





Selepas melancarkan SeaVoice, salah satu bot teks-ke-ucapan dan ucapan-ke-teks terpantas dan paling tepat di Discord, kami ingin memahami bagaimana pengguna sebenarnya berinteraksi dengan perkhidmatan tersebut. Dalam blog ini kami akan membincangkan penemuan kami selepas mengkaji beberapa minggu data pengguna suara ke teks sebenar.
SeaVoice: Bot Discord Teks-ke-Ucapan & Ucapan-ke-Teks
Discord, sebagai platform yang digunakan terutamanya untuk gabungan sembang berasaskan audio dan teks, adalah medan ujian yang hebat untuk perkhidmatan kecerdasan suara dan pemprosesan bahasa semula jadi. Kami menggunakan Bot SeaVoice, yang dilengkapi dengan arahan teks-ke-ucapan dan ucapan-ke-teks, ke Discord pada Ogos 2022. Untuk mengetahui lebih lanjut tentang cara bot berfungsi, atau melihat demo video pendek, anda boleh melawat wiki Bot SeaVoice. Pada November tahun yang sama, kami mengeluarkan versi baharu dengan penambahbaikan backend yang ketara (seperti yang diterangkan dalam catatan blog kami: Bot Discord SeaVoice: Penambahbaikan Backend & Kestabilan) yang membolehkan kami merekod data tanpa nama tentang cara pengguna berinteraksi dengan bot SeaVoice. Dalam blog terakhir kami (Kajian Kes Bot Discord TTS) kami menganalisis data pengguna selama 1 bulan daripada arahan teks-ke-ucapan. Sebagai susulan, dalam catatan ini kami akan melihat data pengguna suara ke teks selama kira-kira 3 minggu.
Penggunaan STT SeaVoice
Pada masa penulisan, Bot SeaVoice telah ditambahkan ke hampir 900 pelayan! Kira-kira 260 pelayan dengan jumlah lebih 600 peserta sebenarnya telah mencuba arahan STT sekurang-kurangnya sekali. Dalam 3 minggu yang lalu kami telah menganjurkan hampir 1,800 sesi STT dan mengeluarkan sejumlah lebih setengah juta baris transkripsi.
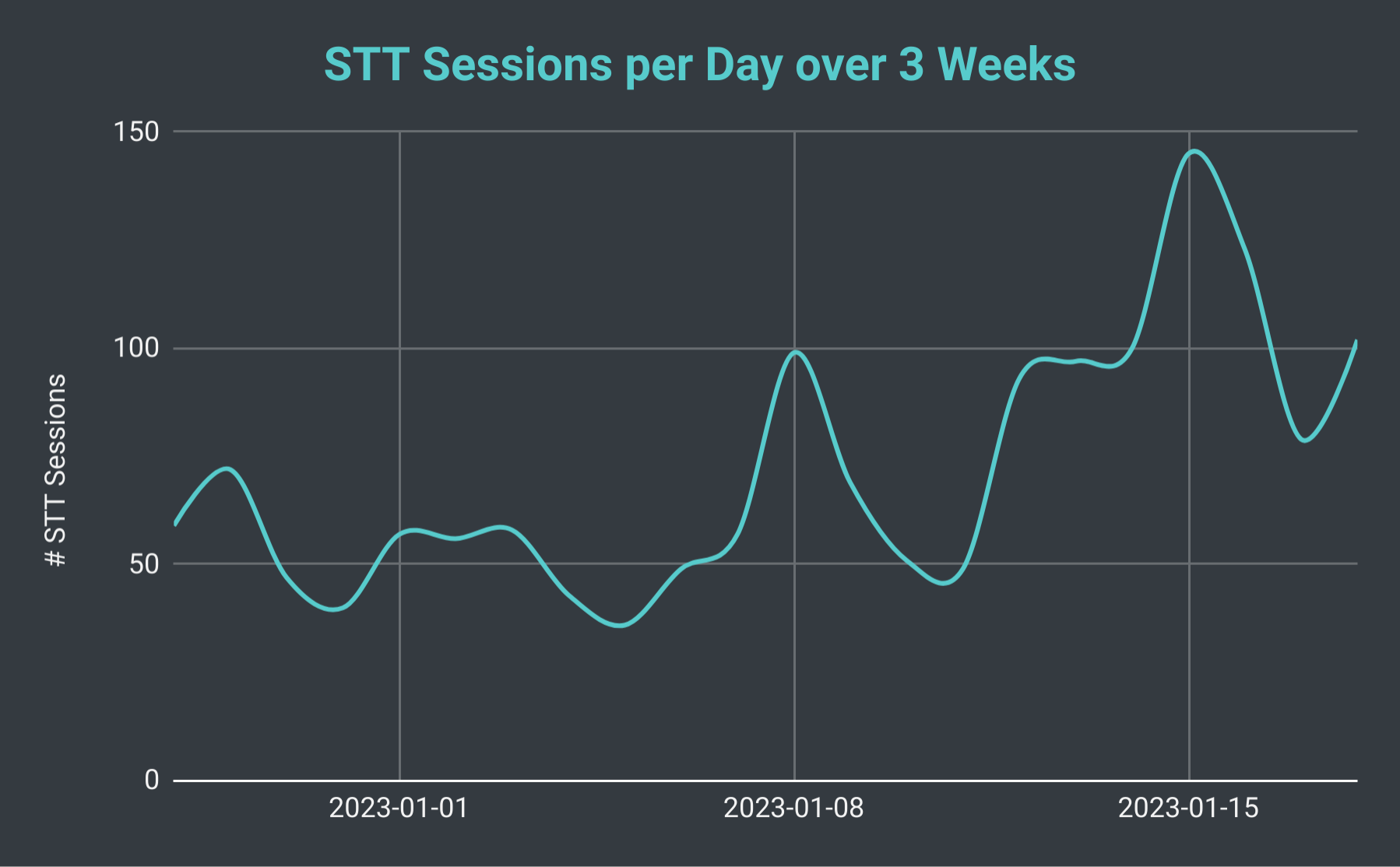
Sesi suara ke teks harian Bot Discord SeaVoice selama 3 minggu.
Jika kita melihat jumlah keseluruhan sesi STT setiap hari, kita dapati bahawa ia boleh berubah-ubah dari serendah 40 hingga lebih 140 (dengan purata kira-kira 70). Kita juga boleh mempertimbangkan jumlah keseluruhan baris transkripsi yang kita hasilkan. Pada hari yang paling perlahan, kita menghasilkan serendah 10 ribu baris, namun, pada hari yang sibuk kita telah menghasilkan lebih daripada 40 ribu baris. Untuk meletakkannya dalam perspektif, pada 18 Januari, kita menganjurkan 102 sesi STT dengan jumlah kurang daripada 30 ribu baris transkripsi; itu berjumlah hampir 40 jam masa rakaman.
Kami juga mendapati bahawa walaupun kebanyakan sesi digunakan untuk perbualan yang lebih pendek (median 57 baris setiap sesi), terdapat sejumlah besar sesi yang sangat panjang yang menaikkan purata kepada 650 baris setiap sesi. Sesi terpanjang kami adalah lebih 30 ribu baris, lebih daripada nilai purata sehari! Akhirnya kami juga melihat berapa ramai pengguna yang cenderung berada dalam setiap sesi dan mendapati bahawa biasanya terdapat 4 hingga 5 pengguna dalam setiap sesi - namun kami pernah menggunakan bot untuk menyokong transkripsi langsung di seminar maya yang mempunyai 45 peserta!
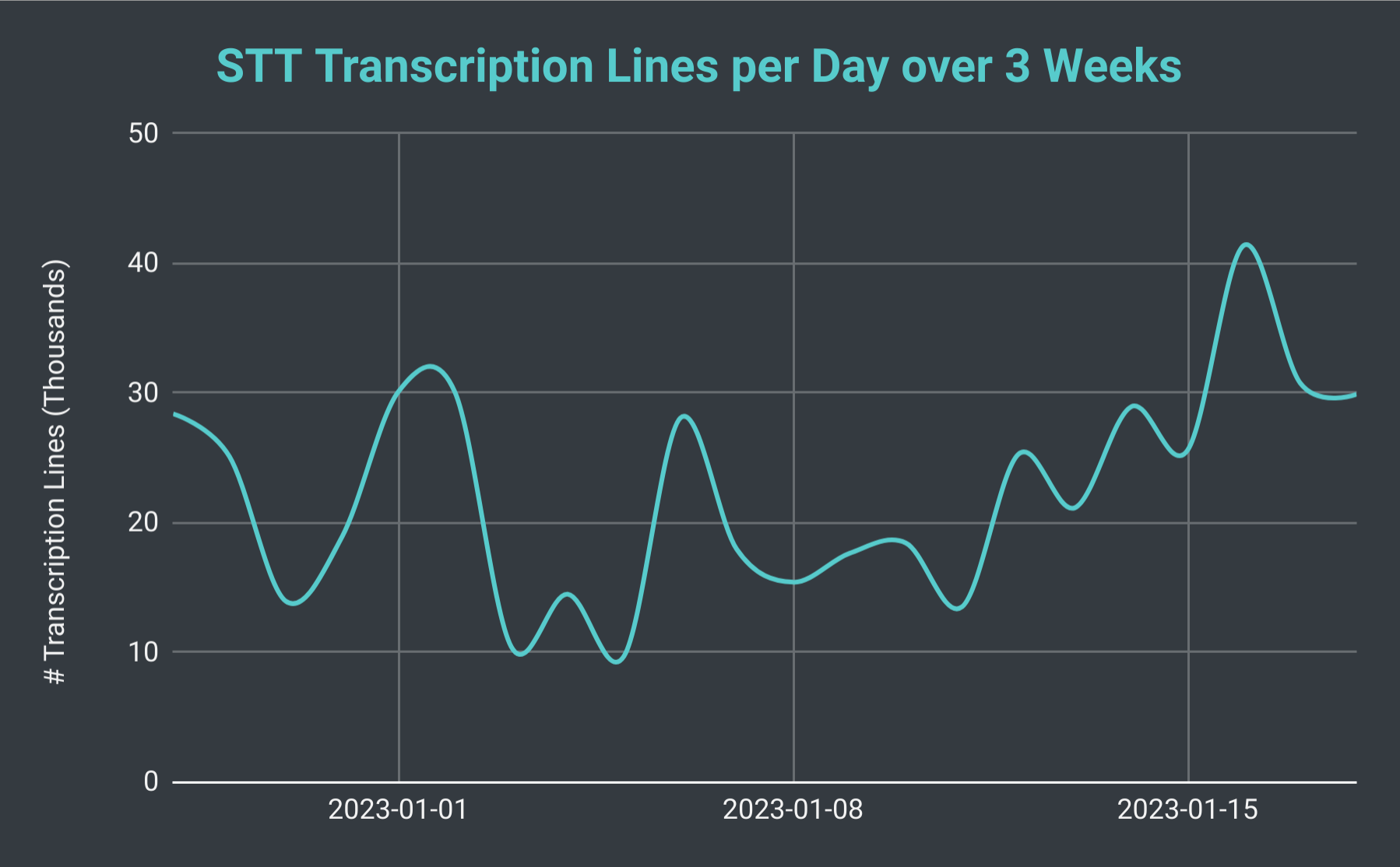
Baris yang ditranskripsi oleh Bot Discord SeaVoice setiap hari selama 3 minggu.
Walaupun majoriti pelayan tidak menggunakan sesi STT lebih daripada beberapa kali, terdapat beberapa yang menggunakan perkhidmatan ini secara meluas. Sejak kami mula merekodkan data penggunaan STT pada akhir Disember, purata jumlah sesi setiap pelayan adalah kira-kira 7; namun, pelayan #1 kami telah mencatatkan 131 sesi - Itu purata lebih 6 sesi sehari! Pelayan yang sama telah mentranskripsikan lebih 150 ribu baris ucapan dalam masa 3 minggu sahaja! Mungkin yang lebih mengagumkan daripada itu, pengguna #1 kami berasal dari pelayan yang sama dan telah mentranskripsikan lebih 60 ribu baris ucapan mereka sendiri!
Pemerhatian
Mengapa Orang Menggunakan Suara ke Teks

Seorang pengguna bot Discord SeaVoice menyatakan kegembiraan tentang fail audio dan transkripsi yang berterusan.
Jadi soalan pertama kami selepas melihat data penggunaan ialah: mengapa pengguna yang kerap menggunakan suara ke teks pada mulanya?
Kami melihat melalui pangkalan data untuk mencari beberapa penjelasan. Walau bagaimanapun, ternyata lebih sukar untuk mencari penjelasan konkrit mengapa pengguna menggunakan perkhidmatan STT berbanding perkhidmatan TTS. Nampaknya orang ramai merasakan keperluan untuk menjelaskan kepada orang lain dalam sembang mengapa mereka menggunakan TTS, tetapi kurang begitu dengan STT. Walau bagaimanapun, saya menemui beberapa transkripsi menarik yang memberikan sedikit gambaran tentang mengapa pengguna memutuskan untuk menggunakan perkhidmatan STT.
Mengapa pengguna menggunakan STT:
- “Inilah sebabnya mengapa transkripsi digunakan kerana saya boleh melihat perkara yang saya terlepas.”
- “[pengguna] sukar mendengar, jadi dia mendapat bot yang mentranskripsikannya”
- “[pengguna] menyerbu dengan mereka dan mereka menggunakannya untuk mentranskripsi barang, tetapi kemudian [pengguna] berkata, oh, kita juga boleh menggunakannya untuk ******* D dan D”
- “Saya tidak sabar untuk kembali dan membaca beberapa transkripsi ini kemudian […] Saya ingin mendengar rakaman itu dan melihat transkripsi itu lagi”
- “Jika kita mengadakan mesyuarat di sini, maka kita boleh memasukkan transkripsi mesyuarat ke dalam AI”
- “Semasa mesyuarat dengan orang ramai, sangat bagus untuk benar-benar melihat transkripsi”
- “[orang] yang tidak berada dalam sembang atau orang yang berada dalam komuniti, tetapi bukan sebahagian daripada sembang suara, tetapi mereka memutuskan untuk melihat dan membaca”
Jadi secara umum, nampaknya kebanyakan pengguna menikmati kemudahan mempunyai transkripsi langsung yang boleh membantu mereka menjejaki perbualan dan mengisi sebarang jurang yang mereka terlepas. Ini terutamanya berlaku untuk pengguna yang mempunyai masalah pendengaran atau masalah audio/sambungan. Bagi sesetengah pengguna, faedah terbesar adalah menyimpan rekod audio dan teks kekal perbualan mereka; ini boleh digunakan terutamanya untuk kes penggunaan seperti mengekalkan log sesi Dungeons & Dragons atau menyimpan rekod mesyuarat penting.
Oleh kerana ramai pengguna tidak menyatakan secara eksplisit mengapa mereka menggunakan perkhidmatan STT, ia juga kelihatan berguna untuk mendapatkan gambaran tentang apa yang mereka lakukan semasa menggunakan bot. Mengkaji transkripsi daripada pengguna memberi saya petunjuk tentang aktiviti yang mereka lakukan semasa mentranskripsi:
Apa yang pengguna lakukan semasa menggunakan STT:
- Hanya berbual
- Permainan:
- Permainan kasual
- Permainan lanjutan (cth/ menyelaraskan kumpulan MMO, Massive Multiplayer Online, serbuan)
- Permainan main peranan (Dungeons & Dragons)
- Penstriman / merakam kandungan
- Membincangkan kerja sekolah / profesional / sukarela
Sebahagian besar transkripsi termasuk dalam kategori “hanya berbual” dan “permainan kasual”. Seperti yang kita lihat di atas, saya fikir kebanyakan pengguna dalam kes ini menggunakan bot untuk meningkatkan kebolehcapaian saluran suara Discord dan/atau menikmati kemudahan melihat transkripsi langsung untuk mengisi sebarang jurang yang mereka terlepas dalam perbualan. Dalam beberapa kes (seperti apabila digunakan untuk serbuan MMO), perbincangan permainan sangat kompleks dan pengguna menyelaraskan antara satu sama lain dalam masa nyata; transkripsi langsung boleh terbukti sangat berguna untuk kejayaan pasukan kerana pengguna boleh merujuk transkripsi semasa mereka bermain.
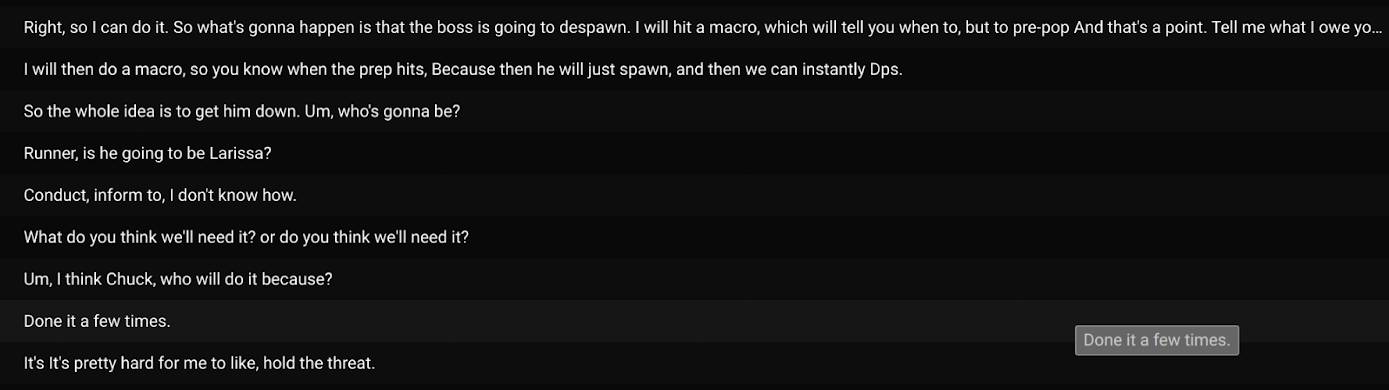
Contoh perbincangan kompleks semasa serbuan MMO.
Nampaknya ramai pengguna juga menggunakan bot untuk mentranskripsikan perbualan yang lebih serius seperti mesyuarat sekolah, profesional dan/atau komuniti sukarelawan. Kami juga menggunakan bot kami untuk mentranskripsikan persidangan teknologi dalam talian, UnTechCon. Dalam kes ini, fail rakaman dan transkripsi akhir mungkin terbukti sangat membantu pengguna untuk semakan selepas mesyuarat. Satu contoh menarik terakhir yang saya temui ialah pengguna merakam kandungan untuk strim mereka. Oleh kerana transkripsi akhir datang dengan cap masa, pengguna berpotensi memuat naik fail transkripsi sebagai sari kata untuk kandungan audio atau video yang dirakam mereka.
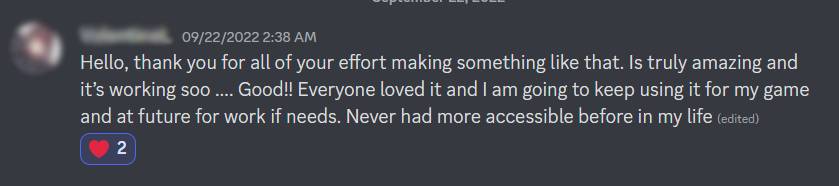
Seorang pengguna SeaVoice mengucapkan terima kasih kerana menjadikan saluran suara Discord lebih mudah diakses.
Tetapi tanpa mengira sebab sebenar mereka menggunakan perkhidmatan STT, ramai pengguna menyatakan kegembiraan bahawa mereka dapat mengambil bahagian dalam perbualan saluran suara sedangkan mereka tidak dapat melakukannya. Kami percaya bahawa perkhidmatan STT menjadikan saluran suara Discord lebih mudah diakses, dan itulah sebab utama pengguna biasa kami terus menggunakan perkhidmatan tersebut.
Ulasan tentang Bot Discord SeaVoice
Satu lagi topik menarik yang ditemui dalam log ialah ulasan tentang bot itu sendiri. Syukurlah, kami melihat beberapa komen yang sangat positif tentang bot dan prestasinya.

Seorang pengguna SeaVoice mengulas tentang ketepatan transkripsi.
Kami juga menemui beberapa maklum balas yang membina.

Seorang pengguna SeaVoice mencadangkan penambahbaikan untuk aksen British.

Seorang pengguna membandingkan prestasi SeaVoice pada bahasa Inggeris beraksen dengan Siri.
Kebanyakan komen yang membina berkaitan dengan bot yang tidak berprestasi baik pada bahasa Inggeris beraksen bukan Amerika; khususnya pengguna menyebut aksen British dan Scotland. Untuk masa depan perkhidmatan STT kami, kami boleh berusaha keras untuk meningkatkan pengecaman pertuturan kami untuk pelbagai aksen bahasa Inggeris. Sudah tentu, bahasa Inggeris bukan satu-satunya bahasa yang dituturkan oleh pengguna kami, jadi kami juga merancang untuk menambah lebih banyak sokongan bahasa kepada bot. Malah, kami sedang memuktamadkan integrasi STT dan TTS Mandarin Taiwan kami, dan akan mengeluarkan versi bot yang dikemas kini tidak lama lagi.
Privasi, Sensitiviti Data, & Kandungan yang Berpotensi Menyinggung
Perkembangan AI dikelilingi oleh pelbagai dilema etika. Model kami memerlukan sejumlah besar data pengguna sebenar untuk berfungsi dengan baik, tetapi bagaimana kami mengumpul data itu secara etika sambil menghormati privasi pengguna kami? Model hanya belajar berdasarkan data yang diberikan kepada mereka dan oleh itu mempunyai bias (yang berpotensi tidak dijangka); jadi bagaimana kami dapat memastikan model kami melayani semua pengguna kami dengan sama baiknya? Selain itu, model kami tidak mempunyai konsep penerimaan sosial dan boleh menghasilkan keputusan yang sesetengah pengguna mendapati menyinggung. Seperti yang dikatakan oleh salah seorang pengguna kami dengan begitu fasih: “Adakah ia rasis jika bot yang melakukannya, itulah persoalannya”.

Seorang pengguna SeaVoice menunjukkan transkripsi yang tidak tepat yang bermasalah.
Sebab saya membangkitkan perkara ini adalah kerana beberapa transkripsi yang membimbangkan dalam log. Isu pertama ialah bot kadang-kadang mentranskripsikan kandungan yang menyinggung. Dalam contoh di atas, bot secara tidak sengaja mentranskripsikan nama pengguna seseorang sebagai cercaan kaum. Jelas sekali ini adalah kesilapan di pihak bot yang mungkin menyinggung pengguna kami dan harus disiasat. Tetapi ini membawa kepada lebih banyak soalan: di mana kita menarik garis antara kesalahan dan bahaya?

Seorang pengguna SeaVoice mengulas tentang percubaan untuk menapis perkataan tertentu daripada transkripsi.
Baiklah, untuk bermula kami telah memutuskan untuk memberikan kuasa itu kepada pengguna. Salah satu ciri seterusnya yang akan kami usahakan ialah penapisan TTS dan STT yang boleh dikonfigurasi. Ini akan membolehkan pelayan secara pilihan menggunakan penapis untuk kata-kata kesat, kandungan seksual, cercaan kaum, dsb.

Seorang pengguna SeaVoice memberi amaran kepada peserta lain agar berhati-hati bahawa apa yang mereka katakan akan berakhir dalam transkripsi.
Menariknya, satu lagi isu berkaitan yang kami lihat ialah pengguna menapis diri mereka sendiri untuk mengelakkan perkara tertentu muncul dalam transkripsi. Ini adalah perkara biasa yang mengejutkan, dan saya melihat banyak kes di mana pengguna menjelaskan bahawa mereka tidak mahu bot mentranskripsikan apa yang akan mereka katakan jadi mereka berhenti dan kemudian memulakan semula STT. Ini adalah kebimbangan yang sah sepenuhnya di pihak pengguna jika contohnya mereka tidak mahu bot mentranskripsikan beberapa maklumat sensitif.
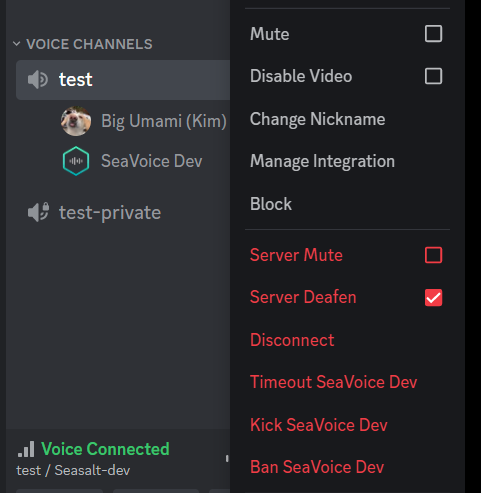
Cara menjeda STT dengan memekakkan bot.
Saya tidak pasti ada cara kami boleh meningkatkan pengalaman pengguna dalam kes ini, tetapi saya akan menasihati pengguna bahawa mereka boleh “memekakkan” bot buat sementara waktu untuk berhenti menghantar sebarang audio kepada bot. Dalam kes ini, bot tidak akan menerima sebarang data audio sehingga ia “tidak dipekakkan”, jadi pengguna pada dasarnya boleh menjeda sesi STT tanpa menghentikan dan memulakan yang baharu.

Seorang pengguna SeaVoice mengulas tentang ketidakselesaan peserta lain dengan bot.
Akhir sekali, isu terakhir yang kami lihat ialah sesetengah pengguna berasa sangat tidak selesa dengan transkripsi bot sehingga mereka secara aktif mengelak daripada bercakap dalam saluran suara semasa bot hadir. Ini adalah bertentangan sepenuhnya dengan matlamat kami, iaitu untuk menjadikan saluran suara Discord lebih mudah diakses oleh semua orang. Walaupun kami berharap pengguna akan menerima dasar privasi kami dan mempercayai kami untuk menggunakan data mereka secara bertanggungjawab, kami benar-benar menghormati hak privasi setiap orang. Oleh itu, ciri seterusnya yang akan kami laksanakan ialah tetapan menarik diri STT. Ini akan membolehkan mana-mana pengguna mengecualikan diri mereka daripada rakaman dan transkripsi STT, dan data audio mereka tidak akan diakses atau dikumpul dalam apa jua cara oleh bot.
Kami berharap ciri-ciri yang dirancang ini akan membolehkan kami terus menjadikan saluran suara lebih mudah diakses oleh semua orang sambil memberi pengguna keupayaan untuk berinteraksi dengan Bot SeaVoice pada tahap yang mereka selesa. Bergerak ke hadapan kami akan terus berusaha untuk menangani masalah-masalah mencabar ini secara proaktif untuk menjadikan SeaVoice yang terbaik!
Terima kasih atas minat anda terhadap Bot Discord kami dan terima kasih kepada pengguna kami atas sokongan berterusan anda! Anda boleh mengetahui lebih lanjut tentang produk STT kami di Halaman Utama SeaVoice Speech-to-Text kami. Untuk demo satu-satu mana-mana produk Voice Intelligence kami, isi Borang Tempahan Demo.
Jika anda belum mencuba bot SeaVoice, anda boleh mengetahui lebih lanjut tentang bot kami dan menambahkannya ke pelayan anda dari Wiki Bot Discord SeaVoice. Jangan ragu juga untuk menyertai Pelayan Discord SeaVoice Rasmi kami.


