





Tout au long de cette série de blogs, suivez le parcours de Seasalt.ai pour créer une expérience de réunions modernes complète, en commençant par ses humbles débuts, en optimisant notre service sur différents matériels et modèles, en intégrant des systèmes PNL de pointe et enfin en réalisant pleinement SeaMeet, notre solution collaborative de réunions modernes.
Les pièges des réunions modernes
Tout au long de notre développement, nous avons rencontré de nombreux obstacles imprévisibles sans causes ni solutions claires.
Un démarrage rapide
Le premier obstacle a été de faire fonctionner nos outils. Azure a fourni un exemple de réunions modernes que nous étions heureux de voir compatible avec Linux, mais nous avons découvert qu’utiliser le SDK sur Windows pour exécuter la démo était beaucoup plus facile – eh bien, c’était un produit Microsoft après tout. Après de nombreuses tentatives infructueuses pour faire fonctionner l’exemple fourni sur Linux, nous avons finalement dû abandonner cette voie et nous tourner vers Windows. Finalement, nous avons eu un transcripteur vocal fonctionnel, ce qui était un excellent début.
Latence
Un problème que nous avons rencontré était un délai d’environ cinq secondes pour recevoir nos résultats de reconnaissance sur l’interface utilisateur frontale. Bien que 5 secondes puissent sembler assez rapides, ce délai est notablement quelques secondes trop lent pour être une solution pratique et pratique, surtout pour la communication en temps réel.
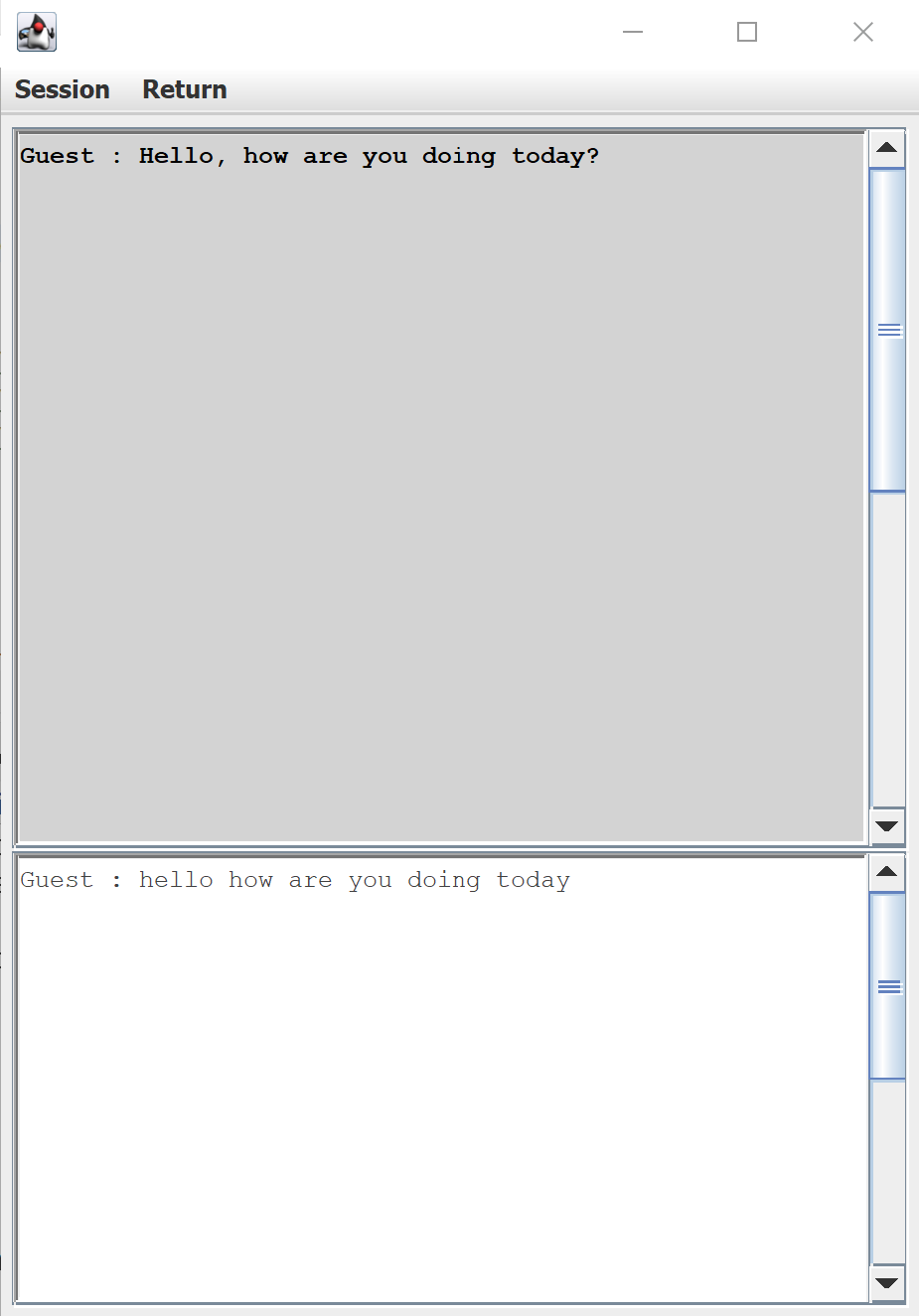
L’interface utilisateur par défaut pour la transcription vocale fournie par le SDK vocal Azure
La latence était également un problème sérieux en arrière-plan. Au début de chaque réunion, les résultats arrivaient en temps réel (comme annoncé !), mais au fur et à mesure que la réunion avançait, la latence montait en flèche périodiquement jusqu’à trente secondes avant que le texte n’apparaisse sur les moniteurs. À ce moment-là, tout ce qui avait été dit était depuis longtemps devenu sans rapport avec la conversation. Après d’innombrables tests, nous avons commencé à remarquer que la latence changeait tout au long de la journée, ce que nous avons attribué à la charge du serveur d’Azure à ce moment-là. Nous sommes dans le secteur de la création d’un produit cohérent et fiable, de sorte que ces retards fluctuants et imprévisibles étaient inacceptables. Raison de plus pour nous fier à nos propres modèles et serveurs.
Dialecte
Une raison particulière pour laquelle nous avons utilisé Azure Speech Service en premier lieu était leur large support d’une grande variété de langues et de dialectes. Nous étions particulièrement enthousiastes à l’idée d’utiliser le modèle d’anglais singapourien d’Azure Speech Service. Mais imaginez notre surprise en découvrant que, pour le dialecte singapourien, le modèle d’anglais américain surpassait constamment le modèle d’anglais singapourien. De plus, même le meilleur modèle n’a pas été à la hauteur des défis du monde réel.
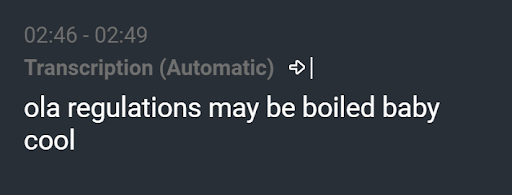
Transcription résultante de “Félicitations ! Garçon ou fille ?”
Nous avons vu des résultats comme « ola regulations may be boiled baby cool » alors que l’énoncé était en réalité « Félicitations ! Garçon ou fille ? ». Un modèle linguistique bien entraîné aurait dû éliminer une telle transcription. Bien que ce soit un exemple extrême, le plus souvent, il y aurait une erreur dans chaque transcription. Quelle que soit la taille de l’erreur, comme un article manquant ou un mot mal compris, toute erreur est distrayante et peut facilement ruiner la réputation d’un service de transcription.
Mise à jour Windows
Quelques semaines plus tard, l’équipe avait passé des nuits entières à s’assurer que notre produit était prêt pour la démonstration client qui devait avoir lieu dans quelques jours. Notre transcripteur de réunions fonctionnait sans problème sur trois ordinateurs portables Windows distincts. Puis un jour, de nulle part, nous nous sommes retrouvés avec un seul ordinateur fonctionnel, bien que personne n’ait touché au code. Nous avons testé nos réseaux, vérifié nos pare-feu, tout ce qui pouvait soudainement faire échouer notre produit. Notre dernière hypothèse était qu’une mise à jour Windows surprise avait rendu le SDK vocal Azure inexplicablement incompatible avec deux de nos ordinateurs lorsque nous avons comparé les trois systèmes bit par bit. Avec notre présentation qui approchait à grands pas, le stress et la tension étaient à leur paroxysme. Avec un seul système restant, l’équipe a conclu un pacte : pas de modification du code et absolument aucune mise à jour. Après cette épreuve, nous en avions assez.
Au-delà des réunions modernes
Pour échapper à ces obstacles, l’équipe de Seasalt.ai a entrepris de former ses propres modèles acoustiques et linguistiques pour rivaliser avec les capacités du transcripteur conversationnel d’Azure. Tout au long du processus, nous n’avons cessé de nous poser la question : où allons-nous à partir d’ici ? Comment pouvons-nous étendre ce produit déjà instrumental ?
Les réunions modernes ont démontré un solide potentiel de la parole au texte, mais c’est là que ça s’arrête. Il peut nous écouter, mais que se passerait-il si nous pouvions le faire penser pour nous ? Avec seulement des transcriptions, bien que le produit soit impressionnant, les applications sont quelque peu limitées. Passer de la transcription de la parole à l’intelligence de la parole ouvre de vastes possibilités pour ce que nous pouvons créer. Des exemples d’intelligence incluent les résumés de réunions, l’abstraction de sujets et l’extraction d’actions. Enfin, la conception d’une belle interface pour tout relier dans un package époustouflant.
Et c’est l’histoire jusqu’à présent, le début du voyage de Seasalt.ai pour apporter les meilleures solutions commerciales à un marché en évolution rapide et les livrer au monde. Si vous souhaitez en savoir plus sur les détails, veuillez continuer à lire le reste de la série de blogs.


