





หลังจากเปิดตัว SeaVoice ซึ่งเป็นหนึ่งในบอทแปลงข้อความเป็นคำพูดและแปลงคำพูดเป็นข้อความที่เร็วและแม่นยำที่สุดบน Discord เราต้องการทำความเข้าใจว่าผู้ใช้โต้ตอบกับบริการอย่างไร ในบล็อกนี้ เราจะมาพูดคุยถึงสิ่งที่เราค้นพบหลังจากตรวจสอบข้อมูลผู้ใช้แปลงคำพูดเป็นข้อความจริงเป็นเวลาหลายสัปดาห์
SeaVoice: บอท Discord แปลงข้อความเป็นคำพูดและแปลงคำพูดเป็นข้อความ
Discord ซึ่งเป็นแพลตฟอร์มที่ใช้เป็นหลักสำหรับการรวมการแชทด้วยเสียงและข้อความ เป็นสนามทดสอบที่ยอดเยี่ยมสำหรับบริการปัญญาเสียงและการประมวลผลภาษาธรรมชาติ เราได้ปรับใช้ SeaVoice Bot ซึ่งมีคำสั่งแปลงข้อความเป็นคำพูดและแปลงคำพูดเป็นข้อความ ไปยัง Discord ในเดือนสิงหาคม 2022 หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการทำงานของบอท หรือดูวิดีโอสาธิตสั้นๆ คุณสามารถเยี่ยมชม วิกิ SeaVoice Bot ในเดือนพฤศจิกายนของปีเดียวกัน เราได้เปิดตัวเวอร์ชันใหม่ที่มีการปรับปรุงแบ็กเอนด์ที่สำคัญ (ตามที่อธิบายไว้ในบล็อกโพสต์ของเรา: SeaVoice Discord Bot: การปรับปรุงแบ็กเอนด์และเสถียรภาพ) ซึ่งช่วยให้เราสามารถบันทึกข้อมูลที่ไม่ระบุชื่อเกี่ยวกับวิธีที่ผู้ใช้โต้ตอบกับบอท SeaVoice ในบล็อกล่าสุดของเรา (กรณีศึกษาบอท Discord TTS) เราได้วิเคราะห์ข้อมูลผู้ใช้ 1 เดือนจากคำสั่งแปลงข้อความเป็นคำพูด ในการติดตามผล ในโพสต์นี้ เราจะมาดูข้อมูลผู้ใช้แปลงคำพูดเป็นข้อความประมาณ 3 สัปดาห์
การใช้งาน SeaVoice STT
ณ เวลาที่เขียน SeaVoice Bot ได้ถูกเพิ่มไปยังเซิร์ฟเวอร์เกือบ 900 แห่ง! ประมาณ 260 เซิร์ฟเวอร์ รวมผู้เข้าร่วมกว่า 600 คน ได้ลองใช้คำสั่ง STT อย่างน้อยหนึ่งครั้ง ในช่วง 3 สัปดาห์ที่ผ่านมา เราได้จัดเซสชัน STT เกือบ 1,800 เซสชัน และส่งออก บรรทัดการถอดความรวมกว่าครึ่งล้านบรรทัด
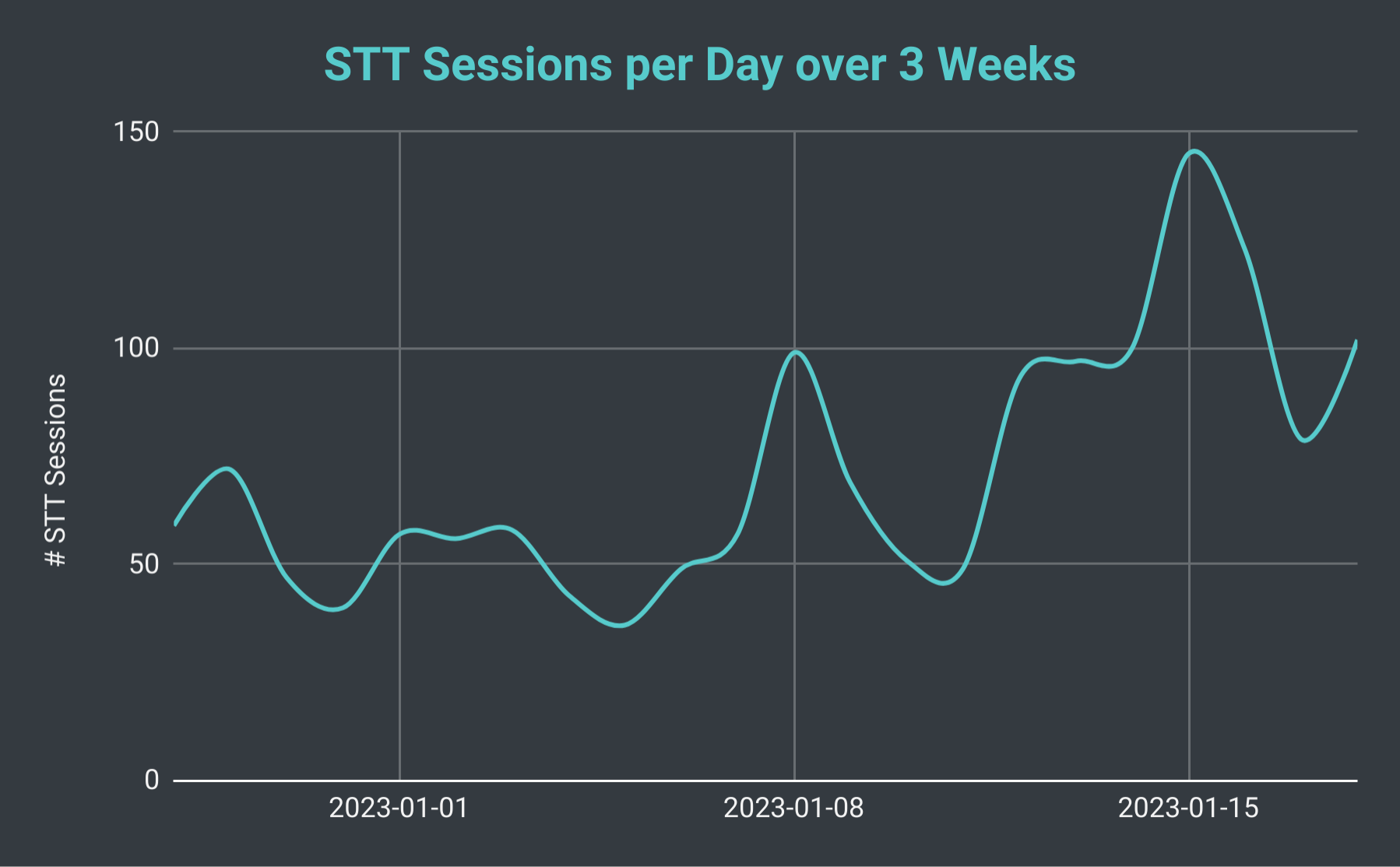
เซสชันการพูดเป็นข้อความรายวันของ SeaVoice Discord Bot ตลอด 3 สัปดาห์
หากเราดูจำนวนเซสชัน STT ทั้งหมดต่อวัน เราพบว่ามันสามารถผันผวนได้ตั้งแต่ 40 ถึงมากกว่า 140 (โดยเฉลี่ยประมาณ 70) เรายังสามารถพิจารณาจำนวนบรรทัดการถอดความทั้งหมดที่เราผลิตได้ ในวันที่ช้าที่สุด เราผลิตได้น้อยถึง 10,000 บรรทัด อย่างไรก็ตาม ในวันที่ยุ่ง เราผลิตได้มากกว่า 40,000 บรรทัด เพื่อให้เห็นภาพ ในวันที่ 18 มกราคม เราจัดเซสชัน STT 102 เซสชัน โดยมีบรรทัดการถอดความรวมเกือบ 30,000 บรรทัด ซึ่งเท่ากับเวลาบันทึกเกือบ 40 ชั่วโมง
เรายังพบว่าในขณะที่เซสชันส่วนใหญ่ใช้สำหรับการสนทนาที่สั้นกว่า (ค่ามัธยฐาน 57 บรรทัดต่อเซสชัน) แต่ก็มีเซสชันที่ยาวมากจำนวนมากที่ทำให้ค่าเฉลี่ยสูงถึง 650 บรรทัดต่อเซสชัน เซสชันที่ยาวที่สุดของเรามีมากกว่า 30,000 บรรทัด ซึ่งมากกว่าค่าเฉลี่ยของวัน! สุดท้าย เรายังได้ดูว่ามีผู้ใช้กี่คนในแต่ละเซสชัน และพบว่าโดยทั่วไปมีผู้ใช้ 4 ถึง 5 คนในแต่ละเซสชัน - อย่างไรก็ตาม เราเคยใช้บอทเพื่อรองรับการถอดความสดในการสัมมนาเสมือนจริงซึ่งมีผู้เข้าร่วม 45 คน!
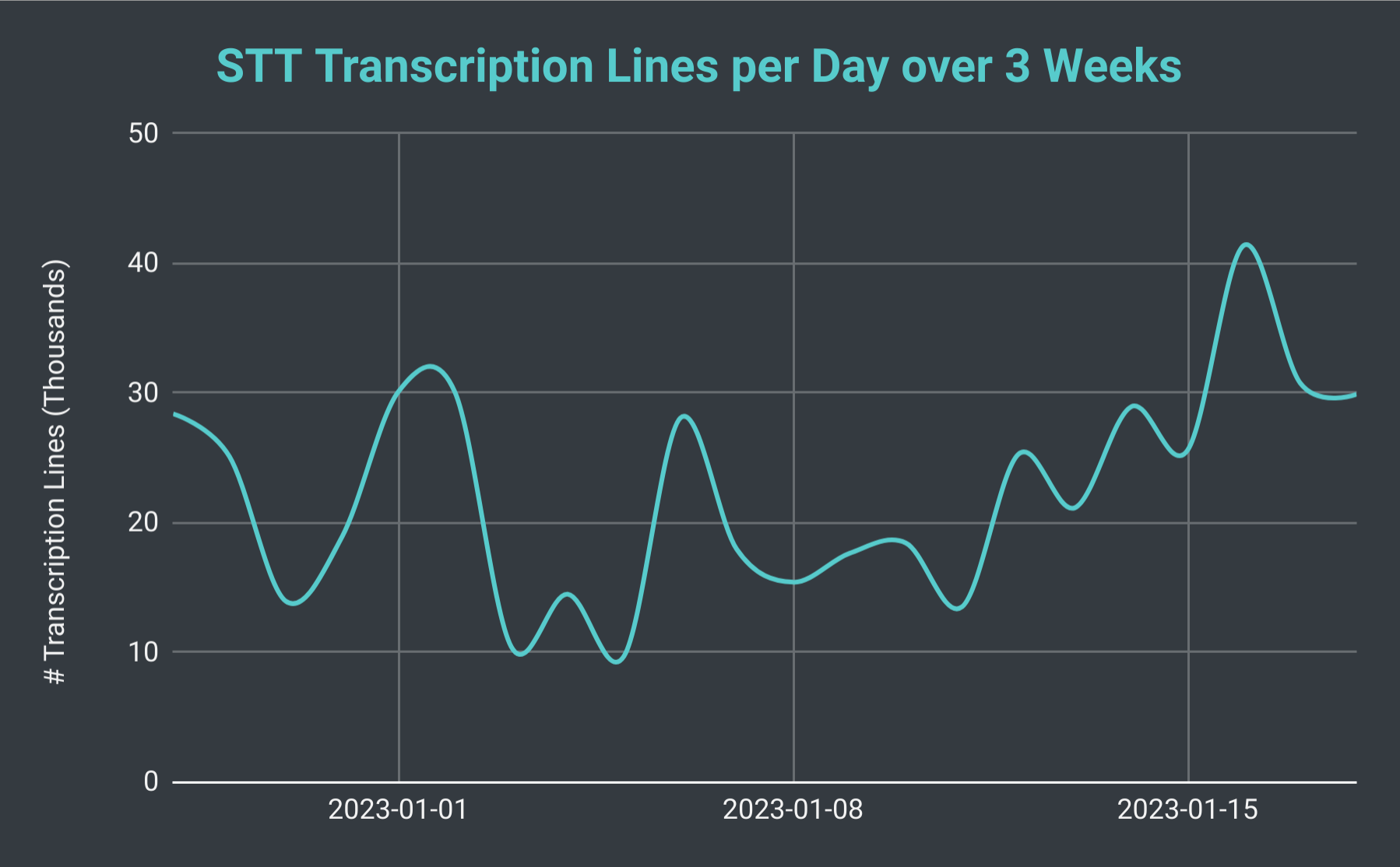
บรรทัดที่ถอดความโดย SeaVoice Discord Bot ต่อวันตลอด 3 สัปดาห์
ในขณะที่เซิร์ฟเวอร์ส่วนใหญ่ไม่ได้ใช้เซสชัน STT มากกว่าสองสามครั้ง แต่ก็มีหลายเซิร์ฟเวอร์ที่ใช้บริการนี้อย่างกว้างขวาง ตั้งแต่เราเริ่มบันทึกข้อมูลการใช้งาน STT ในปลายเดือนธันวาคม จำนวนเซสชันทั้งหมดเฉลี่ยต่อเซิร์ฟเวอร์อยู่ที่ประมาณ 7; อย่างไรก็ตาม เซิร์ฟเวอร์อันดับ 1 ของเราได้บันทึก 131 เซสชัน - นั่นคือเฉลี่ยมากกว่า 6 เซสชันต่อวัน! เซิร์ฟเวอร์เดียวกันนี้ได้ถอดความเสียงพูดมากกว่า 150,000 บรรทัดในเวลาเพียง 3 สัปดาห์! อาจจะน่าประทับใจยิ่งกว่านั้น ผู้ใช้หมายเลข 1 ของเรามาจากเซิร์ฟเวอร์เดียวกันและมีเสียงพูดของตัวเองที่ถอดความแล้วมากกว่า 60,000 บรรทัด!
ข้อสังเกต
ทำไมผู้คนถึงใช้การพูดเป็นข้อความ

ผู้ใช้บอท Discord SeaVoice แสดงความตื่นเต้นเกี่ยวกับไฟล์เสียงและข้อความถอดความที่คงอยู่
ดังนั้นคำถามแรกของเราหลังจากเห็นข้อมูลการใช้งานคือ: ทำไมผู้ใช้ที่ใช้งานบ่อยถึงใช้การพูดเป็นข้อความตั้งแต่แรก?
เราได้ตรวจสอบฐานข้อมูลเพื่อหาคำอธิบายบางอย่าง อย่างไรก็ตาม การหาคำอธิบายที่เป็นรูปธรรมว่าทำไมผู้ใช้ถึงใช้บริการ STT แทนบริการ TTS นั้นยากกว่า เห็นได้ชัดว่าผู้คนรู้สึกว่าจำเป็นต้องอธิบายให้ผู้อื่นในแชทฟังว่าทำไมพวกเขาถึงใช้ TTS แต่ไม่ค่อยมีกับ STT อย่างไรก็ตาม ฉันพบการถอดความที่น่าสนใจบางอย่างที่ให้ข้อมูลเชิงลึกว่าทำไมผู้ใช้จึงตัดสินใจใช้บริการ STT
ทำไมผู้ใช้ถึงใช้ STT:
- “นี่คือเหตุผลที่ใช้การถอดความ เพราะฉันสามารถดูสิ่งที่ฉันพลาดไปได้”
- “[ผู้ใช้] มีปัญหาทางการได้ยิน ดังนั้นเขาจึงได้บอทที่ถอดความให้”
- “[ผู้ใช้] บุกโจมตีกับพวกเขาและพวกเขาใช้มันเพื่อถอดความสิ่งต่างๆ แต่แล้ว [ผู้ใช้] ก็พูดว่า โอ้ เราสามารถใช้สิ่งนั้นสำหรับ ******* D และ D ได้ด้วย”
- “ฉันแทบรอไม่ไหวที่จะกลับไปอ่านข้อความถอดความเหล่านี้ในภายหลัง […] ฉันอยากกลับไปฟังการบันทึกนั้นและดูข้อความถอดความนั้นอีกครั้ง”
- “ถ้าเรามีการประชุมที่นี่ เราก็สามารถป้อนข้อความถอดความของการประชุมเข้าสู่ AI ได้”
- “ระหว่างการประชุมกับผู้คน การได้เห็นข้อความถอดความนั้นยอดเยี่ยมมาก”
- “[ผู้คน] ที่ไม่ได้อยู่ในแชท หรือผู้คนที่อยู่ในชุมชน แต่ไม่ได้เป็นส่วนหนึ่งของการแชทด้วยเสียง แต่พวกเขาตัดสินใจที่จะดูและอ่าน”
โดยทั่วไปแล้ว ดูเหมือนว่าผู้ใช้ส่วนใหญ่จะเพลิดเพลินกับความสะดวกสบายของการถอดความสดที่สามารถช่วยให้พวกเขาติดตามการสนทนาและเติมเต็มช่องว่างที่พวกเขาพลาดไปได้ สิ่งนี้เป็นจริงโดยเฉพาะอย่างยิ่งสำหรับผู้ใช้ที่มีความบกพร่องทางการได้ยินหรือปัญหาด้านเสียง/การเชื่อมต่อ สำหรับผู้ใช้บางราย ประโยชน์ที่ใหญ่ที่สุดคือการเก็บรักษาบันทึกเสียงและข้อความถาวรของการสนทนาของพวกเขา สิ่งนี้อาจนำไปใช้ได้จริงสำหรับกรณีการใช้งาน เช่น การเก็บรักษาบันทึกเซสชัน Dungeons & Dragons หรือการเก็บรักษาบันทึกการประชุมที่สำคัญ
เนื่องจากผู้ใช้จำนวนมากไม่ได้ระบุอย่างชัดเจนว่าทำไมพวกเขาถึงใช้บริการ STT จึงดูเหมือนมีประโยชน์ที่จะทำความเข้าใจว่าพวกเขากำลังทำอะไรในขณะที่ใช้บอท การตรวจสอบการถอดความจากผู้ใช้ทำให้ฉันทราบถึงกิจกรรมที่พวกเขากำลังทำในขณะที่ถอดความ:
สิ่งที่ผู้ใช้กำลังทำในขณะที่ใช้ STT:
- แค่คุยกัน
- เล่นเกม:
- เล่นเกมทั่วไป
- เล่นเกมขั้นสูง (เช่น/ ประสานงานกลุ่ม MMO, Massive Multiplayer Online, raids)
- เกมสวมบทบาท (Dungeons & Dragons)
- สตรีมมิ่ง / บันทึกเนื้อหา
- พูดคุยเรื่องงานโรงเรียน / อาชีพ / อาสาสมัคร
การถอดความส่วนใหญ่จัดอยู่ในหมวดหมู่ “แค่คุยกัน” และ “เล่นเกมทั่วไป” ดังที่เราเห็นข้างต้น ฉันคิดว่าผู้ใช้ส่วนใหญ่ในกรณีนี้ใช้บอทเพื่อปรับปรุงการเข้าถึงช่องเสียง Discord และ/หรือเพลิดเพลินกับความสะดวกสบายในการดูการถอดความสดเพื่อเติมเต็มช่องว่างที่พวกเขาพลาดไปในการสนทนา ในบางกรณี (เช่น เมื่อใช้สำหรับการบุกโจมตี MMO) การสนทนาเกี่ยวกับการเล่นเกมนั้นซับซ้อนมาก และผู้ใช้กำลังประสานงานกันแบบเรียลไทม์ การถอดความสดอาจพิสูจน์ได้ว่ามีประโยชน์อย่างยิ่งต่อความสำเร็จของทีม เนื่องจากผู้ใช้สามารถอ้างอิงการถอดความได้ในขณะที่กำลังเล่น
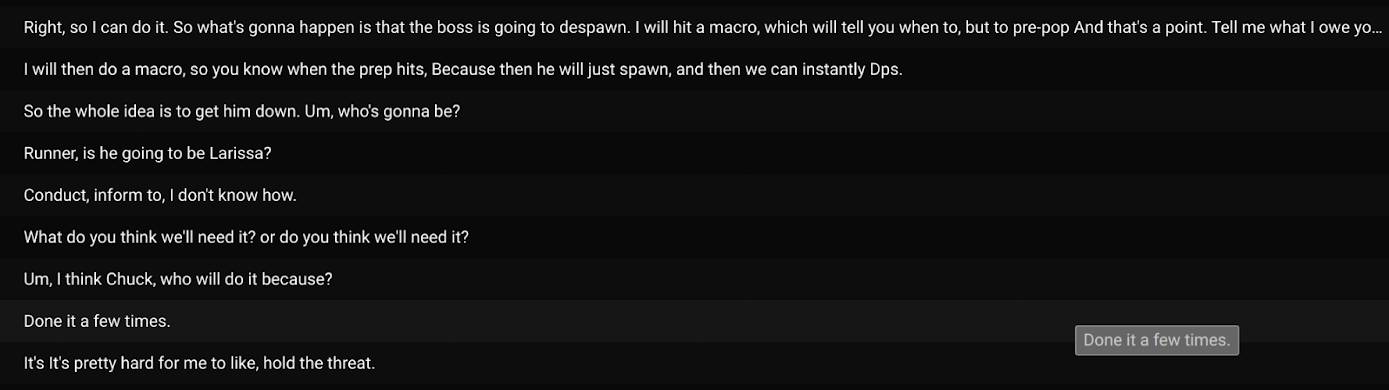
ตัวอย่างการสนทนาที่ซับซ้อนระหว่างการบุกโจมตี MMO
ดูเหมือนว่าผู้ใช้จำนวนมากกำลังใช้บอทเพื่อถอดความการสนทนาที่จริงจังมากขึ้น เช่น การประชุมโรงเรียน อาชีพ และ/หรือชุมชนอาสาสมัคร เรายังใช้บอทของเราเพื่อถอดความการประชุมเทคโนโลยีออนไลน์ UnTechCon ในกรณีเหล่านี้ ไฟล์บันทึกและถอดความขั้นสุดท้ายอาจมีประโยชน์อย่างมากสำหรับผู้ใช้ในการตรวจสอบหลังการประชุม ตัวอย่างที่น่าสนใจสุดท้ายที่ฉันพบคือผู้ใช้บันทึกเนื้อหาสำหรับสตรีมของพวกเขา เนื่องจากข้อความถอดความขั้นสุดท้ายมาพร้อมกับเวลา ผู้ใช้จึงสามารถอัปโหลดไฟล์ถอดความเป็นคำบรรยายสำหรับเนื้อหาเสียงหรือวิดีโอที่บันทึกไว้ได้
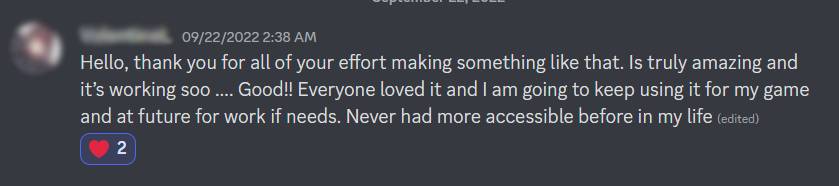
ผู้ใช้ SeaVoice แสดงความขอบคุณที่ทำให้ช่องเสียง Discord เข้าถึงได้ง่ายขึ้น
แต่ไม่ว่าจะด้วยเหตุผลใดก็ตามที่พวกเขาใช้บริการ STT ผู้ใช้จำนวนมากแสดงความตื่นเต้นที่พวกเขาสามารถเข้าร่วมการสนทนาในช่องเสียงได้ในขณะที่พวกเขาไม่สามารถทำได้ เราเชื่อว่าบริการ STT ทำให้ช่องเสียง Discord เข้าถึงได้ง่ายขึ้น และนั่นคือเหตุผลหลักที่ผู้ใช้ประจำของเรายังคงใช้บริการนี้
ความคิดเห็นเกี่ยวกับบอท Discord SeaVoice
อีกหัวข้อที่น่าสนใจที่พบในบันทึกคือความคิดเห็นเกี่ยวกับตัวบอทเอง โชคดีที่เราเห็นความคิดเห็นเชิงบวกหลายอย่างเกี่ยวกับบอทและประสิทธิภาพของมัน

ผู้ใช้ SeaVoice แสดงความคิดเห็นเกี่ยวกับความแม่นยำในการถอดความ
เรายังพบข้อเสนอแนะเชิงสร้างสรรค์หลายอย่าง

ผู้ใช้ SeaVoice แนะนำการปรับปรุงสำหรับสำเนียงอังกฤษ

ผู้ใช้เปรียบเทียบประสิทธิภาพของ SeaVoice ในภาษาอังกฤษสำเนียงกับ Siri
ความคิดเห็นเชิงสร้างสรรค์ส่วนใหญ่เกี่ยวข้องกับบอทที่ทำงานได้ไม่ดีกับภาษาอังกฤษสำเนียงที่ไม่ใช่ภาษาอเมริกัน โดยเฉพาะอย่างยิ่งผู้ใช้กล่าวถึงสำเนียงอังกฤษและสกอตแลนด์ สำหรับอนาคตของบริการ STT ของเรา เราสามารถทุ่มเทความพยายามอย่างมากในการปรับปรุงการรู้จำเสียงพูดของเราสำหรับสำเนียงภาษาอังกฤษต่างๆ แน่นอนว่าภาษาอังกฤษไม่ใช่ภาษาเดียวที่ผู้ใช้ของเราพูด ดังนั้นเราจึงวางแผนที่จะเพิ่มการรองรับภาษาเพิ่มเติมให้กับบอทด้วย อันที่จริง ขณะนี้เรากำลังสรุปการรวม STT และ TTS ภาษาจีนกลางไต้หวันของเรา และจะเปิดตัวบอทเวอร์ชันที่อัปเดตในไม่ช้า
ความเป็นส่วนตัว ความอ่อนไหวของข้อมูล และเนื้อหาที่อาจก่อให้เกิดความไม่พอใจ
การพัฒนา AI ถูกล้อมรอบด้วยกระแสของปัญหาทางจริยธรรม โมเดลของเราต้องการข้อมูลผู้ใช้จริงจำนวนมากเพื่อให้ทำงานได้ดี แต่เราจะรวบรวมข้อมูลนั้นอย่างมีจริยธรรมได้อย่างไรในขณะที่เคารพความเป็นส่วนตัวของผู้ใช้ของเรา? โมเดลเรียนรู้ตามข้อมูลที่ได้รับเท่านั้น และดังนั้นจึงมีอคติ (ที่อาจคาดไม่ถึง); ดังนั้นเราจะแน่ใจได้อย่างไรว่าโมเดลของเราให้บริการผู้ใช้ทุกคนได้ดีเท่าเทียมกัน? นอกจากนี้ โมเดลของเราไม่มีแนวคิดเรื่องการยอมรับทางสังคม และอาจสร้างผลลัพธ์ที่ผู้ใช้บางคนพบว่าไม่พอใจ ดังที่ผู้ใช้คนหนึ่งของเรากล่าวไว้อย่างคล่องแคล่ว: “มันเป็นการเหยียดเชื้อชาติหรือไม่ถ้าบอททำเช่นนั้น นั่นคือคำถาม”

ผู้ใช้ SeaVoice ชี้ให้เห็นการถอดความที่ไม่ถูกต้องซึ่งมีปัญหา
เหตุผลที่ฉันยกประเด็นเหล่านี้ขึ้นมาก็เพราะมีการถอดความที่น่ากังวลบางอย่างในบันทึก ปัญหาแรกคือบอทบางครั้งถอดความเนื้อหาที่ก่อให้เกิดความไม่พอใจ ในตัวอย่างข้างต้น บอทถอดความชื่อผู้ใช้ของใครบางคนผิดพลาดเป็นคำเหยียดเชื้อชาติ เห็นได้ชัดว่านี่เป็นข้อผิดพลาดของบอทที่อาจก่อให้เกิดความไม่พอใจต่อผู้ใช้ของเราและควรได้รับการตรวจสอบ แต่นี่นำไปสู่คำถามเพิ่มเติม: เราจะขีดเส้นแบ่งระหว่างการกระทำผิดและการทำร้ายร่างกายได้ที่ไหน?

ผู้ใช้ SeaVoice แสดงความคิดเห็นเกี่ยวกับการพยายามเซ็นเซอร์คำบางคำจากการถอดความ
เพื่อเริ่มต้น เราได้ตัดสินใจที่จะมอบอำนาจนั้นให้กับผู้ใช้ หนึ่งในคุณสมบัติถัดไปที่เราจะดำเนินการคือการเซ็นเซอร์ TTS และ STT ที่สามารถกำหนดค่าได้ ซึ่งจะช่วยให้เซิร์ฟเวอร์สามารถใช้การเซ็นเซอร์สำหรับคำหยาบคาย เนื้อหาทางเพศ คำเหยียดเชื้อชาติ ฯลฯ ได้ตามต้องการ

ผู้ใช้ SeaVoice เตือนผู้เข้าร่วมคนอื่นให้ระวังว่าสิ่งที่พวกเขาพูดจะปรากฏในการถอดความ
ที่น่าสนใจคือ ปัญหาที่เกี่ยวข้องอีกประการหนึ่งที่เราพบคือผู้ใช้เซ็นเซอร์ตัวเองเพื่อหลีกเลี่ยงไม่ให้บางสิ่งปรากฏในการถอดความ สิ่งนี้เป็นเรื่องปกติอย่างน่าประหลาดใจ และฉันเห็นหลายกรณีที่ผู้ใช้อธิบายว่าพวกเขาไม่ต้องการให้บอทถอดความสิ่งที่พวกเขากำลังจะพูด ดังนั้นพวกเขาจึงหยุดและเริ่ม STT ใหม่ นี่เป็นข้อกังวลที่ถูกต้องอย่างสมบูรณ์สำหรับผู้ใช้ หากตัวอย่างเช่น พวกเขาไม่ต้องการให้บอทถอดความข้อมูลที่ละเอียดอ่อนบางอย่าง
วิธีหยุด STT ชั่วคราวโดยการทำให้บอทหูหนวก
ฉันไม่แน่ใจว่ามีวิธีใดที่เราสามารถปรับปรุงประสบการณ์ผู้ใช้ในกรณีนี้ได้หรือไม่ แต่ฉันจะแนะนำผู้ใช้ว่าพวกเขาสามารถ “ทำให้บอทหูหนวก” ชั่วคราวเพื่อหยุดส่งเสียงใดๆ ไปยังบอทได้ ในกรณีนี้ บอทจะไม่ได้รับข้อมูลเสียงใดๆ จนกว่าจะถูก “ถอดหูหนวก” ดังนั้นผู้ใช้จึงสามารถหยุดเซสชัน STT ชั่วคราวได้โดยไม่ต้องหยุดและเริ่มเซสชันใหม่

ผู้ใช้ SeaVoice แสดงความคิดเห็นเกี่ยวกับความไม่สบายใจของผู้เข้าร่วมคนอื่นกับบอท
สุดท้าย ปัญหาสุดท้ายที่เราพบคือผู้ใช้บางคนรู้สึกไม่สบายใจกับการถอดความของบอทมากจนพวกเขาหลีกเลี่ยงการพูดในช่องเสียงอย่างแข็งขันในขณะที่บอทอยู่ด้วย นี่คือ สิ่งที่ตรงกันข้ามโดยสิ้นเชิง กับเป้าหมายของเรา ซึ่งก็คือการทำให้ช่องเสียง Discord เข้าถึงได้ง่ายขึ้นสำหรับทุกคน แม้ว่าเราหวังว่าผู้ใช้จะยอมรับ นโยบายความเป็นส่วนตัว ของเราและไว้วางใจให้เราใช้ข้อมูลของพวกเขาอย่างรับผิดชอบ แต่เราเคารพสิทธิ์ความเป็นส่วนตัวของทุกคนอย่างแน่นอน ดังนั้น คุณสมบัติถัดไปที่เราจะนำไปใช้คือการตั้งค่าการยกเลิก STT ซึ่งจะช่วยให้ผู้ใช้ทุกคนสามารถยกเว้นตัวเองจากการบันทึกและการถอดความ STT ได้ และข้อมูลเสียงของพวกเขาจะไม่ถูกเข้าถึงหรือรวบรวมโดยบอทในทางใดทางหนึ่ง
เราหวังว่าคุณสมบัติที่วางแผนไว้เหล่านี้จะช่วยให้เราสามารถทำให้ช่องเสียงเข้าถึงได้ง่ายขึ้นสำหรับทุกคนต่อไป ในขณะเดียวกันก็ให้ผู้ใช้มีอิสระในการโต้ตอบกับ SeaVoice Bot ในระดับที่พวกเขาสบายใจ ในอนาคต เราจะยังคงพยายามแก้ไขปัญหาที่ท้าทายเหล่านี้อย่างจริงจัง เพื่อให้ SeaVoice ดีที่สุดเท่าที่จะเป็นไปได้!
ขอขอบคุณสำหรับความสนใจในบอท Discord ของเรา และขอขอบคุณผู้ใช้ของเราสำหรับการสนับสนุนอย่างต่อเนื่อง! คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับผลิตภัณฑ์ STT ของเราได้ที่ หน้าแรก SeaVoice Speech-to-Text ของเรา สำหรับการสาธิตแบบตัวต่อตัวของผลิตภัณฑ์ Voice Intelligence ของเรา กรุณากรอก แบบฟอร์มจองการสาธิต
หากคุณยังไม่ได้ลองใช้บอท SeaVoice คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับบอทของเราและเพิ่มลงในเซิร์ฟเวอร์ของคุณได้จาก วิกิ SeaVoice Discord Bot นอกจากนี้ โปรดเข้าร่วม เซิร์ฟเวอร์ Discord SeaVoice อย่างเป็นทางการ ของเรา


