





Nach dem Start von SeaVoice, einem der schnellsten und genauesten Text-zu-Sprache- und Sprache-zu-Text-Bots auf Discord, wollten wir verstehen, wie Benutzer tatsächlich mit den Diensten interagierten. In diesem Blog werden wir unsere Erkenntnisse nach der Überprüfung mehrerer Wochen realer Sprache-zu-Text-Benutzerdaten diskutieren.
SeaVoice: Ein Text-zu-Sprache- & Sprache-zu-Text-Discord-Bot
Discord, als Plattform, die hauptsächlich für eine Kombination aus Audio- und Text-basiertem Chat verwendet wird, ist ein fantastisches Testgelände für Sprachintelligenz- und natürliche Sprachverarbeitungsdienste. Wir haben den SeaVoice Bot, ausgestattet mit Text-zu-Sprache- und Sprache-zu-Text-Befehlen, im August 2022 auf Discord bereitgestellt. Um mehr darüber zu erfahren, wie der Bot funktioniert, oder ein kurzes Video-Demo zu sehen, können Sie das SeaVoice Bot Wiki besuchen. Im November desselben Jahres veröffentlichten wir eine neue Version mit signifikanten Backend-Verbesserungen (wie in unserem Blogbeitrag beschrieben: SeaVoice Discord Bot: Backend- & Stabilitätsverbesserungen), die es uns ermöglichen, anonyme Daten darüber aufzuzeichnen, wie Benutzer mit dem SeaVoice Bot interagieren. In unserem letzten Blog (TTS Discord Bot Fallstudie) analysierten wir 1 Monat Benutzerdaten aus dem Text-zu-Sprache-Befehl. Als Fortsetzung werden wir in diesem Beitrag etwa 3 Wochen Sprache-zu-Text-Benutzerdaten betrachten.
SeaVoice STT-Nutzung
Zum Zeitpunkt des Schreibens wurde der SeaVoice Bot zu fast 900 Servern hinzugefügt! Etwa 260 Server mit insgesamt über 600 Teilnehmern haben den STT-Befehl tatsächlich mindestens einmal ausprobiert. In den letzten 3 Wochen haben wir fast 1.800 STT-Sitzungen veranstaltet und insgesamt über eine halbe Million Transkriptionszeilen ausgegeben.
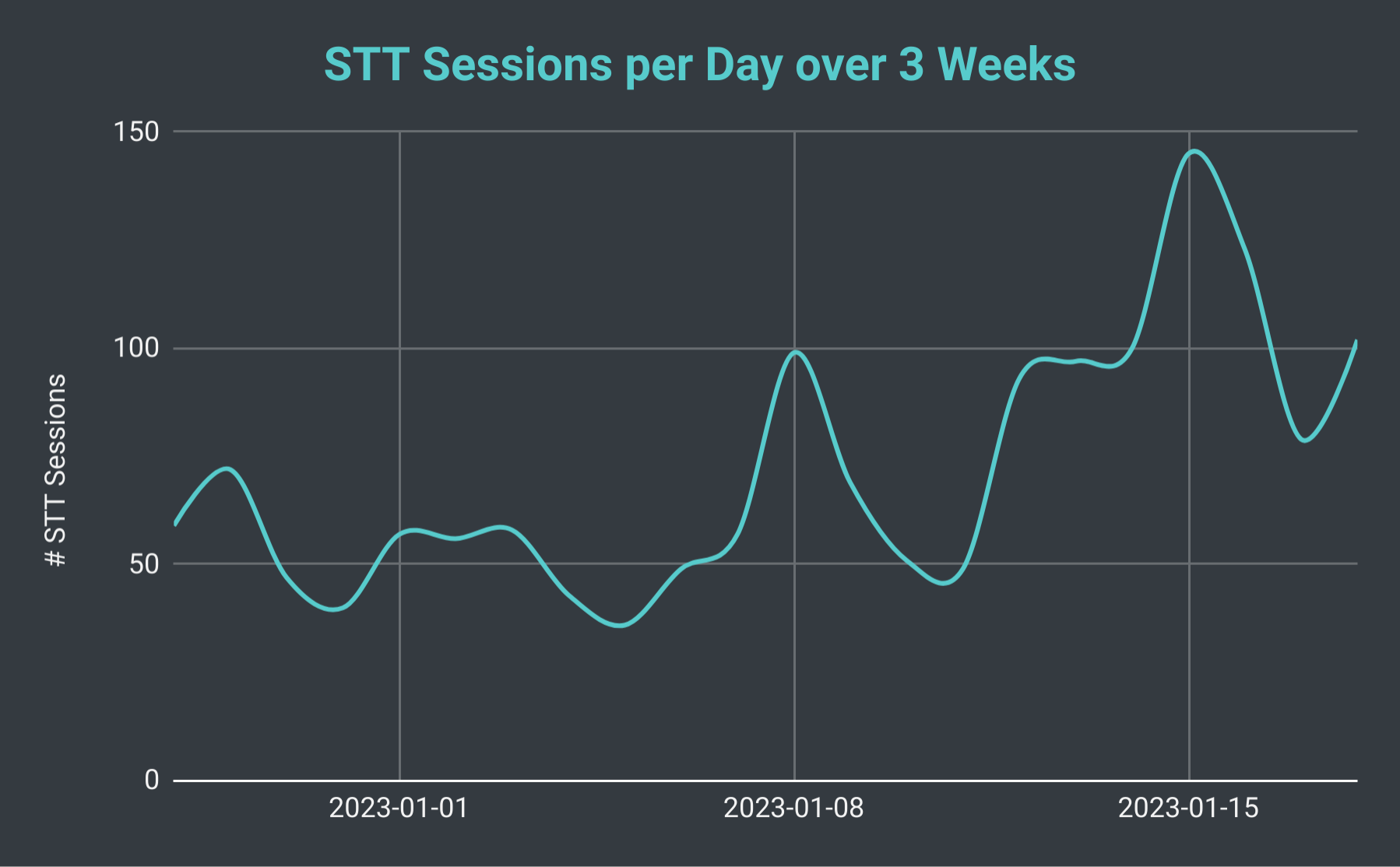
Tägliche Sprache-zu-Text-Sitzungen des SeaVoice Discord Bots über 3 Wochen.
Wenn wir die Gesamtzahl der STT-Sitzungen pro Tag betrachten, haben wir festgestellt, dass sie von nur 40 bis über 140 schwanken kann (mit einem Durchschnitt von etwa 70). Wir können auch die Gesamtzahl der von uns produzierten Transkriptionszeilen berücksichtigen. Am langsamsten Tag produzieren wir nur 10 Tausend Zeilen, an einem geschäftigen Tag haben wir jedoch über 40 Tausend Zeilen produziert. Um das ins rechte Licht zu rücken: Am 18. Januar veranstalteten wir 102 STT-Sitzungen mit insgesamt knapp 30 Tausend Transkriptionszeilen; das entsprach fast 40 Stunden Aufnahmezeit.
Wir fanden auch heraus, dass die meisten Sitzungen für kürzere Gespräche verwendet werden (Median von 57 Zeilen pro Sitzung), es aber eine beträchtliche Anzahl sehr langer Sitzungen gibt, die den Durchschnitt auf 650 Zeilen pro Sitzung erhöhen. Unsere längste Sitzung war über 30 Tausend Zeilen lang, mehr als ein durchschnittlicher Tageswert! Schließlich haben wir uns auch angesehen, wie viele Benutzer tendenziell in jeder Sitzung sind, und festgestellt, dass es typischerweise 4 bis 5 Benutzer in jeder Sitzung gibt - wir haben den Bot jedoch einmal verwendet, um die Live-Transkription bei einem virtuellen Seminar zu unterstützen, an dem 45 Teilnehmer teilnahmen!
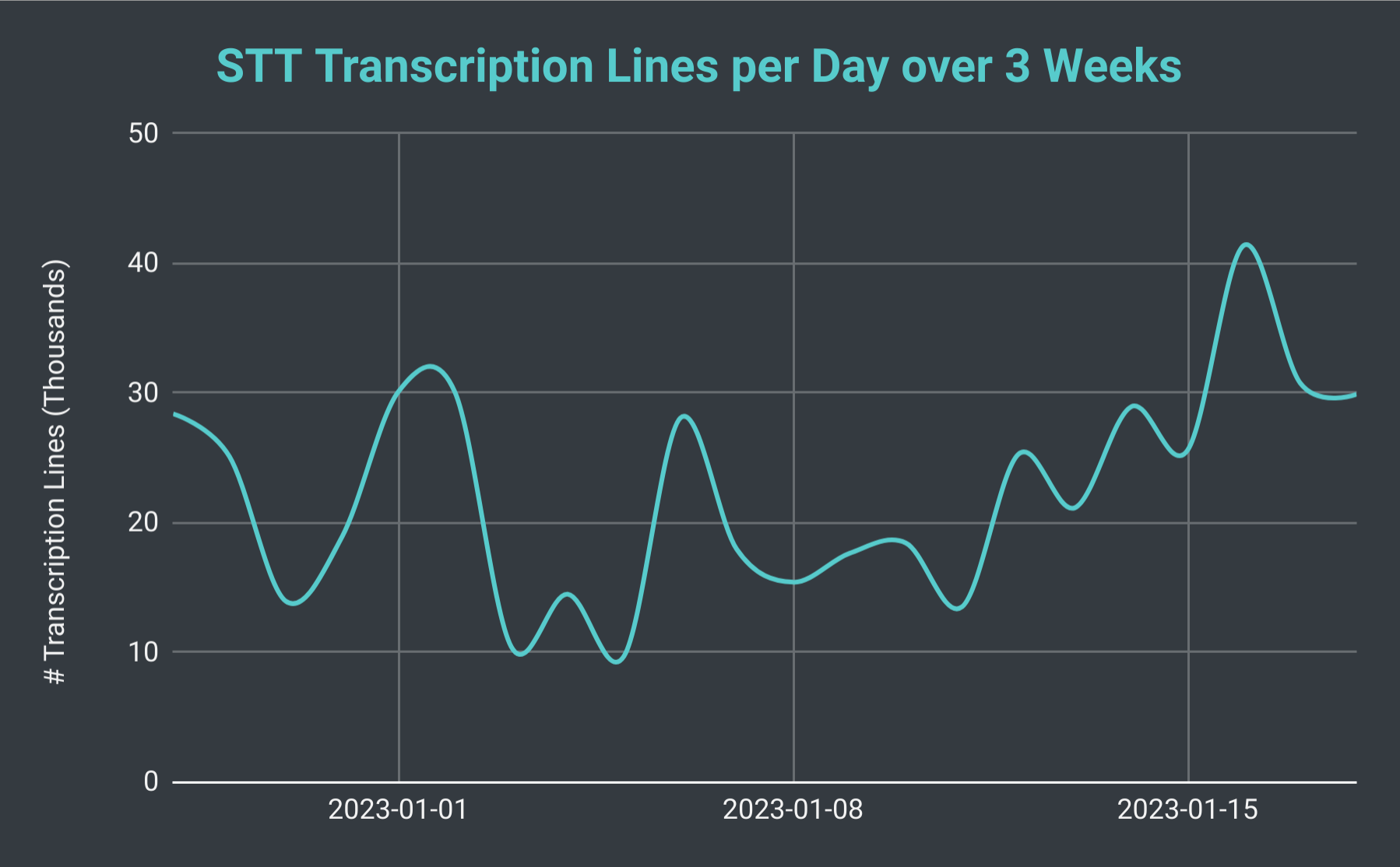
Vom SeaVoice Discord Bot pro Tag transkribierte Zeilen über 3 Wochen.
Während die Mehrheit der Server die STT-Sitzung nicht mehr als ein paar Mal genutzt hat, gibt es doch einige, die den Dienst ausgiebig nutzen. Seit wir Ende Dezember mit der Aufzeichnung der STT-Nutzungsdaten begonnen haben, beträgt die durchschnittliche Gesamtzahl der Sitzungen pro Server etwa 7; unser Server Nr. 1 hat jedoch 131 Sitzungen protokolliert - das sind durchschnittlich über 6 Sitzungen pro Tag! Derselbe Server hat in nur 3 Wochen über 150 Tausend Zeilen Sprache transkribiert! Vielleicht noch beeindruckender ist, dass unser Benutzer Nr. 1 vom selben Server stammt und über 60 Tausend Zeilen seiner eigenen Sprache transkribiert hat!
Beobachtungen
Warum Menschen Sprache-zu-Text verwenden

Ein SeaVoice Discord Bot-Benutzer drückt seine Begeisterung über die persistenten Audio- und Transkriptionsdateien aus.
Unsere erste Frage nach dem Betrachten der Nutzungsdaten lautet also: Warum nutzen die häufigen Benutzer überhaupt Sprache-zu-Text?
Wir haben die Datenbank durchsucht, um einige Erklärungen zu finden. Es erwies sich jedoch als schwieriger, konkrete Erklärungen dafür zu finden, warum Benutzer den STT-Dienst im Gegensatz zum TTS-Dienst nutzten. Anscheinend fühlen sich die Leute verpflichtet, den anderen im Chat zu erklären, warum sie TTS verwenden, aber weniger bei STT. Unabhängig davon fand ich einige interessante Transkriptionen, die einen Einblick gaben, warum Benutzer sich für die Nutzung des STT-Dienstes entscheiden.
Warum Benutzer STT nutzen:
- „Deshalb wird das Transkript verwendet, weil ich Dinge sehen kann, die ich verpasst habe.“
- „[Benutzer] ist schwerhörig, also bekommt er einen Bot, der es transkribiert“
- „[Benutzer] raidet mit ihnen und sie benutzen es, um Dinge zu transkribieren, aber dann sagte [Benutzer], oh, wir können das auch für ******* D und D-Sachen verwenden“
- „Ich kann es kaum erwarten, später zurückzukehren und einige dieser Transkripte zu lesen […] Ich möchte mir diese Aufnahme noch einmal anhören und dieses Transkript noch einmal ansehen“
- „Wenn wir unsere Meetings hier haben, können wir das Transkript des Meetings in die KI einspeisen“
- „Während eines Meetings mit Leuten ist es großartig, tatsächlich ein Transkript zu sehen“
- „[Leute], die nicht im Chat sind oder Leute, die in der Community sind, aber nicht Teil des Voice-Chats, aber sie entscheiden sich, zu schauen und zu lesen“
Im Allgemeinen scheint es also, dass die meisten Benutzer die Bequemlichkeit einer Live-Transkription genießen, die ihnen helfen kann, den Überblick über das Gespräch zu behalten und alle Lücken zu füllen, die sie verpasst haben. Dies gilt insbesondere für Benutzer mit Hörbehinderung oder Audio-/Verbindungsschwierigkeiten. Für einige Benutzer ist der größte Vorteil die dauerhafte Audio- und Textaufzeichnung ihrer Konversation; dies könnte besonders für Anwendungsfälle wie die Führung eines Dungeons & Dragons-Sitzungsprotokolls oder die Aufzeichnung wichtiger Besprechungen relevant sein.
Da viele Benutzer nicht explizit angaben, warum sie den STT-Dienst nutzten, schien es auch nützlich zu sein, ein Gefühl dafür zu bekommen, was sie taten, während sie den Bot nutzten. Die Überprüfung der Transkriptionen von Benutzern gab mir Hinweise darauf, welche Aktivitäten sie während der Transkription ausführten:
Was Benutzer tun, während sie STT nutzen:
- Einfach chatten
- Gaming:
- Gelegenheitsspiele
- Fortgeschrittene Spiele (z.B. Koordination von Gruppen-MMO, Massive Multiplayer Online, Raids)
- Rollenspiele (Dungeons & Dragons)
- Streaming / Aufzeichnung von Inhalten
- Diskussionen über Schul-/Berufs-/Freiwilligenarbeit
Die überwiegende Mehrheit der Transkriptionen fällt in die Kategorien „einfach chatten“ und „Gelegenheitsspiele“. Wie wir oben gesehen haben, denke ich, dass die meisten Benutzer in diesem Fall den Bot nutzen, um die Zugänglichkeit des Discord-Sprachkanals zu verbessern und/oder die Bequemlichkeit zu genießen, die Live-Transkription zu sehen, um alle Lücken zu füllen, die sie im Gespräch verpasst haben. In einigen Fällen (wie bei MMO-Raids) sind die Gaming-Diskussionen sehr komplex und Benutzer koordinieren sich in Echtzeit; Live-Transkriptionen könnten sich als äußerst nützlich für den Erfolg des Teams erweisen, da Benutzer die Transkripte während des Spiels referenzieren können.
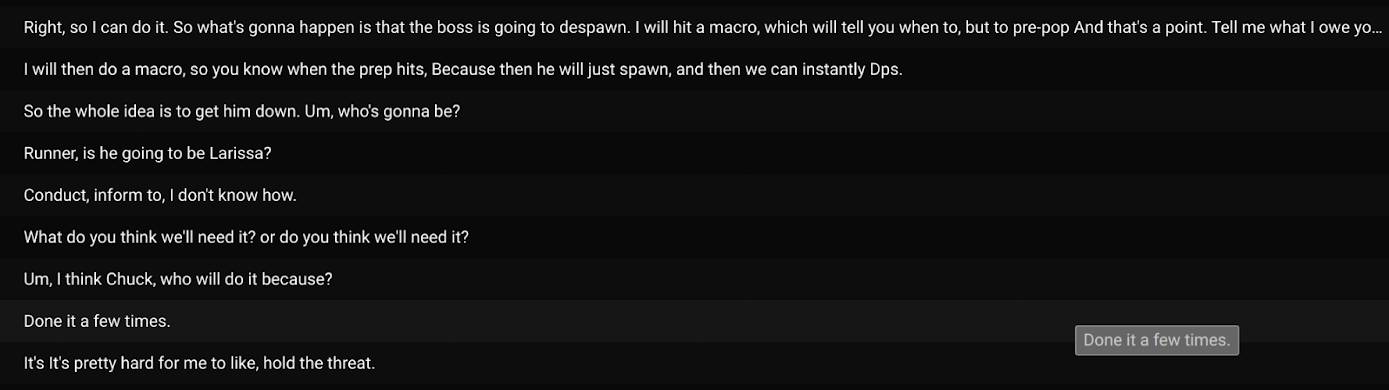
Beispiel einer komplexen Diskussion während eines MMO-Raids.
Es scheint auch, dass viele Benutzer den Bot verwenden, um ernsthaftere Gespräche wie Schul-, Berufs- und/oder Freiwilligen-Community-Meetings zu transkribieren. Wir haben unseren Bot auch verwendet, um eine Online-Tech-Konferenz, UnTechCon, zu transkribieren. In diesen Fällen können die endgültigen Aufnahme- und Transkriptionsdateien für Benutzer nach dem Meeting sehr hilfreich sein. Ein letztes interessantes Beispiel, das ich gefunden habe, war ein Benutzer, der Inhalte für seinen Stream aufzeichnete. Da das endgültige Transkript Zeitstempel enthält, könnten Benutzer die Transkriptionsdatei möglicherweise als Untertitel für ihre aufgezeichneten Audio- oder Videoinhalte hochladen.
Ein SeaVoice-Benutzer bedankt sich dafür, dass Discord-Sprachkanäle zugänglicher gemacht wurden.
Unabhängig vom genauen Grund, warum sie den STT-Dienst nutzen, äußerten viele Benutzer ihre Begeisterung darüber, dass sie an den Sprachkanal-Gesprächen teilnehmen konnten, obwohl sie es sonst nicht könnten. Wir glauben, dass der STT-Dienst Discord-Sprachkanäle zugänglicher macht, und das ist der Hauptgrund, warum unsere Stammbenutzer den Dienst weiterhin nutzen.
Kommentare zum SeaVoice Discord Bot
Ein weiteres interessantes Thema, das in den Protokollen gefunden wurde, waren Kommentare zum Bot selbst. Glücklicherweise sahen wir mehrere sehr positive Kommentare zum Bot und seiner Leistung.

Ein SeaVoice-Benutzer kommentiert die Transkriptionsgenauigkeit.
Wir fanden auch einige konstruktive Rückmeldungen.

Ein SeaVoice-Benutzer schlägt Verbesserungen für britische Akzente vor.

Ein Benutzer vergleicht die Leistung von SeaVoice bei akzentuiertem Englisch mit der von Siri.
Die meisten konstruktiven Kommentare bezogen sich darauf, dass der Bot bei nicht-amerikanischem Englisch mit Akzent nicht gut funktionierte; insbesondere Benutzer erwähnten britische und schottische Akzente. Für die Zukunft unserer STT-Dienste könnten wir erhebliche Anstrengungen unternehmen, um unsere Spracherkennung für verschiedene englische Akzente zu verbessern. Natürlich ist Englisch nicht die einzige Sprache, die unsere Benutzer sprechen, daher planen wir auch, dem Bot mehr Sprachunterstützung hinzuzufügen. Tatsächlich finalisieren wir derzeit unsere taiwanesischen Mandarin-STT- und TTS-Integrationen und werden in Kürze eine aktualisierte Version des Bots veröffentlichen.
Datenschutz, Datensensibilität und potenziell beleidigende Inhalte
Die Entwicklung von KI ist von einer Flut ethischer Dilemmata umgeben. Unsere Modelle benötigen massive Mengen an realen Benutzerdaten, um gut zu funktionieren, aber wie sammeln wir diese Daten ethisch, während wir die Privatsphäre unserer Benutzer respektieren? Modelle lernen nur auf der Grundlage der ihnen zur Verfügung gestellten Daten und haben daher (potenziell unvorhergesehene) Vorurteile; wie können wir also sicherstellen, dass unsere Modelle allen unseren Benutzern gleichermaßen gut dienen? Darüber hinaus haben unsere Modelle kein Konzept der sozialen Akzeptanz und können Ergebnisse liefern, die einige Benutzer als beleidigend empfinden. Wie es einer unserer Benutzer so eloquent formulierte: „Ist es rassistisch, wenn der Bot es tut, das ist die Frage“.

Ein SeaVoice-Benutzer weist auf eine problematische ungenaue Transkription hin.
Der Grund, warum ich diese Punkte anspreche, sind einige besorgniserregende Transkriptionen in den Protokollen. Das erste Problem ist, dass der Bot gelegentlich beleidigende Inhalte transkribiert. Im obigen Beispiel transkribierte der Bot versehentlich den Benutzernamen einer Person als rassistische Beleidigung. Offensichtlich ist dies ein Fehler auf Seiten des Bots, der unsere Benutzer beleidigen könnte und untersucht werden sollte. Aber das führt zu weiteren Fragen: Wo ziehen wir die Grenze zwischen Beleidigung und Schaden?

Ein SeaVoice-Benutzer kommentiert den Versuch, bestimmte Wörter aus der Transkription zu zensieren.
Nun, zunächst haben wir beschlossen, diese Macht den Benutzern zu geben. Eine der nächsten Funktionen, an denen wir arbeiten werden, ist die konfigurierbare Zensur von TTS und STT. Dies wird es Servern ermöglichen, optional Zensuren für Schimpfwörter, sexuelle Inhalte, rassistische Beleidigungen usw. anzuwenden.

Ein SeaVoice-Benutzer warnt einen anderen Teilnehmer, sich bewusst zu sein, dass das, was sie sagen, im Transkript landen wird.
Interessanterweise war ein weiteres verwandtes Problem, das wir sahen, dass Benutzer sich selbst zensierten, um zu vermeiden, dass bestimmte Dinge im Transkript erscheinen. Dies war überraschend häufig, und ich sah viele Fälle, in denen Benutzer erklärten, dass sie nicht wollten, dass der Bot transkribiert, was sie sagen wollten, also hielten sie an und starteten dann den STT neu. Dies ist eine völlig berechtigte Sorge des Benutzers, wenn er beispielsweise nicht möchte, dass der Bot sensible Informationen transkribiert.
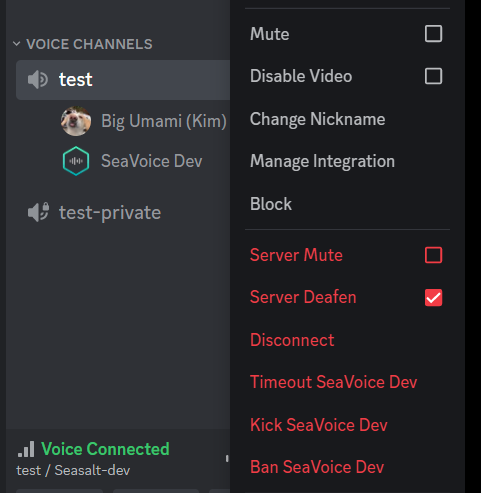
So pausieren Sie STT, indem Sie den Bot taub schalten.
Ich bin mir nicht sicher, ob wir in diesem Fall die Benutzererfahrung verbessern können, aber ich würde Benutzern raten, den Bot vorübergehend „taub zu schalten“, um das Senden von Audio an den Bot zu stoppen. In diesem Fall erhält der Bot keine Audiodaten, bis er wieder „enttaubt“ wird, sodass der Benutzer die STT-Sitzung im Wesentlichen pausieren kann, ohne eine neue zu stoppen und zu starten.

Ein SeaVoice-Benutzer kommentiert das Unbehagen eines anderen Teilnehmers mit dem Bot.
Schließlich ist das letzte Problem, das wir sahen, dass sich einige Benutzer so unwohl fühlen, wenn der Bot transkribiert, dass sie aktiv vermeiden, im Sprachkanal zu sprechen, während der Bot anwesend ist. Dies ist das genaue Gegenteil unseres Ziels, nämlich Discord-Sprachkanäle für alle zugänglicher zu machen. Obwohl wir hoffen, dass Benutzer unsere Datenschutzrichtlinie akzeptieren und uns vertrauen, ihre Daten verantwortungsvoll zu verwenden, respektieren wir absolut das Recht jedes Einzelnen auf Privatsphäre. Daher wird die nächste Funktion, die wir implementieren werden, eine STT-Opt-out-Einstellung sein. Dies ermöglicht es jedem Benutzer, sich von der STT-Aufzeichnung und -Transkription auszuschließen, und seine Audiodaten werden vom Bot in keiner Weise abgerufen oder gesammelt.
Wir hoffen, dass diese geplanten Funktionen es uns ermöglichen werden, Sprachkanäle für alle zugänglicher zu machen, während wir den Benutzern die Möglichkeit geben, mit dem SeaVoice Bot auf einem Niveau zu interagieren, mit dem sie sich wohlfühlen. Wir werden uns weiterhin bemühen, diese herausfordernden Probleme proaktiv anzugehen, um SeaVoice so gut wie möglich zu machen!
Vielen Dank für Ihr Interesse an unserem Discord Bot und vielen Dank an unsere Benutzer für Ihre anhaltende Unterstützung! Weitere Informationen zu unserem STT-Produkt finden Sie auf unserer SeaVoice Speech-to-Text Homepage. Für eine persönliche Demo unserer Voice Intelligence-Produkte füllen Sie das Demo-Buchungsformular aus.
Wenn Sie den SeaVoice Bot noch nicht ausprobiert haben, können Sie mehr über unseren Bot erfahren und ihn Ihrem Server über das SeaVoice Discord Bot Wiki hinzufügen. Fühlen Sie sich auch frei, unserem Offiziellen SeaVoice Discord Server beizutreten.


