





Po uruchomieniu SeaVoice, jednego z najszybszych i najdokładniejszych botów zamiany tekstu na mowę i mowy na tekst na Discordzie, chcieliśmy zrozumieć, w jaki sposób użytkownicy faktycznie wchodzą w interakcje z usługami. W tym blogu omówimy nasze ustalenia po przeanalizowaniu kilku tygodni rzeczywistych danych użytkownika mowy na tekst.
SeaVoice: Bot Discord zamiany tekstu na mowę i mowy na tekst
Discord, będący platformą używaną głównie do połączenia czatowania audio i tekstowego, jest fantastycznym poligonem doświadczalnym dla usług inteligencji głosowej i przetwarzania języka naturalnego. Wdrożyliśmy bota SeaVoice, wyposażonego w polecenia zamiany tekstu na mowę i mowy na tekst, na Discordzie w sierpniu 2022 roku. Aby dowiedzieć się więcej o tym, jak działa bot, lub zobaczyć krótkie demo wideo, możesz odwiedzić wiki bota SeaVoice. W listopadzie tego samego roku wydaliśmy nową wersję ze znacznymi ulepszeniami backendu (jak opisano w naszym poście na blogu: Bot Discord SeaVoice: Ulepszenia backendu i stabilności), które pozwalają nam rejestrować anonimowe dane dotyczące interakcji użytkowników z botem SeaVoice. W naszym ostatnim blogu (Studium przypadku bota Discord TTS) przeanalizowaliśmy miesięczne dane użytkownika z polecenia zamiany tekstu na mowę. W ramach kontynuacji, w tym poście przyjrzymy się danym użytkownika mowy na tekst z około 3 tygodni.
Użycie STT SeaVoice
W W chwili pisania tego tekstu, bot SeaVoice został dodany do prawie 900 serwerów! Około 260 serwerów, liczących łącznie ponad 600 uczestników, faktycznie wypróbowało polecenie STT co najmniej raz. W ciągu ostatnich 3 tygodni przeprowadziliśmy prawie 1800 sesji STT i wygenerowaliśmy łącznie ponad pół miliona linii transkrypcji.
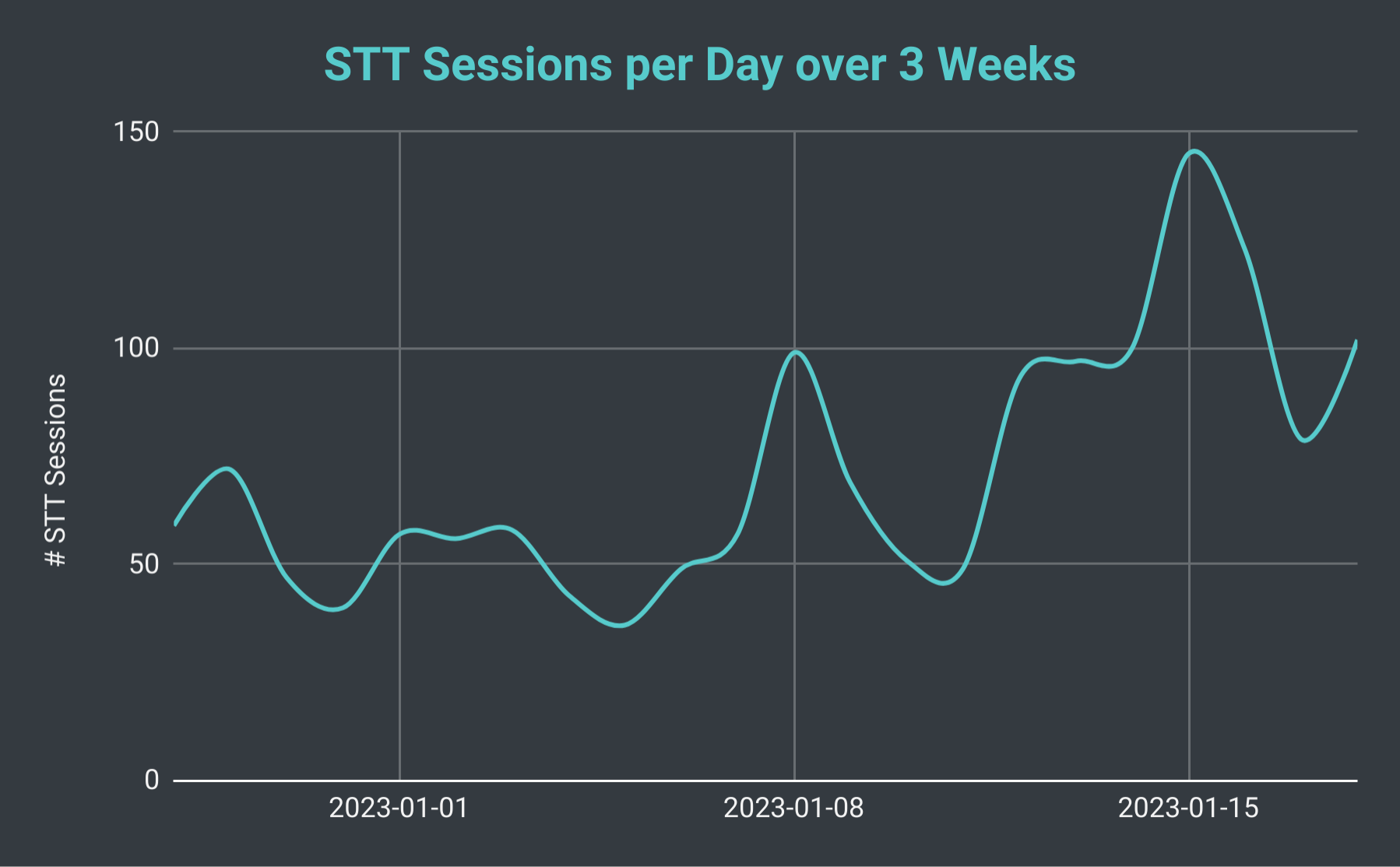
Dzienne sesje mowy na tekst bota Discord SeaVoice przez 3 tygodnie.
Jeśli spojrzymy na całkowitą liczbę sesji STT dziennie, stwierdziliśmy, że może ona wahać się od zaledwie 40 do ponad 140 (ze średnią około 70). Możemy również wziąć pod uwagę całkowitą liczbę generowanych przez nas linii transkrypcji. W najwolniejszym dniu produkujemy zaledwie 10 tysięcy linii, jednak w pracowity dzień wyprodukowaliśmy ponad 40 tysięcy linii. Aby to ująć w perspektywie, 18 stycznia przeprowadziliśmy 102 sesje STT z łączną liczbą nieco poniżej 30 tysięcy linii transkrypcji; co stanowiło prawie 40 godzin czasu nagrywania.
Stwierdziliśmy również, że chociaż większość sesji jest używana do krótszych rozmów (mediana 57 linii na sesję), istnieje znaczna liczba bardzo długich sesji, które podnoszą średnią do 650 linii na sesję. Nasza najdłuższa sesja miała ponad 30 tysięcy linii, czyli więcej niż średnia dzienna! Na koniec przyjrzeliśmy się również, ilu użytkowników zazwyczaj znajduje się w każdej sesji i stwierdziliśmy, że zazwyczaj jest 4 do 5 użytkowników w każdej sesji - jednak raz użyliśmy bota do obsługi transkrypcji na żywo na wirtualnym seminarium, w którym uczestniczyło 45 osób!
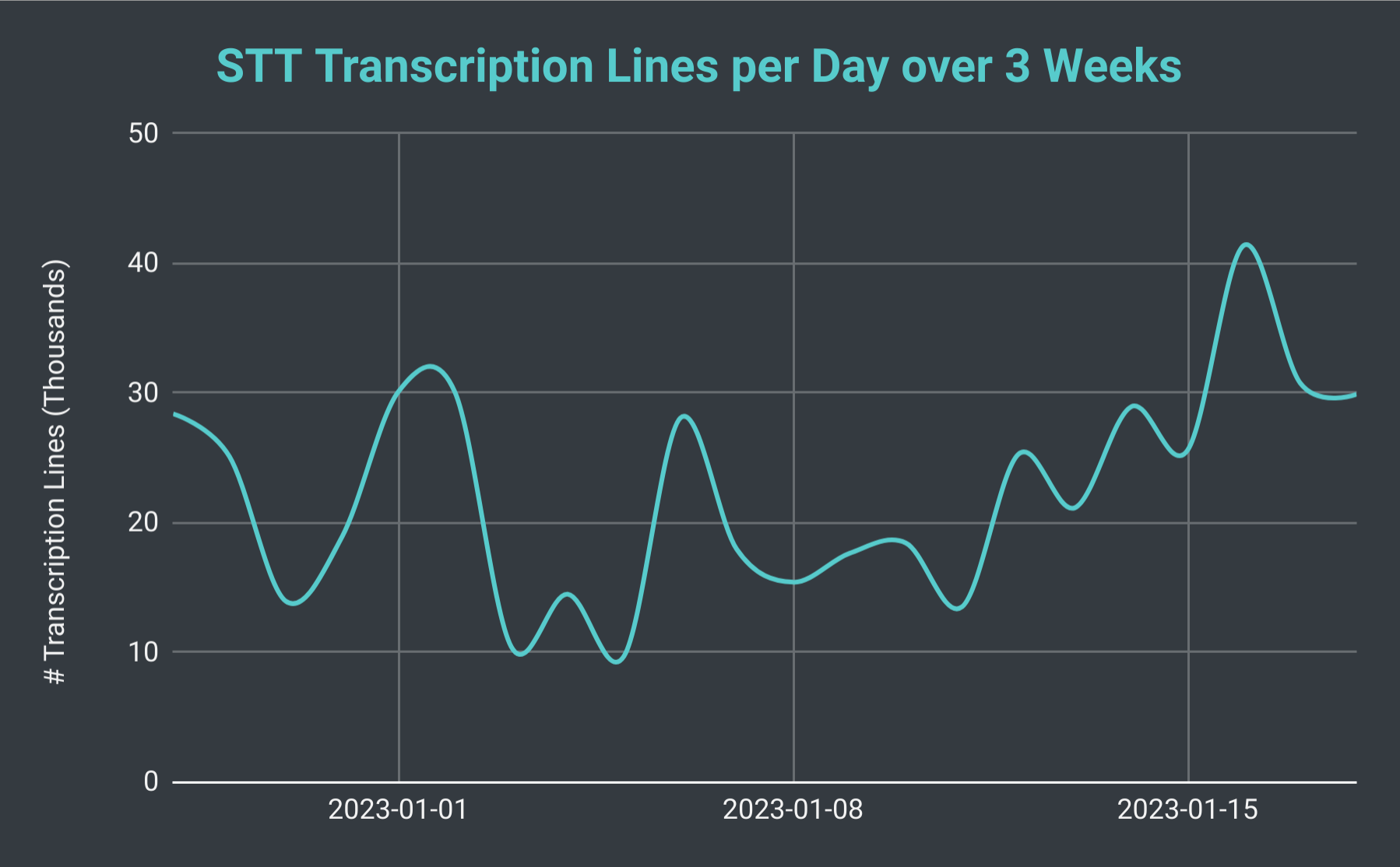
Linie transkrybowane przez bota Discord SeaVoice dziennie przez 3 tygodnie.
Chociaż większość serwerów nie używała sesji STT więcej niż kilka razy, jest ich sporo, które intensywnie korzystają z tej usługi. Od kiedy zaczęliśmy rejestrować dane użycia STT pod koniec grudnia, średnia całkowita liczba sesji na serwer wynosi około 7; jednak nasz serwer nr 1 zarejestrował 131 sesji - to średnio ponad 6 sesji dziennie! Ten sam serwer przetranskrybował ponad 150 tysięcy linii mowy w zaledwie 3 tygodnie! Być może bardziej imponujące jest to, że nasz użytkownik nr 1 pochodzi z tego samego serwera i przetranskrybował ponad 60 tysięcy linii własnej mowy!
Obserwacje
Dlaczego ludzie używają mowy na tekst

Użytkownik bota Discord SeaVoice wyraża podekscytowanie z powodu trwałych plików audio i transkrypcji.
Więc nasze pierwsze pytanie po zobaczeniu danych użycia brzmi: dlaczego częstotliwi użytkownicy w ogóle korzystają z mowy na tekst?
Przejrzeliśmy bazę danych, aby znaleźć pewne wyjaśnienia. Okazało się jednak, że trudniej jest znaleźć konkretne wyjaśnienia, dlaczego użytkownicy korzystali z usługi STT w przeciwieństwie do usługi TTS. Najwyraźniej ludzie czują potrzebę wyjaśniania innym na czacie, dlaczego używają TTS, ale mniej w przypadku STT. Niezależnie od tego, znalazłem kilka interesujących transkrypcji, które dały pewien wgląd w to, dlaczego użytkownicy decydują się na korzystanie z usługi STT.
Dlaczego użytkownicy korzystają z STT:
- „Dlatego transkrypcja jest używana, ponieważ mogę spojrzeć na rzeczy, które przegapiłem.”
- „[użytkownik] ma problemy ze słuchem, więc dostaje bota, który to transkrybuje”
- „[użytkownik] raiduje z nimi i używają tego do transkrypcji rzeczy, ale potem [użytkownik] powiedział, och, możemy tego użyć również do ******* D i D”
- „Nie mogę się doczekać, aby wrócić i przeczytać niektóre z tych transkrypcji później […] Chcę posłuchać tego nagrania i ponownie spojrzeć na tę transkrypcję”
- „Jeśli mamy tutaj nasze spotkania, to możemy przekazać transkrypcję spotkania do AI”
- „Podczas spotkania z ludźmi, wspaniale jest faktycznie zobaczyć transkrypcję”
- „[ludzie], którzy nie są na czacie lub ludzie, którzy są w społeczności, ale nie są częścią czatu głosowego, ale decydują się spojrzeć i przeczytać”
Ogólnie rzecz biorąc, wydaje się, że większość użytkowników ceni sobie wygodę posiadania transkrypcji na żywo, która może pomóc im śledzić rozmowę i uzupełnić wszelkie luki, które przegapili. Dotyczy to w szczególności użytkowników z wadami słuchu lub problemami z dźwiękiem/połączeniem. Dla niektórych użytkowników największą zaletą jest zachowanie trwałego zapisu audio i tekstowego ich rozmowy; może to być szczególnie przydatne w przypadkach użycia, takich jak prowadzenie dziennika sesji Dungeons & Dragons lub prowadzenie rejestru ważnych spotkań.
Ponieważ wielu użytkowników nie powiedziało wyraźnie, dlaczego korzystali z usługi STT, wydawało się również przydatne, aby zorientować się, co robili podczas korzystania z bota. Przeglądanie transkrypcji od użytkowników dało mi wskazówki, jakie czynności wykonywali podczas transkrypcji:
Co użytkownicy robią podczas korzystania z STT:
- Po prostu czatują
- Granie:
- Swobodne granie
- Zaawansowane granie (np. koordynowanie grupy MMO, Massive Multiplayer Online, raidy)
- Gry fabularne (Dungeons & Dragons)
- Streamowanie / nagrywanie treści
- Dyskusje szkolne / zawodowe / wolontariackie
Zdecydowana większość transkrypcji należy do kategorii „po prostu czatowanie” i „swobodne granie”. Jak widzieliśmy powyżej, myślę, że większość użytkowników w tym przypadku wykorzystuje bota do poprawy dostępności kanału głosowego Discord i/lub czerpie przyjemność z oglądania transkrypcji na żywo, aby uzupełnić wszelkie luki, które przegapili w rozmowie. W niektórych przypadkach (jak w przypadku raidów MMO) dyskusje o grach są bardzo złożone, a użytkownicy koordynują się ze sobą w czasie rzeczywistym; transkrypcje na żywo mogą okazać się niezwykle przydatne dla sukcesu zespołu, ponieważ użytkownicy mogą odwoływać się do transkrypcji podczas gry.
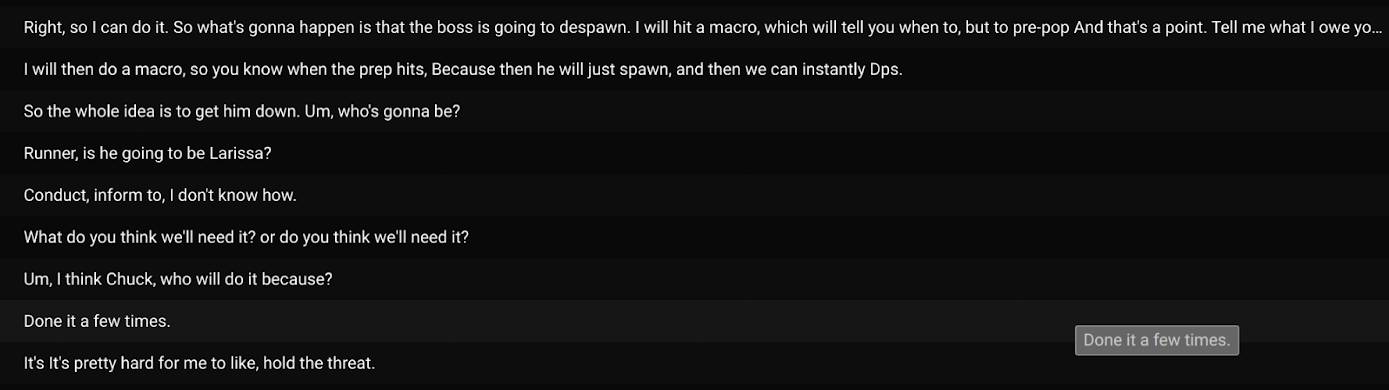
Przykład złożonej dyskusji podczas rajdu MMO.
Wydaje się również, że wielu użytkowników używa bota do transkrypcji poważniejszych rozmów, takich jak spotkania szkolne, zawodowe i/lub społeczności wolontariackie. Użyliśmy również naszego bota do transkrypcji internetowej konferencji technologicznej, UnTechCon. W takich przypadkach końcowe pliki nagrań i transkrypcji mogą okazać się bardzo pomocne dla użytkowników do przeglądu po spotkaniu. Ostatnim interesującym przykładem, który znalazłem, był użytkownik nagrywający treści do swojego strumienia. Ponieważ końcowa transkrypcja zawiera znaczniki czasu, użytkownicy mogą potencjalnie przesłać plik transkrypcji jako napisy do nagranego dźwięku lub treści wideo.
Użytkownik SeaVoice dziękuje za uczynienie kanałów głosowych Discorda bardziej dostępnymi.
Niezależnie od dokładnego powodu, dla którego korzystają z usługi STT, wielu użytkowników wyraziło podekscytowanie, że mogli uczestniczyć w rozmowach na kanale głosowym, gdy w przeciwnym razie nie byliby w stanie. Wierzymy, że usługa STT sprawia, że kanały głosowe Discorda są bardziej dostępne, i to jest główny powód, dla którego nasi stali użytkownicy nadal korzystają z tej usługi.
Komentarze na temat bota Discord SeaVoice
Innym interesującym tematem znalezionym w logach były komentarze na temat samego bota. Na szczęście widzieliśmy kilka bardzo pozytywnych komentarzy na temat bota i jego wydajności.

Użytkownik SeaVoice komentuje dokładność transkrypcji.
Znaleźliśmy również kilka konstruktywnych uwag.

Użytkownik SeaVoice sugeruje poprawę dla brytyjskich akcentów.

Użytkownik porównuje wydajność SeaVoice w języku angielskim z akcentem do Siri.
Większość konstruktywnych komentarzy dotyczyła tego, że bot nie działał dobrze w języku angielskim z akcentem innym niż amerykański; w szczególności użytkownicy wspominali o akcentach brytyjskich i szkockich. W przyszłości naszych usług STT moglibyśmy włożyć znaczny wysiłek w poprawę rozpoznawania mowy dla różnych akcentów języka angielskiego. Oczywiście angielski nie jest jedynym językiem, którym posługują się nasi użytkownicy, więc planujemy również dodać więcej obsługi języków do bota. W rzeczywistości, obecnie finalizujemy nasze integracje STT i TTS w języku mandaryńskim tajwańskim i wkrótce wydamy zaktualizowaną wersję bota.
Prywatność, wrażliwość danych i potencjalnie obraźliwe treści
Rozwój AI jest otoczony potokiem dylematów etycznych. Nasze modele potrzebują ogromnych ilości rzeczywistych danych użytkownika, aby dobrze działać, ale jak zbierać te dane etycznie, szanując prywatność naszych użytkowników? Modele uczą się tylko na podstawie dostarczonych im danych i dlatego mają (potencjalnie nieprzewidziane) uprzedzenia; więc jak możemy upewnić się, że nasze modele służą wszystkim naszym użytkownikom równie dobrze? Ponadto nasze modele nie mają pojęcia o akceptowalności społecznej i mogą generować wyniki, które niektórzy użytkownicy uznają za obraźliwe. Jak to ujął jeden z naszych użytkowników: „Czy to rasistowskie, jeśli bot to robi, to jest pytanie”.

Użytkownik SeaVoice wskazuje na problematyczną niedokładną transkrypcję.
Powodem, dla którego poruszam te kwestie, jest kilka niepokojących transkrypcji w logach. Pierwszym problemem jest to, że bot sporadycznie transkrybuje obraźliwe treści. W powyższym przykładzie bot przypadkowo przetranskrybował nazwę użytkownika jako rasistowskie obelgi. Oczywiście jest to błąd po stronie bota, który może być obraźliwy dla naszych użytkowników i powinien zostać zbadany. Ale to prowadzi do dalszych pytań: gdzie wyznaczyć granicę między obrazą a krzywdą?

Użytkownik SeaVoice komentuje próbę cenzurowania niektórych słów z transkrypcji.
Cóż, na początek zdecydowaliśmy się dać tę moc użytkownikom. Jedną z kolejnych funkcji, nad którą będziemy pracować, jest konfigurowalna cenzura TTS i STT. Pozwoli to serwerom opcjonalnie stosować cenzurę dla wulgaryzmów, treści seksualnych, rasistowskich obelg itp.

Użytkownik SeaVoice ostrzega innego uczestnika, aby był świadomy, że to, co powie, znajdzie się w transkrypcji.
Co ciekawe, innym powiązanym problemem, który zauważyliśmy, było to, że użytkownicy cenzurowali się, aby uniknąć pojawienia się pewnych rzeczy w transkrypcji. Było to zaskakująco powszechne, i widziałem wiele przypadków, w których użytkownicy wyjaśniali, że nie chcieli, aby bot transkrybował to, co mieli zamiar powiedzieć, więc zatrzymali się, a następnie ponownie uruchomili STT. Jest to całkowicie uzasadniona obawa ze strony użytkownika, jeśli na przykład nie chcą, aby bot transkrybował wrażliwe informacje.
Jak wstrzymać STT, ogłuszając bota.
Nie jestem pewien, czy możemy w jakikolwiek sposób poprawić doświadczenie użytkownika w tym przypadku, ale radziłbym użytkownikom, aby mogli tymczasowo „ogłuszyć” bota, aby przestał wysyłać jakikolwiek dźwięk do bota. W takim przypadku bot nie otrzyma żadnych danych audio, dopóki nie zostanie „odgłuszony”, więc użytkownik może zasadniczo wstrzymać sesję STT bez zatrzymywania i rozpoczynania nowej.

Użytkownik SeaVoice komentuje dyskomfort innego uczestnika z botem.
Na koniec, ostatnim problemem, który zauważyliśmy, jest to, że niektórzy użytkownicy czują się tak niekomfortowo z transkrypcją bota, że aktywnie unikają mówienia na kanale głosowym, gdy bot jest obecny. Jest to całkowite przeciwieństwo naszego celu, którym jest uczynienie kanałów głosowych Discorda bardziej dostępnymi dla wszystkich. Chociaż mamy nadzieję, że użytkownicy zaakceptują naszą politykę prywatności i zaufają nam, że będziemy odpowiedzialnie wykorzystywać ich dane, absolutnie szanujemy prawo każdego do prywatności. W związku z tym, następną funkcją, którą wdrożymy, będzie ustawienie rezygnacji z STT. Pozwoli to każdemu użytkownikowi wykluczyć się z nagrywania i transkrypcji STT, a ich dane audio nie będą w żaden sposób dostępne ani zbierane przez bota.
Mamy nadzieję, że te planowane funkcje pozwolą nam nadal udostępniać kanały głosowe wszystkim, jednocześnie dając użytkownikom możliwość interakcji z botem SeaVoice na poziomie, z którym czują się komfortowo. W przyszłości będziemy nadal proaktywnie rozwiązywać te trudne problemy, aby SeaVoice był jak najlepszy!
Dziękujemy za zainteresowanie naszym botem Discord i dziękujemy naszym użytkownikom za ciągłe wsparcie! Więcej o naszym produkcie STT dowiesz się na naszej stronie głównej SeaVoice Speech-to-Text. Aby uzyskać indywidualne demo dowolnego z naszych produktów Voice Intelligence, wypełnij formularz rezerwacji demo.
Jeśli jeszcze nie wypróbowałeś bota SeaVoice, możesz dowiedzieć się więcej o naszym bocie i dodać go do swojego serwera z wiki bota Discord SeaVoice. Zapraszamy również do dołączenia do naszego oficjalnego serwera Discord SeaVoice.


