





Matapos ilunsad ang SeaVoice, isa sa pinakamabilis at pinakatumpak na text-to-speech at speech-to-text bot sa Discord, nais naming maunawaan kung paano aktwal na nakikipag-ugnayan ang mga gumagamit sa mga serbisyo. Sa blog na ito, tatalakayin namin ang aming mga natuklasan pagkatapos suriin ang ilang linggo ng tunay na data ng gumagamit ng speech-to-text.
SeaVoice: Isang Text-to-Speech at Speech-to-Text Discord Bot
Ang Discord, bilang isang platform na pangunahing ginagamit para sa kombinasyon ng audio at text-based na pakikipag-chat, ay isang kamangha-manghang lugar ng pagsubok para sa voice intelligence at natural language processing services. Ipinakalat namin ang SeaVoice Bot, na nilagyan ng text-to-speech at speech-to-text commands, sa Discord noong Agosto 2022. Upang matuto nang higit pa tungkol sa kung paano gumagana ang bot, o makita ang isang maikling video demo, maaari mong bisitahin ang SeaVoice Bot wiki. Noong Nobyembre ng parehong taon, naglabas kami ng isang bagong bersyon na may makabuluhang pagpapabuti sa backend (tulad ng inilarawan sa aming blog post: SeaVoice Discord Bot: Backend & Stability Improvements) na nagpapahintulot sa amin na mag-record ng anonymous na data kung paano nakikipag-ugnayan ang mga gumagamit sa SeaVoice bot. Sa aming huling blog (TTS Discord Bot Case Study) sinuri namin ang 1 buwan ng data ng gumagamit mula sa text-to-speech command. Bilang follow up, sa post na ito ay titingnan namin ang humigit-kumulang 3 linggo ng data ng gumagamit ng speech-to-text.
Paggamit ng SeaVoice STT
Sa oras ng pagsulat, ang SeaVoice Bot ay naidagdag sa halos 900 server! Humigit-kumulang 260 server na may kabuuang mahigit 600 kalahok ang aktwal na sumubok ng STT command kahit isang beses. Sa nakalipas na 3 linggo, nag-host kami ng halos 1,800 STT session at naglabas ng kabuuang mahigit kalahating milyong linya ng transkripsyon.
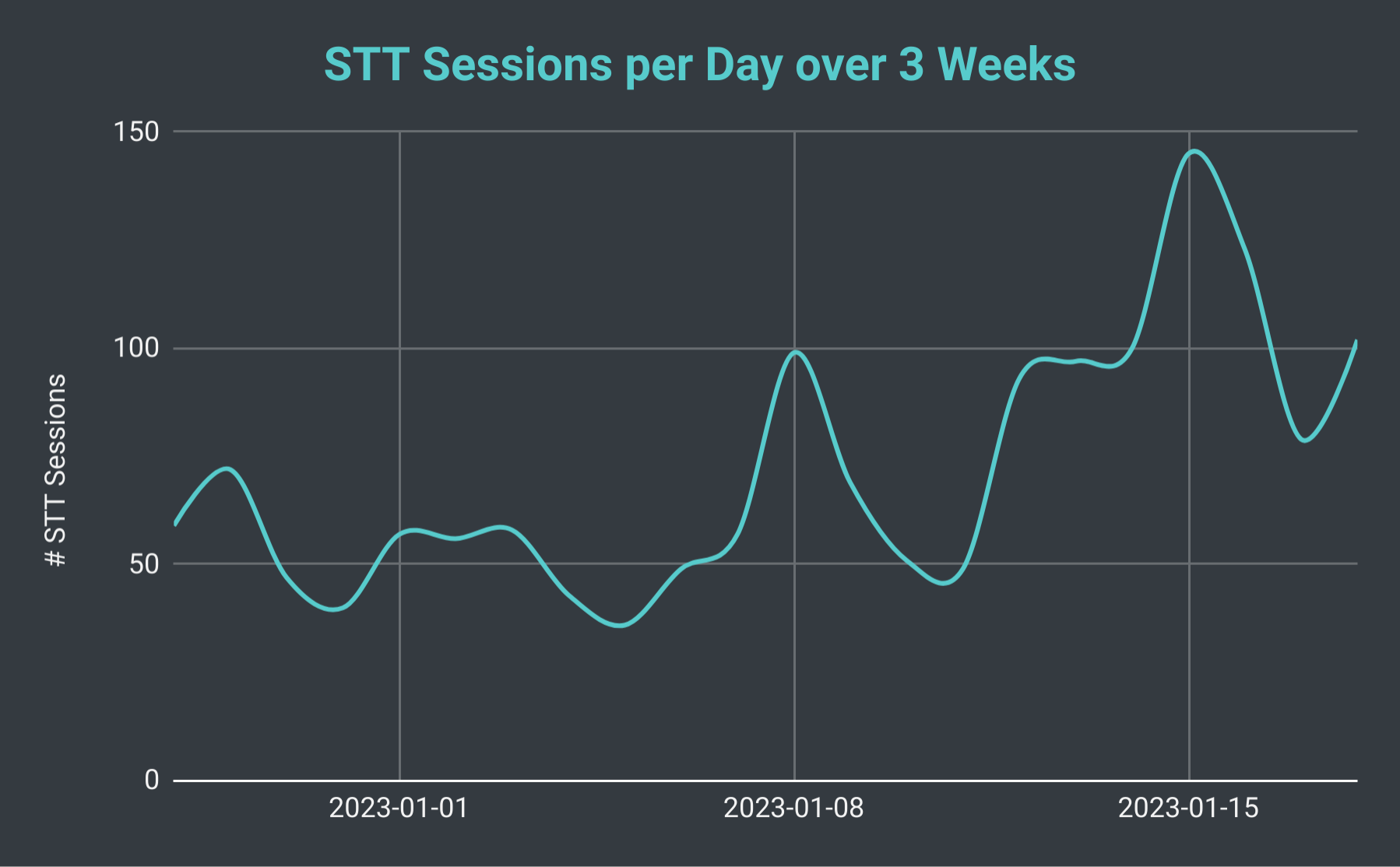
Pang-araw-araw na speech-to-text session ng SeaVoice Discord Bot sa loob ng 3 linggo.
Kung titingnan natin ang kabuuang bilang ng mga sesyon ng STT bawat araw, nalaman namin na maaari itong magbago mula sa kasing liit ng 40 hanggang sa mahigit 140 (na may average na humigit-kumulang 70). Maaari rin nating isaalang-alang ang kabuuang bilang ng mga linya ng transkripsyon na aming ginagawa. Sa pinakamabagal na araw, gumagawa kami ng kasing liit ng 10 libong linya, gayunpaman, sa isang abalang araw ay nakagawa kami ng mahigit 40 libong linya. Upang ilagay iyon sa perspektibo, noong Enero 18, nag-host kami ng 102 sesyon ng STT na may kabuuang bahagyang mas mababa sa 30 libong linya ng transkripsyon; na umabot sa halos 40 oras ng oras ng pag-record.
Nalaman din namin na habang ang karamihan sa mga sesyon ay ginagamit para sa mas maiikling pag-uusap (median ng 57 linya bawat sesyon), mayroong isang makabuluhang bilang ng napakahabang sesyon na nagpapataas ng average sa 650 linya bawat sesyon. Ang aming pinakamahabang sesyon ay mahigit 30 libong linya, higit pa sa halaga ng isang average na araw! Sa wakas, tiningnan din namin kung gaano karaming mga gumagamit ang may posibilidad na nasa bawat sesyon at nalaman namin na karaniwang mayroong 4 hanggang 5 gumagamit sa bawat sesyon - gayunpaman, minsan ay ginamit namin ang bot upang suportahan ang live na transkripsyon sa isang virtual na seminar na may 45 kalahok!
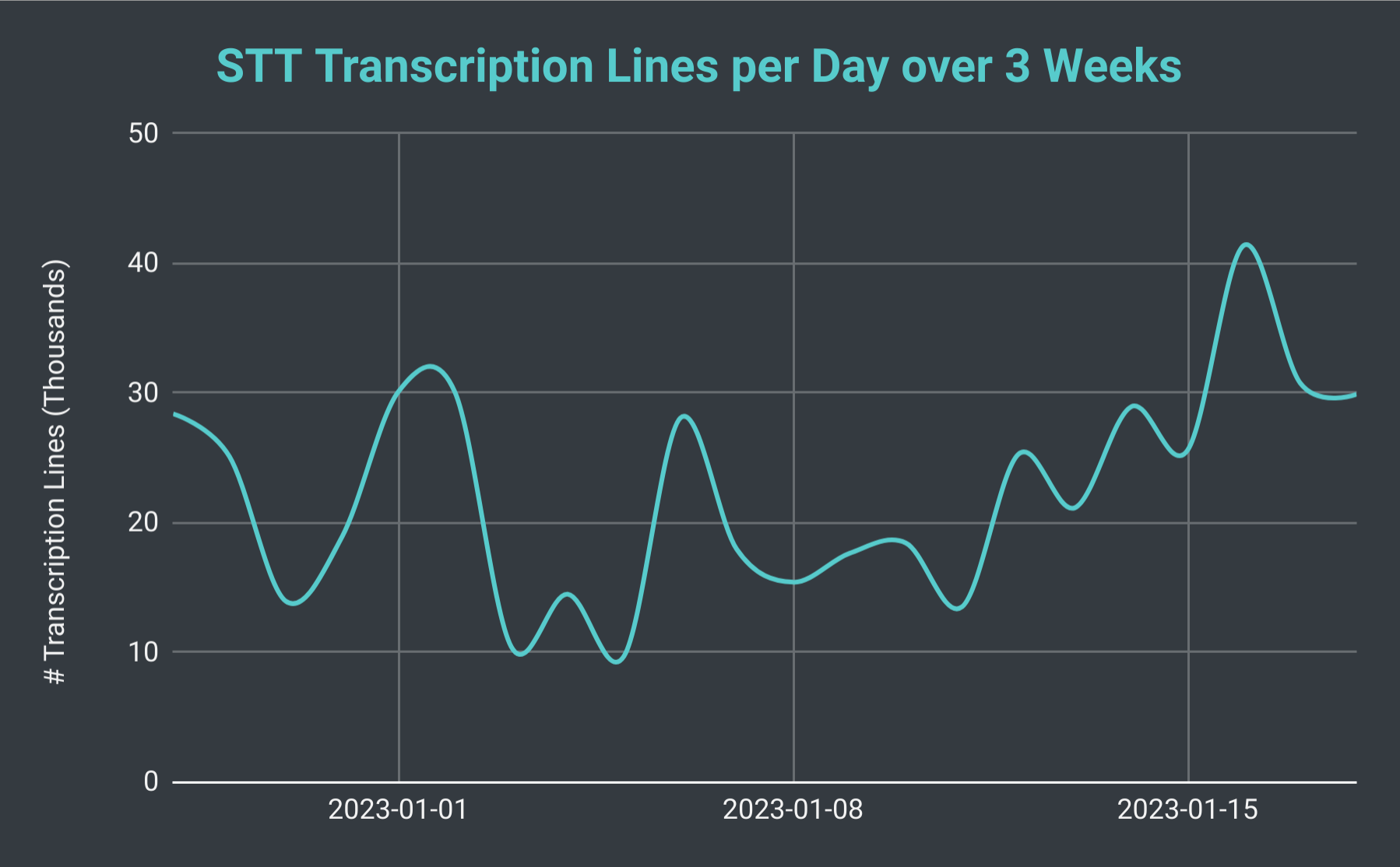
Mga linyang na-transcribe ng SeaVoice Discord Bot bawat araw sa loob ng 3 linggo.
Bagama’t hindi pa nagagamit ng karamihan sa mga server ang sesyon ng STT nang higit sa ilang beses, mayroon namang ilang gumagamit ng serbisyo nang malawakan. Mula nang simulan naming i-record ang data ng paggamit ng STT noong huling bahagi ng Disyembre, ang average na kabuuang bilang ng mga sesyon bawat server ay humigit-kumulang 7; gayunpaman, ang aming #1 server ay nag-log ng 131 sesyon - Iyon ay average na mahigit 6 na sesyon bawat araw! Ang parehong server ay nag-transcribe ng mahigit 150 libong linya ng pagsasalita sa loob lamang ng 3 linggo! Marahil mas kahanga-hanga pa kaysa doon, ang aming #1 user ay mula sa parehong server at nagkaroon ng mahigit 60 libong linya ng sarili niyang pagsasalita na na-transcribe!
Mga Obserbasyon
Bakit Gumagamit ang mga Tao ng Speech-to-Text

Isang gumagamit ng SeaVoice Discord bot ang nagpahayag ng kagalakan tungkol sa mga pinanatiling audio at transkripsyon na file.
Kaya ang aming unang tanong pagkatapos makita ang data ng paggamit ay: bakit ginagamit ng mga madalas na gumagamit ang speech-to-text sa unang lugar?
Sinuri namin ang database upang makahanap ng ilang paliwanag. Gayunpaman, mas mahirap makahanap ng konkretong paliwanag kung bakit ginagamit ng mga gumagamit ang serbisyo ng STT kumpara sa serbisyo ng TTS. Tila kailangan ng mga tao na ipaliwanag sa iba sa chat kung bakit sila gumagamit ng TTS, ngunit mas kaunti sa STT. Gayunpaman, nakahanap ako ng ilang kawili-wiling transkripsyon na nagbigay ng ilang insight kung bakit nagpasya ang mga gumagamit na gamitin ang serbisyo ng STT.
Bakit ginagamit ng mga gumagamit ang STT:
- “Ito ang dahilan kung bakit ginagamit ang transkripsyon dahil makikita ko ang mga bagay na namiss ko.”
- “[user] ay may problema sa pandinig, kaya nakakakuha siya ng bot na nagta-transcribe nito”
- “[user] ay nagre-raid kasama nila at ginagamit nila ito upang mag-transcribe ng mga bagay, ngunit pagkatapos ay sinabi ni [user], oh, maaari rin nating gamitin iyon para sa ******* D at D stuff”
- “Hindi ako makapaghintay na balikan at basahin ang ilan sa mga transkripsyon na ito mamaya […] Gusto kong pakinggan ang recording na iyon at tingnan muli ang transkripsyon na iyon”
- “Kung mayroon tayong mga pulong dito, maaari nating ipasok ang transkripsyon ng pulong sa AI”
- “Sa panahon ng isang pulong sa mga tao, napakagandang makita ang isang transkripsyon”
- “[mga tao] na wala sa chat o mga tao na nasa komunidad, ngunit hindi bahagi ng voice chat, ngunit nagpasya silang tumingin at magbasa”
Kaya sa pangkalahatan, tila karamihan sa mga gumagamit ay nasisiyahan sa kaginhawaan ng pagkakaroon ng live na transkripsyon na makakatulong sa kanila na subaybayan ang pag-uusap at punan ang anumang mga puwang na namiss nila. Ito ay partikular na totoo para sa mga gumagamit na may kapansanan sa pandinig o mga problema sa audio/koneksyon. Para sa ilang mga gumagamit ang pinakamalaking benepisyo ay ang pagpapanatili ng isang permanenteng audio at text record ng kanilang pag-uusap; ito ay maaaring partikular na naaangkop para sa mga kaso ng paggamit tulad ng pagpapanatili ng isang Dungeons & Dragons session log o pagpapanatili ng record ng mahahalagang pulong.
Dahil maraming gumagamit ang hindi malinaw na nagsabi kung bakit nila ginagamit ang serbisyo ng STT, tila kapaki-pakinabang din na malaman kung ano ang kanilang ginagawa habang ginagamit ang bot. Ang pagsusuri sa mga transkripsyon mula sa mga gumagamit ay nagbigay sa akin ng mga pahiwatig kung anong mga aktibidad ang kanilang ginagawa habang nagta-transcribe:
Ano ang ginagawa ng mga gumagamit habang ginagamit ang STT:
- Nagcha-chat lang
- Paglalaro:
- Kaswal na paglalaro
- Advanced na paglalaro (hal. pag-coordinate ng grupo ng MMO, Massive Multiplayer Online, raids)
- Role playing games (Dungeons & Dragons)
- Streaming / pag-record ng nilalaman
- Pagtalakay sa trabaho sa paaralan / propesyonal / boluntaryo
Ang napakaraming transkripsyon ay nahuhulog sa mga kategoryang “nagcha-chat lang” at “kaswal na paglalaro”. Tulad ng nakita natin sa itaas, sa tingin ko karamihan sa mga gumagamit sa kasong ito ay ginagamit ang bot upang mapabuti ang accessibility ng Discord voice channel at/o nasisiyahan sa kaginhawaan ng pagtingin sa live na transkripsyon upang punan ang anumang mga puwang na namiss nila sa pag-uusap. Sa ilang mga kaso (tulad ng kapag ginamit para sa mga MMO raid), ang mga talakayan sa paglalaro ay napakakumplikado at ang mga gumagamit ay nagko-coordinate sa isa’t isa sa real-time; ang mga live na transkripsyon ay maaaring maging lubhang kapaki-pakinabang sa tagumpay ng koponan dahil ang mga gumagamit ay maaaring sumangguni sa mga transkripsyon habang sila ay naglalaro.
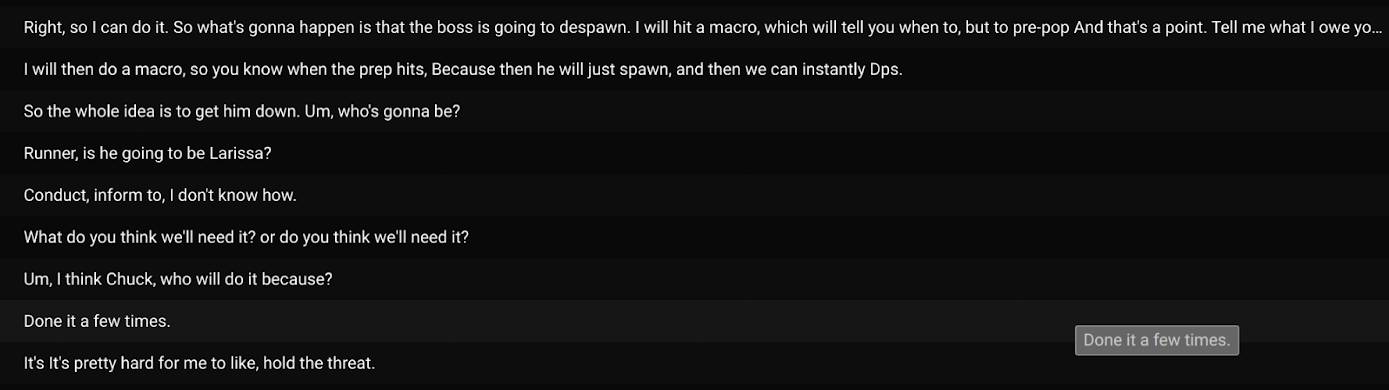
Halimbawa ng kumplikadong talakayan sa panahon ng isang MMO raid.
Mukhang marami ring gumagamit ang gumagamit ng bot upang mag-transcribe ng mas seryosong pag-uusap tulad ng mga pulong sa paaralan, propesyonal at/o boluntaryong komunidad. Ginamit din namin ang aming bot upang mag-transcribe ng isang online tech conference, UnTechCon. Sa mga kasong ito, ang huling recording at transkripsyon na file ay maaaring maging napakalaking tulong sa mga gumagamit para sa pagsusuri pagkatapos ng pulong. Ang isa pang kawili-wiling halimbawa na nakita ko ay isang gumagamit na nagre-record ng nilalaman para sa kanilang stream. Dahil ang huling transkripsyon ay may kasamang timestamps, maaaring i-upload ng mga gumagamit ang transkripsyon file bilang mga subtitle para sa kanilang na-record na audio o video content.
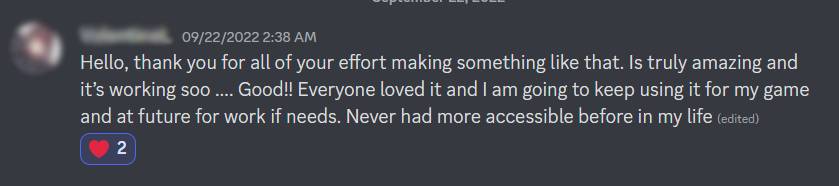
Isang gumagamit ng SeaVoice ang nagpahayag ng pasasalamat sa paggawa ng mga voice channel ng Discord na mas accessible.
Ngunit anuman ang eksaktong dahilan kung bakit nila ginagamit ang serbisyo ng STT, maraming gumagamit ang nagpahayag ng kagalakan na nakapag-partisipate sila sa mga pag-uusap sa voice channel kung hindi man ay hindi nila magagawa. Naniniwala kami na ginagawang mas accessible ng serbisyo ng STT ang mga voice channel ng Discord, at iyon ang pangunahing dahilan kung bakit patuloy na ginagamit ng aming mga regular na gumagamit ang serbisyo.
Komentaryo tungkol sa SeaVoice Discord Bot
Ang isa pang kawili-wiling paksa na natagpuan sa mga log ay ang komentaryo tungkol sa bot mismo. Sa kabutihang palad, nakita namin ang ilang napakapositibong komento tungkol sa bot at sa pagganap nito.

Isang gumagamit ng SeaVoice ang nagkomento sa katumpakan ng transkripsyon.
Nakahanap din kami ng ilang piraso ng nakabubuo na feedback.

Isang gumagamit ng SeaVoice ang nagmungkahi ng pagpapabuti para sa mga British accent.

Isang gumagamit ang naghahambing sa pagganap ng SeaVoice sa accented English sa Siri.
Karamihan sa mga nakabubuo na komento ay may kinalaman sa hindi magandang pagganap ng bot sa Ingles na may di-Amerikanong accent; partikular na binanggit ng mga gumagamit ang mga British at Scottish accent. Para sa hinaharap ng aming mga serbisyo ng STT, maaari kaming maglagay ng malaking pagsisikap sa pagpapabuti ng aming speech recognition para sa iba’t ibang accent ng Ingles. Siyempre, hindi lang Ingles ang wika na sinasalita ng aming mga gumagamit, kaya plano rin naming magdagdag ng mas maraming suporta sa wika sa bot. Sa katunayan, kasalukuyan naming tinatapos ang aming Taiwanese Mandarin STT at TTS integrations, at maglalabas kami ng updated na bersyon ng bot sa lalong madaling panahon.
Privacy, Data Sensitivity, & Potentially Offensive Content
Ang pagbuo ng AI ay napapalibutan ng maraming etikal na dilema. Ang aming mga modelo ay nangangailangan ng napakalaking dami ng tunay na data ng gumagamit upang gumana nang maayos, ngunit paano namin kokolektahin ang data na iyon nang etikal habang iginagalang ang privacy ng aming mga gumagamit? Ang mga modelo ay natututo lamang batay sa data na ibinigay sa kanila at samakatuwid ay may (potensyal na hindi inaasahang) mga bias; kaya paano namin masisiguro na ang aming mga modelo ay pantay na mahusay na naglilingkod sa lahat ng aming mga gumagamit? Bukod pa rito, ang aming mga modelo ay walang konsepto ng pagtanggap sa lipunan at maaaring makagawa ng mga resulta na sa tingin ng ilang gumagamit ay nakakasakit. Tulad ng sinabi ng isa sa aming mga gumagamit nang napakalinaw: “Racist ba kung ang bot ang gumawa, iyon ang tanong”.

Isang gumagamit ng SeaVoice ang nagtuturo ng isang problematikong hindi tumpak na transkripsyon.
Ang dahilan kung bakit ko binabanggit ang mga puntong ito ay dahil sa ilang nakababahalang transkripsyon sa mga log. Ang unang isyu ay ang bot ay paminsan-minsan ay nagta-transcribe ng nakakasakit na nilalaman. Sa halimbawa sa itaas, aksidenteng na-transcribe ng bot ang username ng isang tao bilang isang racial slur. Malinaw na ito ay isang error sa panig ng bot na maaaring makasakit sa aming mga gumagamit at dapat imbestigahan. Ngunit ito ay humahantong sa mas maraming tanong: saan natin ilalagay ang linya sa pagitan ng pagkakasala at pinsala?

Isang gumagamit ng SeaVoice ang nagkomento sa pagsubok na i-censor ang ilang mga salita mula sa transkripsyon.
Well, para magsimula, nagpasya kaming ibigay ang kapangyarihang iyon sa mga gumagamit. Isa sa mga susunod na feature na gagawin namin ay ang configurable censorship ng TTS at STT. Ito ay magpapahintulot sa mga server na opsyonal na mag-apply ng mga censor para sa mga mura, sexual content, racial slurs, atbp.

Isang gumagamit ng SeaVoice ang nagbabala sa isa pang kalahok na maging maingat na ang kanilang sasabihin ay mapupunta sa transkripsyon.
Kapansin-pansin, isa pang kaugnay na isyu na nakita namin ay ang mga gumagamit na nagse-self-censor upang maiwasan ang ilang mga bagay na lumabas sa transkripsyon. Ito ay nakakagulat na karaniwan, at nakita ko ang maraming kaso kung saan ipinaliwanag ng mga gumagamit na ayaw nilang i-transcribe ng bot ang sasabihin nila kaya huminto sila at pagkatapos ay muling sinimulan ang STT. Ito ay isang ganap na balidong alalahanin sa panig ng gumagamit kung halimbawa ayaw nilang i-transcribe ng bot ang ilang sensitibong impormasyon.
Paano i-pause ang STT sa pamamagitan ng pagpapatahimik sa bot.
Hindi ako sigurado kung mayroon kaming anumang paraan upang mapabuti ang karanasan ng gumagamit sa kasong ito, ngunit ipinapayo ko sa mga gumagamit na maaari nilang “patahimikin” ang bot pansamantala upang ihinto ang pagpapadala ng anumang audio sa bot. Sa kasong ito, ang bot ay makakatanggap ng zero audio data hanggang sa ito ay ma-un-deafen, kaya ang gumagamit ay maaaring i-pause ang STT session nang hindi humihinto at nagsisimula ng bago.

Isang gumagamit ng SeaVoice ang nagkomento sa pagkadismaya ng isa pang kalahok sa bot.
Sa wakas, ang huling isyu na nakita namin ay ang ilang mga gumagamit ay labis na hindi komportable sa pagta-transcribe ng bot kaya aktibo silang umiiwas sa pagsasalita sa voice channel habang naroroon ang bot. Ito ay ang ganap na kabaligtaran ng aming layunin, na gawing mas accessible ang mga voice channel ng Discord para sa lahat. Bagama’t umaasa kami na tatanggapin ng mga gumagamit ang aming patakaran sa privacy at magtitiwala sa amin na gamitin ang kanilang data nang responsable, lubos naming iginagalang ang karapatan ng bawat isa sa privacy. Dahil dito, ang susunod na feature na ipapatupad namin ay isang setting ng STT opt-out. Ito ay magpapahintulot sa sinumang gumagamit na ibukod ang kanilang sarili mula sa pag-record at transkripsyon ng STT, at ang kanilang data ng audio ay hindi maa-access o kokolektahin sa anumang paraan ng bot.
Umaasa kami na ang mga nakaplanong feature na ito ay magpapahintulot sa amin na patuloy na gawing mas accessible ang mga voice channel para sa lahat habang binibigyan ang mga gumagamit ng kakayahang makipag-ugnayan sa SeaVoice Bot sa antas na komportable sila. Sa hinaharap, patuloy kaming magsisikap na proaktibong tugunan ang mga mapaghamong isyung ito upang gawing pinakamahusay ang SeaVoice!
Salamat sa iyong interes sa aming Discord Bot at salamat sa aming mga gumagamit para sa iyong patuloy na suporta! Maaari kang matuto nang higit pa tungkol sa aming produkto ng STT sa aming SeaVoice Speech-to-Text Homepage. Para sa isang one-on-one demo ng alinman sa aming mga produkto ng Voice Intelligence, punan ang Book a Demo Form.
Kung hindi mo pa nasubukan ang SeaVoice bot, maaari kang matuto nang higit pa tungkol sa aming bot at idagdag ito sa iyong server mula sa SeaVoice Discord Bot Wiki. Huwag mag-atubiling sumali sa aming Official SeaVoice Discord Server.


