namun, pada hari yang sibuk kami telah menghasilkan lebih dari 40 ribu baris. Untuk memberikan perspektif, pada tanggal 18 Januari, kami menyelenggarakan 102 sesi STT dengan total kurang dari 30 ribu baris transkripsi; itu setara dengan hampir 40 jam waktu perekaman.
Kami juga menemukan bahwa meskipun sebagian besar sesi digunakan untuk percakapan yang lebih pendek (median 57 baris per sesi), ada sejumlah besar sesi yang sangat panjang yang menaikkan rata-rata menjadi 650 baris per sesi. Sesi terpanjang kami lebih dari 30 ribu baris, lebih dari rata-rata satu hari! Terakhir kami juga melihat berapa banyak pengguna yang cenderung berada di setiap sesi dan menemukan bahwa biasanya ada 4 hingga 5 pengguna di setiap sesi - namun kami pernah menggunakan bot untuk mendukung transkripsi langsung di seminar virtual yang memiliki 45 peserta!
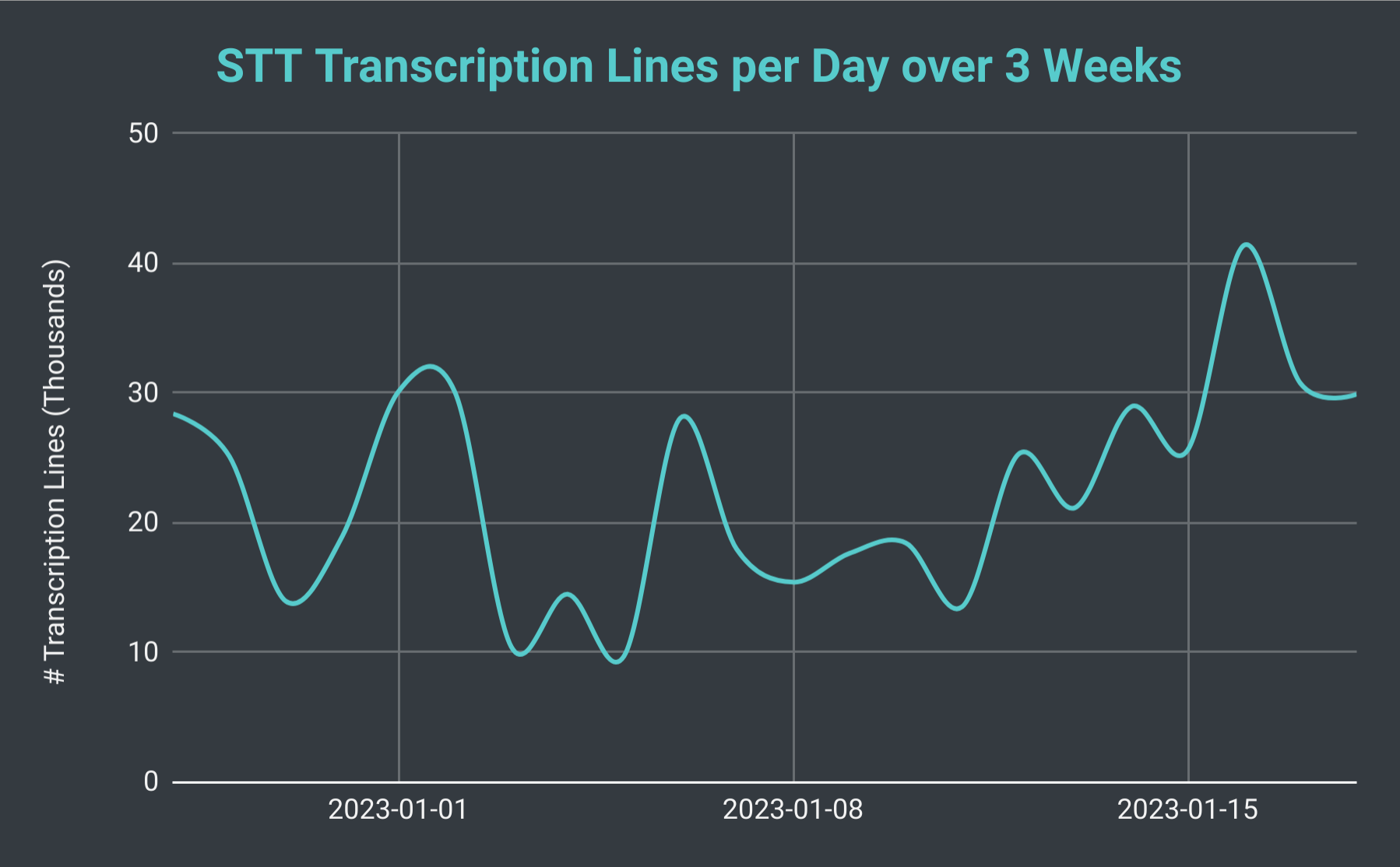
Baris yang ditranskripsikan Bot Discord SeaVoice per hari selama 3 minggu.
Sementara sebagian besar server belum menggunakan sesi STT lebih dari beberapa kali, ada beberapa yang menggunakan layanan ini secara ekstensif. Sejak kami mulai merekam data penggunaan STT pada akhir Desember, jumlah total rata-rata sesi per server adalah sekitar 7; namun, server #1 kami telah mencatat 131 sesi - Itu rata-rata lebih dari 6 sesi per hari! Server yang sama telah mentranskripsikan lebih dari 150 ribu baris ucapan hanya dalam 3 minggu! Mungkin yang lebih mengesankan dari itu, pengguna #1 kami berasal dari server yang sama dan telah mentranskripsikan lebih dari 60 ribu baris ucapannya sendiri!
Pengamatan
Mengapa Orang Menggunakan Ucapan-ke-Teks

Seorang pengguna bot Discord SeaVoice mengungkapkan kegembiraan tentang file audio dan transkripsi yang disimpan.
Jadi pertanyaan pertama kami setelah melihat data penggunaan adalah: mengapa pengguna yang sering menggunakan ucapan-ke-teks sejak awal?
Kami melihat melalui database untuk menemukan beberapa penjelasan. Namun, ternyata lebih sulit untuk menemukan penjelasan konkret mengapa pengguna menggunakan layanan STT dibandingkan dengan layanan TTS. Tampaknya orang merasa perlu menjelaskan kepada orang lain di obrolan mengapa mereka menggunakan TTS, tetapi tidak begitu dengan STT. Meskipun demikian, saya menemukan beberapa transkripsi menarik yang memberikan beberapa wawasan tentang mengapa pengguna memutuskan untuk menggunakan layanan STT.
Mengapa pengguna menggunakan STT:
- “Inilah mengapa transkrip digunakan karena saya dapat melihat hal-hal yang saya lewatkan.”
- “[pengguna] sulit mendengar, jadi dia mendapatkan bot yang mentranskripsikannya”
- “[pengguna] melakukan raid dengan mereka dan mereka menggunakannya untuk mentranskripsikan barang, tetapi kemudian [pengguna] seperti, oh, kita juga bisa menggunakannya untuk ******* D dan D, juga”
- “Saya tidak sabar untuk kembali dan membaca beberapa transkrip ini nanti […] Saya ingin mendengarkan rekaman itu dan melihat transkrip itu lagi”
- “Jika kita mengadakan pertemuan di sini, maka kita dapat memasukkan transkrip pertemuan ke dalam AI”
- “Selama pertemuan dengan orang-orang, sangat bagus untuk benar-benar melihat transkrip”
- “[orang-orang] yang tidak ada di obrolan atau orang-orang yang ada di komunitas, tetapi bukan bagian dari obrolan suara, tetapi mereka memutuskan untuk melihat dan membaca”
Jadi secara umum, tampaknya sebagian besar pengguna menikmati kemudahan memiliki transkripsi langsung yang dapat membantu mereka melacak percakapan dan mengisi celah yang mereka lewatkan. Ini terutama berlaku untuk pengguna yang memiliki gangguan pendengaran atau kesulitan audio/koneksi. Bagi sebagian pengguna, keuntungan terbesar adalah menyimpan rekaman audio dan teks permanen dari percakapan mereka; ini bisa sangat berlaku untuk kasus penggunaan seperti memelihara log sesi Dungeons & Dragons atau menyimpan catatan pertemuan penting.
Karena banyak pengguna tidak secara eksplisit mengatakan mengapa mereka menggunakan layanan STT, tampaknya juga berguna untuk mendapatkan gambaran tentang apa yang mereka lakukan saat menggunakan bot. Meninjau transkripsi dari pengguna memberi saya petunjuk tentang aktivitas apa yang mereka lakukan saat mentranskripsikan:
Apa yang dilakukan pengguna saat menggunakan STT:
- Hanya mengobrol
- Bermain game:
- Bermain game kasual
- Bermain game tingkat lanjut (misalnya/ mengoordinasikan grup MMO, Massive Multiplayer Online, raid)
- Permainan peran (Dungeons & Dragons)
- Streaming / merekam konten
- Membahas pekerjaan sekolah / profesional / sukarela
Sebagian besar transkripsi termasuk dalam kategori “hanya mengobrol” dan “bermain game kasual”. Seperti yang kita lihat di atas, saya pikir sebagian besar pengguna dalam kasus ini menggunakan bot untuk meningkatkan aksesibilitas saluran suara Discord dan/atau menikmati kemudahan melihat transkripsi langsung untuk mengisi celah yang mereka lewatkan dalam percakapan. Dalam beberapa kasus (seperti saat digunakan untuk raid MMO), diskusi game sangat kompleks dan pengguna berkoordinasi satu sama lain secara real-time; transkripsi langsung dapat terbukti sangat berguna bagi keberhasilan tim karena pengguna dapat merujuk transkrip saat mereka bermain.
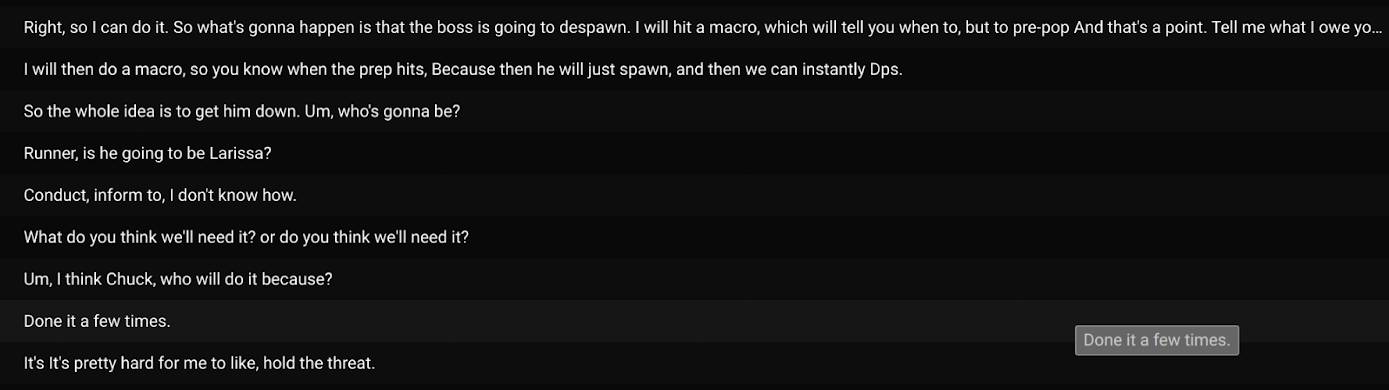
Contoh diskusi kompleks selama raid MMO.
Sepertinya juga banyak pengguna yang menggunakan bot untuk mentranskripsikan percakapan yang lebih serius seperti pertemuan sekolah, profesional, dan/atau komunitas sukarelawan. Kami juga meminta bot kami digunakan untuk mentranskripsikan konferensi teknologi online, UnTechCon. Dalam kasus ini, file rekaman dan transkripsi akhir mungkin terbukti sangat membantu pengguna untuk ditinjau setelah pertemuan. Satu contoh menarik terakhir yang saya temukan adalah pengguna yang merekam konten untuk streaming mereka. Karena transkrip akhir dilengkapi dengan stempel waktu, pengguna berpotensi mengunggah file transkrip sebagai subtitle untuk konten audio atau video yang direkam.
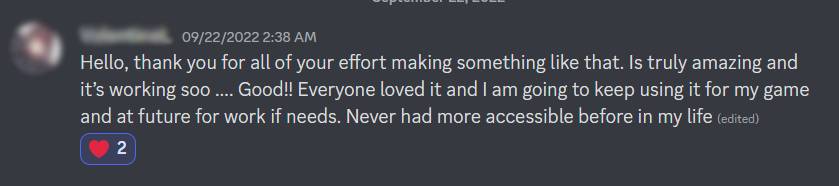
Seorang pengguna SeaVoice mengucapkan terima kasih karena membuat saluran suara Discord lebih mudah diakses.
Tetapi terlepas dari alasan pastinya mereka menggunakan layanan STT, banyak pengguna yang mengungkapkan kegembiraan karena mereka dapat berpartisipasi dalam percakapan saluran suara padahal sebaliknya mereka tidak akan bisa. Kami percaya bahwa layanan STT membuat saluran suara Discord lebih mudah diakses, dan itulah alasan utama pengguna reguler kami terus menggunakan layanan ini.
Komentar tentang Bot Discord SeaVoice
Topik menarik lainnya yang ditemukan di log adalah komentar tentang bot itu sendiri. Syukurlah, kami melihat beberapa komentar yang sangat positif tentang bot dan kinerjanya.

Seorang pengguna SeaVoice mengomentari akurasi transkripsi.
Kami juga menemukan beberapa umpan balik yang membangun.

Seorang pengguna SeaVoice menyarankan perbaikan untuk aksen Inggris.

Seorang pengguna membandingkan kinerja SeaVoice pada bahasa Inggris beraksen dengan Siri.
Sebagian besar komentar yang membangun berkaitan dengan bot yang tidak berkinerja baik pada bahasa Inggris beraksen non-Amerika; khususnya pengguna menyebutkan aksen Inggris dan Skotlandia. Untuk masa depan layanan STT kami, kami dapat berupaya keras untuk meningkatkan pengenalan ucapan kami untuk berbagai aksen bahasa Inggris. Tentu saja, bahasa Inggris bukan satu-satunya bahasa yang digunakan pengguna kami, jadi kami juga berencana untuk menambahkan lebih banyak dukungan bahasa ke bot. Faktanya, saat ini kami sedang menyelesaikan integrasi STT dan TTS Mandarin Taiwan kami, dan akan segera merilis versi bot yang diperbarui.
Privasi, Sensitivitas Data, & Konten yang Berpotensi Menyinggung
Pengembangan AI dikelilingi oleh serentetan dilema etis. Model kami membutuhkan sejumlah besar data pengguna nyata untuk berkinerja baik, tetapi bagaimana kami mengumpulkan data itu secara etis sambil menghormati privasi pengguna kami? Model hanya belajar berdasarkan data yang diberikan dan oleh karena itu memiliki bias (yang berpotensi tidak terduga); jadi bagaimana kami dapat memastikan model kami melayani semua pengguna kami dengan sama baiknya? Selain itu, model kami tidak memiliki konsep penerimaan sosial dan dapat menghasilkan hasil yang menurut sebagian pengguna menyinggung. Seperti yang dikatakan salah satu pengguna kami dengan sangat fasih: “Apakah itu rasis jika bot yang melakukannya, itulah pertanyaannya”.

Seorang pengguna SeaVoice menunjukkan transkripsi yang tidak akurat dan bermasalah.
Alasan saya mengangkat poin-poin ini adalah karena beberapa transkripsi yang mengkhawatirkan di log. Masalah pertama adalah bot sesekali mentranskripsikan konten yang menyinggung. Dalam contoh di atas, bot secara tidak sengaja mentranskripsikan nama pengguna seseorang sebagai cercaan rasial. Jelas ini adalah kesalahan di pihak bot yang mungkin menyinggung pengguna kami dan harus diselidiki. Tetapi ini menimbulkan lebih banyak pertanyaan: di mana kita menarik garis antara pelanggaran dan kerugian?

Seorang pengguna SeaVoice mengomentari upaya menyensor kata-kata tertentu dari transkripsi.
Nah, untuk memulai kami telah memutuskan untuk memberikan kekuatan itu kepada pengguna. Salah satu fitur berikutnya yang akan kami kerjakan adalah penyensoran TTS dan STT yang dapat dikonfigurasi. Ini akan memungkinkan server untuk secara opsional menerapkan sensor untuk kata-kata umpatan, konten seksual, cercaan rasial, dll.

Seorang pengguna SeaVoice memperingatkan peserta lain untuk sadar bahwa apa yang mereka katakan akan berakhir di transkrip.
Menariknya, masalah terkait lainnya yang kami lihat adalah pengguna yang menyensor diri sendiri untuk menghindari hal-hal tertentu muncul di transkrip. Ini ternyata sangat umum, dan saya melihat banyak kasus di mana pengguna menjelaskan bahwa mereka tidak ingin bot mentranskripsikan apa yang akan mereka katakan sehingga mereka berhenti dan kemudian memulai ulang STT. Ini adalah kekhawatiran yang sepenuhnya valid di pihak pengguna jika misalnya mereka tidak ingin bot mentranskripsikan beberapa informasi sensitif.
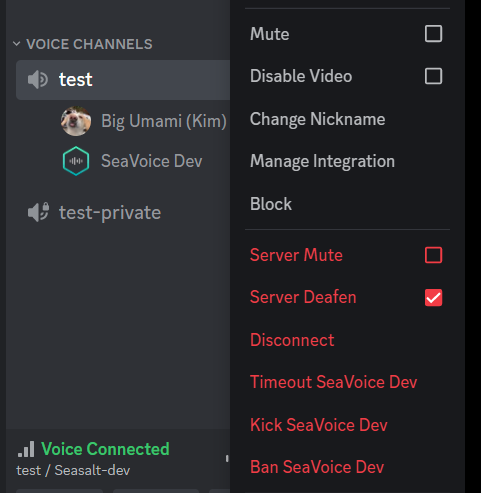
Cara menjeda STT dengan menulikan bot.
Saya tidak yakin ada cara kami dapat meningkatkan pengalaman pengguna dalam kasus ini, tetapi saya akan menyarankan pengguna bahwa mereka dapat “menulikan” bot untuk sementara waktu untuk berhenti mengirim audio apa pun ke bot. Dalam hal ini, bot akan menerima nol data audio sampai tidak ditulikan, sehingga pengguna pada dasarnya dapat menjeda sesi STT tanpa menghentikan dan memulai yang baru.

Seorang pengguna SeaVoice mengomentari ketidaknyamanan peserta lain dengan bot.
Terakhir, masalah terakhir yang kami lihat adalah beberapa pengguna merasa sangat tidak nyaman dengan bot yang mentranskripsikan sehingga mereka secara aktif menghindari berbicara di saluran suara saat bot ada. Ini adalah **kebalikan total__ dari tujuan kami, yaitu membuat saluran suara Discord lebih mudah diakses oleh semua orang. Meskipun kami berharap pengguna akan menerima kebijakan privasi kami dan mempercayai kami untuk menggunakan data mereka secara bertanggung jawab, kami benar-benar menghormati hak setiap orang atas privasi. Dengan demikian, fitur berikutnya yang akan kami terapkan adalah pengaturan opt-out STT. Ini akan memungkinkan setiap pengguna untuk mengecualikan diri dari rekaman dan transkripsi STT, dan data audio mereka tidak akan diakses atau dikumpulkan dengan cara apa pun oleh bot.
Kami berharap fitur-fitur yang direncanakan ini akan memungkinkan kami untuk terus membuat saluran suara lebih mudah diakses oleh semua orang sambil memberi pengguna agensi untuk berinteraksi dengan Bot SeaVoice pada tingkat yang mereka rasa nyaman. Ke depan kami akan terus berupaya untuk secara proaktif mengatasi masalah-masalah yang menantang ini untuk membuat SeaVoice menjadi yang terbaik!
Terima kasih atas minat Anda pada Bot Discord kami dan terima kasih kepada pengguna kami atas dukungan Anda yang berkelanjutan! Anda dapat mempelajari lebih lanjut tentang produk STT kami di Halaman Beranda Ucapan-ke-Teks SeaVoice kami. Untuk demo satu lawan satu dari salah satu produk Kecerdasan Suara kami, isi Formulir Pesan Demo.
Jika Anda belum mencoba bot SeaVoice, Anda dapat mempelajari lebih lanjut tentang bot kami dan menambahkannya ke server Anda dari Wiki Bot Discord SeaVoice. Jangan ragu juga untuk bergabung dengan Server Discord SeaVoice Resmi kami.


