





На протяжении всей этой серии блогов проследите путь Seasalt.ai к созданию полноценного опыта современных встреч, начиная с его скромных начал, до оптимизации нашего сервиса на различных аппаратных средствах и моделях, до интеграции передовых систем НЛП и, наконец, до полной реализации SeaMeet, нашего совместного решения для современных встреч.
Подводные камни современных встреч
На протяжении всей нашей разработки мы сталкивались со многими непредсказуемыми препятствиями без четких причин или решений.
Быстрый старт
Первым препятствием было заставить наши инструменты работать. Azure предоставила образец Modern Meetings, который, к нашей радости, был совместим с Linux, но мы обнаружили, что использовать SDK на Windows для запуска демонстрации было намного проще — ну, это был продукт Microsoft, в конце концов. После многих неудачных попыток запустить предоставленный образец на Linux, мы в конечном итоге были вынуждены отказаться от этого пути и прибегнуть к Windows. Наконец, у нас был функциональный транскриптор речи, что было огромным началом.
Задержка
Одной из проблем, с которой мы столкнулись, была задержка примерно в пять секунд при получении результатов распознавания на пользовательском интерфейсе. Хотя 5 секунд могут показаться довольно быстрыми, эта задержка заметно на несколько секунд слишком велика, чтобы быть удобным и практичным решением, особенно для связи в реальном времени.
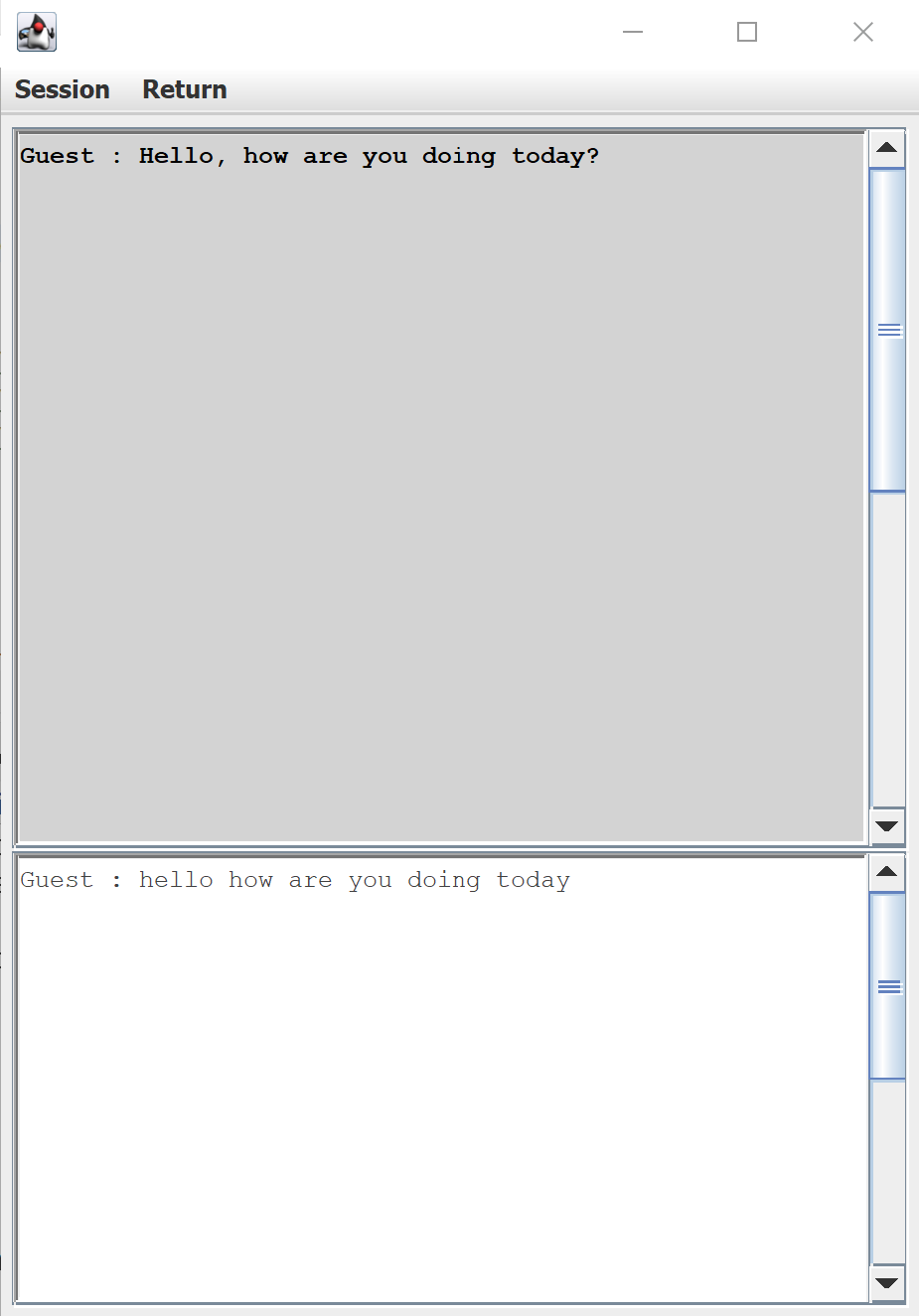
Пользовательский интерфейс по умолчанию для транскрипции речи, предоставляемый Azure Speech SDK
Задержка также была серьезной проблемой в бэкэнде. В начале каждой встречи результаты поступали в реальном времени (как и было обещано!), но по мере продолжения встречи задержка периодически взлетала до тридцати секунд, прежде чем текст появлялся на мониторах. К тому времени все сказанное давно стало неактуальным в разговоре. После бесчисленных тестов мы начали замечать, что задержка менялась в течение дня, что мы объясняли текущей нагрузкой на сервер Azure. Мы занимаемся созданием последовательного, надежного продукта, поэтому эти колеблющиеся и непредсказуемые задержки были неприемлемы. Тем более причина полагаться на наши собственные модели и серверы.
Диалект
Одной из конкретных причин, по которой мы изначально использовали Azure Speech Service, была их широкая поддержка большого разнообразия языков и диалектов. Мы были особенно рады использовать сингапурскую английскую модель Azure Speech Service. Но представьте наше удивление, когда мы обнаружили, что для сингапурского диалекта американская английская модель постоянно превосходила сингапурскую английскую модель. Более того, даже лучшая модель не соответствовала реальным мировым вызовам.
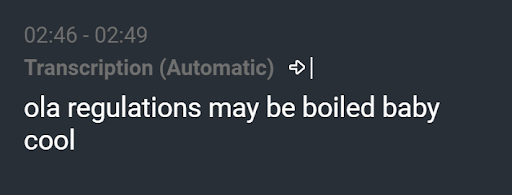
Полученная транскрипция “Поздравляем! Мальчик или девочка?”
Мы видели результаты вроде «ola regulations may be boiled baby cool», хотя на самом деле было сказано «Поздравляем! Мальчик или девочка?». Хорошо обученная языковая модель должна была исключить такую транскрипцию. Хотя это крайний пример, чаще всего в каждой транскрипции была ошибка. Независимо от того, насколько мала ошибка, например, пропущенный артикль или неправильно понятое слово, любая ошибка отвлекает и может легко испортить репутацию службы транскрипции.
Обновление Windows
Несколько недель спустя команда провела бессонные ночи, чтобы убедиться, что наш продукт готов к демонстрации клиенту, которая должна была состояться через несколько дней. Наш транскриптор встреч работал без сбоев на трех отдельных ноутбуках с Windows. Затем однажды, ни с того ни с сего, у нас остался только один работающий компьютер, хотя никто не трогал код. Мы тестировали наши сети, проверяли наши брандмауэры, все, что могло бы внезапно привести к сбою нашего продукта. Наше последнее предположение заключалось в том, что неожиданное обновление Windows сделало Azure Speech SDK необъяснимо несовместимым с двумя нашими компьютерами, когда мы сравнивали три системы бит за битом. С приближением нашей демонстрации стресс и напряжение достигли критической точки. С оставшейся всего одной системой команда заключила пакт: никаких изменений в коде и абсолютно никаких обновлений. После этого испытания нам было достаточно.
За пределами современных встреч
Чтобы избежать этих препятствий, команда Seasalt.ai приступила к обучению собственных акустических и языковых моделей, чтобы конкурировать с возможностями разговорного транскриптора Azure. На протяжении всего процесса мы постоянно задавали вопрос: куда мы движемся дальше? Как мы можем расширить этот уже инструментальный продукт?
Современные встречи продемонстрировали мощный потенциал преобразования речи в текст, но на этом все и заканчивается. Он может нас слушать, но что, если мы сможем заставить его думать за нас? При наличии только транскрипций, хотя продукт впечатляет, его применение несколько ограничено. Переход от транскрипции речи к речевому интеллекту открывает широкие возможности для того, что мы можем создать. Примеры интеллекта включают резюме встреч, абстракцию тем и извлечение действий. Наконец, разработка красивого интерфейса для объединения всего в потрясающий пакет.
И это история на данный момент, начало пути Seasalt.ai к предоставлению лучших бизнес-решений на быстро развивающийся рынок и их доставке миру. Если вы хотите узнать больше подробностей, пожалуйста, продолжайте читать остальную часть серии блогов.


