
To all Directors of Customer Service or Marketing, if your boss ask you the following question, send them this article:
“Why is intent/entity based NLU outdated and LLM/GenAI is the obvious trend?”
Natural Language Understanding (NLU) systems aim to process and analyze natural language inputs, such as text or speech, in order to derive meaning, extract relevant information, and understand the underlying intent behind the communication. NLU is a fundamental component of various AI applications, including virtual assistants, chatbots, sentiment analysis tools, language translation systems, and more. It plays a critical role in enabling human-computer interaction and facilitating the development of intelligent systems capable of understanding and responding to natural language inputs.
This question comes from established clients who are re-thinking their IVR and chatbot approach. They are locked into the previous generation of NLU-based tech stack, usually offered by big tech players such as: Microsoft Bot Framework (or luis.ai), IBM Watson NLU, Google DialogFlow, Meta’s wit.ai, Amazon Lex, SAP Conversational AI, Nuance Mix NLU.
The challenge is that major clients such as insurance companies, financial institutes, governments, airlines/car dealerships, and other big deals have already deployed the last-gen technology. But because the intent/entity-based NLU is not scalable, clients have to spend hundreds of thousands to millions of dollars every year to maintain and upgrade their NLU system. This lack of scalability contributes to rising maintenance costs, ultimately benefiting last-gen NLU providers at the expense of their clients. Because they don’t scale, the maintenance cost is higher year over year.
Why does intent/entity-based NLU fail to scale effectively?
The primary reason lies in the model’s limited discriminative power. Here’s a breakdown of why this is the case:
-
Minimum Intents Requirement: NLU models require at least two distinct intents to train effectively. For instance, when asking about the weather, the intent might be clear, but underlying each query are multiple potential intents, such as a fallback or non-weather related inquiries like “how are you?”
-
Training Data Demands: Big tech companies typically demand thousands of positive examples per intent for effective training. This extensive dataset is necessary for the model to learn and discriminate between different intents accurately.
-
Balancing Positive and Negative Examples: Adding positive examples to one intent necessitates the inclusion of negative examples for other intents. This balanced approach ensures the NLU model can learn from both positive and negative instances effectively.
-
Diverse Example Sets: Both positive and negative examples must be diverse to prevent overfitting and enhance the model’s ability to generalize across different contexts.
-
Complexity of Adding New Intents: Adding a new intent to an existing NLU model involves a laborious process. Thousands of positive and negative examples must be added, followed by retraining the model to maintain its baseline performance. This process becomes increasingly challenging as the number of intents grows.
The Prescribing Effect: The Pitfall of Intent/Entity-Based NLU

The Prescribing Effect of Intent/entity based NLU
Analogous to the phenomenon in medicine known as a “prescribing cascade,” the scalability challenges of intent/entity-based NLU can be likened to a daunting cascade of prescriptions. Picture an elderly individual burdened with a plethora of daily medications, each prescribed to address the side effects of the previous one. This scenario is all too familiar, where the introduction of Medicine A leads to side effects necessitating the prescription of Medicine B to counteract them. However, Medicine B introduces its own set of side effects, prompting the need for Medicine C, and so on. Consequently, the elderly person finds themselves inundated with a mountain of pills to manage—a prescribing cascade.
Another illustrative metaphor is that of building a tower of blocks, with each block representing a medication. Initially, Medicine A is placed, but its instability (side effects) prompts the addition of Medicine B to stabilize it. However, this new addition may not integrate seamlessly, causing the tower to lean further (side effect of B). In an effort to rectify this instability, more blocks (Medications C, D, etc.) are added, exacerbating the tower’s instability and susceptibility to collapse—a representation of the potential health complications arising from multiple medications.

Another illustrative metaphor for intent/entity based NLU is building a tower of blocks
Similarly, with each new intent added to an NLU system, the metaphorical tower of blocks grows taller, increasing the instability. The need for reinforcement escalates, resulting in higher maintenance costs. Consequently, while intent/entity-based NLU may seem appealing to providers initially, the reality is that it becomes excessively burdensome for clients to maintain. These systems lack scalability, posing significant challenges for both providers and clients alike. In the subsequent sections, we will explore how GenAI/LLM-based NLU offers a more sustainable and scalable alternative to address these challenges effectively.
GenAI/LLM-based NLU: A Resilient Solution
GenAI/LLM-based NLU offers a robust solution to the scalability challenges faced by intent/entity-based systems. This is primarily attributed to two key factors:
-
Pre-Training and World Knowledge: GenAI/LLM models are pre-trained on vast amounts of data, enabling them to inherit a wealth of world knowledge. This accumulated knowledge plays a crucial role in discerning between various intents, thereby enhancing the model’s discriminative capabilities against negative examples.
-
Few-Shot Learning: One of the hallmark features of GenAI/LLM-based NLU is its ability to employ few-shot learning techniques. Unlike traditional methods that require extensive training data for each intent, few-shot learning enables the model to learn from just a few examples. This efficient learning approach reinforces the intended objectives with minimal data, significantly reducing the training burden.
Consider this scenario: when presented with the query “What’s the weather today?” as a reader, you instinctively recognize it as an inquiry about the weather amidst the multitude of sentences encountered daily. This innate ability to discern intent is akin to the concept of few-shot learning.
As adults, our brains are pre-trained with a vast vocabulary, estimated to be around 150 million words by the age of 20. This extensive linguistic exposure enables us to quickly grasp new intents upon encountering them, requiring only a few examples for reinforcement.
The Urban Dictionary serves as an excellent resource for exploring examples of few-shot learning in action, further illustrating its efficacy in facilitating rapid understanding.
The few-shot learning capability inherent in GenAI/LLM-based NLU is instrumental in reducing costs and enabling scalability. With the bulk of training already completed during pre-training, fine-tuning the model with a minimal number of examples becomes the primary focus, streamlining the process and enhancing scalability.
GenAI/LLM-based NLU: Delivering Results and Evidence
As of March 2024, the landscape of natural language processing (NLP) has undergone a significant shift, marked by the emergence of GenAI/LLM-based NLU as a game-changer. The once-dominant progress in NLP innovation has plateaued over the past 2-3 years, as evidenced by the stagnation in state-of-the-art advancements. If you check the once-hottest NLP progress for the state of the art, it mostly stopped 2-3 years ago:
We used to track NLP innovation on this Github Repo. The update mostly stopped 2-3 years ago.
One notable benchmark that underscores this paradigm shift is the SuperGlue leaderboard, with its latest entry in December 2022. Interestingly, this time frame coincides with the introduction of ChatGPT (3.5), which sent shockwaves across the NLP community.
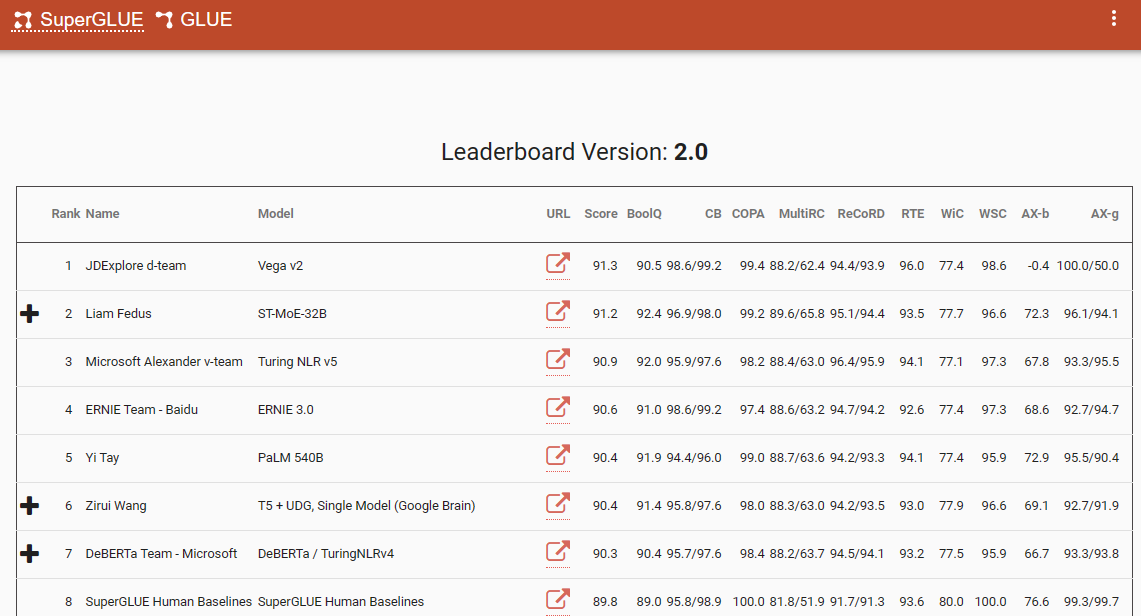
SuperGlue leaderboard was popular until the introduction of ChatGPT
The seminal GPT-3 paper, aptly titled “Language Models are Few-Shot Learners”, offers compelling evidence of the efficacy of few-shot learning. Figure 2.1 on page 7 in the paper delineates the distinctions between zero-shot, one-shot, and few-shot learning approaches, highlighting the superiority of the latter in terms of learning efficiency and effectiveness.

The distinctions between zero-shot, one-shot, and few-shot learning approaches
Further corroborating the efficacy of GenAI/LLM-based NLU is Table 3.8 on page 19, which provides a direct comparison between traditional supervised NLU methods and GPT-3 Few-Shot learning. In this comparison, GPT-3 Few-Shot surpasses Fine-tuned BERT-Large, a representation of supervised learning employed by intent/entity-based NLU systems, across various tasks.
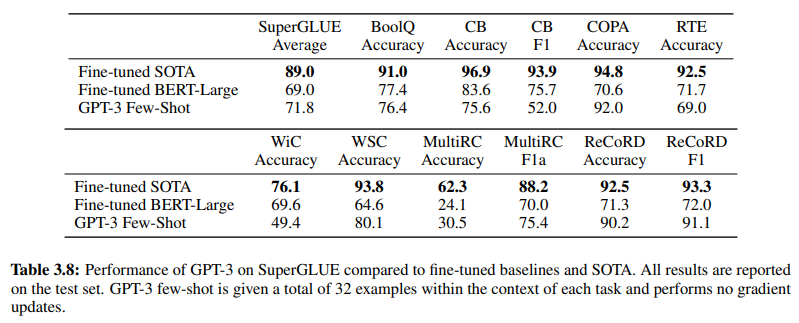
GPT-3 Few-Shot surpasses Fine-tuned BERT-Large across various tasks
The superiority of GPT-3 Few-Shot is not only evident in its accuracy but also in its cost-effectiveness. Both the initial setup and maintenance costs associated with GenAI/LLM-based NLU are significantly lower compared to traditional methods.
The empirical evidence presented in the NLP community underscores the transformative impact of GenAI/LLM-based NLU. It has already demonstrated its unparalleled accuracy and efficiency. Next, let’s check out its cost effectiveness.
Training Data Requirements: A Comparative Analysis
A revealing comparison between intent/entity-based NLU and GenAI/LLM-based NLU sheds light on their disparate training data requirements. Figure 3.8 on page 20 provides a stark contrast:
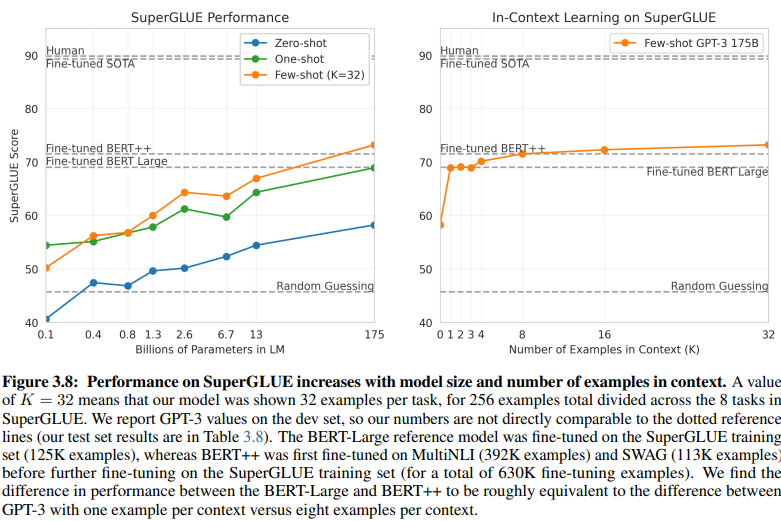
GenAI/LLM-based NLU requires a lot smaller data for training
-
Supervised Learning NLU: This traditional approach necessitates an extensive dataset, with over half a million examples (630K) required for effective training.
-
Few-Shot GPT-3: In contrast, GenAI/LLM-based NLU demonstrates remarkable efficiency, with only 32 examples per task sufficient for effective tuning.
The magnitude of this difference is striking: 630,000 examples versus a mere 32. This dramatic reduction in training data requirements translates to significant cost savings for businesses adopting GenAI/LLM-based NLU.
Moreover, the implied impact on development timelines is profound. With GenAI/LLM-based NLU, the shortened training process accelerates the deployment of NLU systems by multiple factors of magnitude, facilitating rapid adaptation and innovation in the realm of natural language processing.
In essence, this comparison underscores the transformative potential of GenAI/LLM-based NLU, offering unparalleled efficiency and cost-effectiveness in training data requirements and development timelines.
Embracing the Evolution: Why GenAI/LLM-Based NLU Prevails
In the realm of natural language understanding, the transition from intent/entity-based systems to GenAI/LLM-based solutions is indisputably underway. This shift is propelled by a multitude of factors that underscore the limitations of traditional intent/entity-based NLU and the compelling advantages offered by GenAI/LLM-based approaches.
Intent/entity-based NLU is increasingly deemed outdated for several compelling reasons:
-
Limited Flexibility: Traditional NLU systems hinge on predefined intents and entities, constraining the adaptability of chatbots and IVRs to user inputs that deviate from these predefined categories.
-
Maintenance Challenges: As these systems scale and the number of intents and entities proliferates, the complexity and time required for maintenance and updates escalate exponentially.
-
Lack of Contextual Understanding: These systems often falter in grasping the contextual nuances of conversations, resulting in inaccurate responses or the need for additional user input to clarify intentions.
-
Lack of Generation: Intent and entity-based NLU systems are inherently limited in their capability to generate text, confining them to tasks centered around classifying intents and extracting entities. This restricts the adaptability of chatbots and IVRs, often leading to monotonous responses that fail to align with the conversational context.
In stark contrast, GenAI/LLM-based NLU emerges as the prevailing trend due to its transformative attributes:
-
Adaptive Learning: GenAI models possess the capacity to learn dynamically from real-time conversations, enabling them to acclimate to new topics and user behaviors autonomously, without necessitating manual updates.
-
Contextual Comprehension: These models excel in comprehending the intricate contextual nuances of conversations, resulting in more precise and relevant responses that resonate with users.
-
Few-Shot Learning: GenAI models can be trained with minimal examples, streamlining the training process and reducing the dependency on explicit intent and entity definitions.
-
Natural Language Generation: GenAI/LLMs boast the capability to generate text, empowering them to create chatbots and other NLP applications that deliver natural and contextually relevant responses.
The future of conversational AI hinges on systems that can learn and adapt organically, providing users with a seamless and intuitive experience. GenAI/LLM-based NLU embodies this evolution, offering a dynamic and flexible approach that transcends the constraints of traditional intent/entity-based systems.
In essence, the prevailing trajectory of NLU is unequivocally defined by the ascendancy of GenAI/LLM-based approaches, heralding a new era of conversational AI that prioritizes adaptability, contextuality, and user-centricity.
 Subscribe
Subscribe