
Throughout this blog series, follow Seasalt.ai’s journey to creating a well rounded Modern Meetings Experience, starting with its humble beginnings, to optimizing our service on different hardware and models, to integrating state-of-the-art NLP systems and finally ending on the full realization of SeaMeet, our collaborative modern meeting solutions.
Beyond Transcription
All of the previous obstructions that we faced taught us an important lesson: that we could do all this better by ourselves. So the crew here at Seasalt.ai set out training our own acoustic and language models to rival the capabilities of Azure’s conversational transcriber. Microsoft put on an amazing presentation at MS Build 2019, showcasing Azure’s Speech Services as both a highly capable yet very accessible product. After being wowed, we are forced to ask the question, where do we go from here? How can we expand on this already instrumental product? Modern Meetings demonstrated robust speech to text potential, but that is where it stops. We know Azure can listen to us, but what if we can make it think for us? With just transcriptions, while the product is impressive, the applications are somewhat limited.
By integrating the existing speech-to-text technology with systems that can produce insights from the transcriptions, we can deliver a product that exceeds expectations and anticipates user needs. We decided to incorporate three systems to improve the overall value of our SeaMeet transcriptions: summarization, topic abstraction, and action item extraction. Each of these were chosen to alleviate specific user pain points.
To demonstrate, we will show the result of running the summarizations, topics, and actions systems on the following short transcript:
Kim: "Thank you, Xuchen you're muted because a lot of people are on this call. Press Star 6 to unmute.”
Xuchen: "OK I I thought well it's just bad reception.",
Kim: "Yeah.",
Sam: "I just sent out a separate file with speech data for Tuesdays until until 30 days. You guys should have should have some updated versions.",
Kim: "So there will definitely be edge cases where this doesn't work. I already found a couple like in this example. It takes like out of the verb there and says the speaker is the assignee when it's really more carol is the assignee there. but it's the same pattern as something like the second one where you really want I to be the assignee because they're not assigning Jason they're assigning themselves to tell Jason.",
Sam: "Got it.",
Xuchen: "So the downside of this it is you kind of have to write rules for it. Yeah, the upside is it is an already trained model. You can train it further an but we don't have to throw a ton of data at this.",
Kim: "Although it doesn't do the classification that would get us Is this an action or is this other?",
Xuchen: "So, so the trick here is that we want the auxiliary verb to be to be present, but also we would also want some person names.",
Sam: "Right otherwise may because.",
Xuchen: "Yeah, if if there's a sentence with you know there are a lot of instances with obviously words. However, not many of them would help the actions."
Summarization
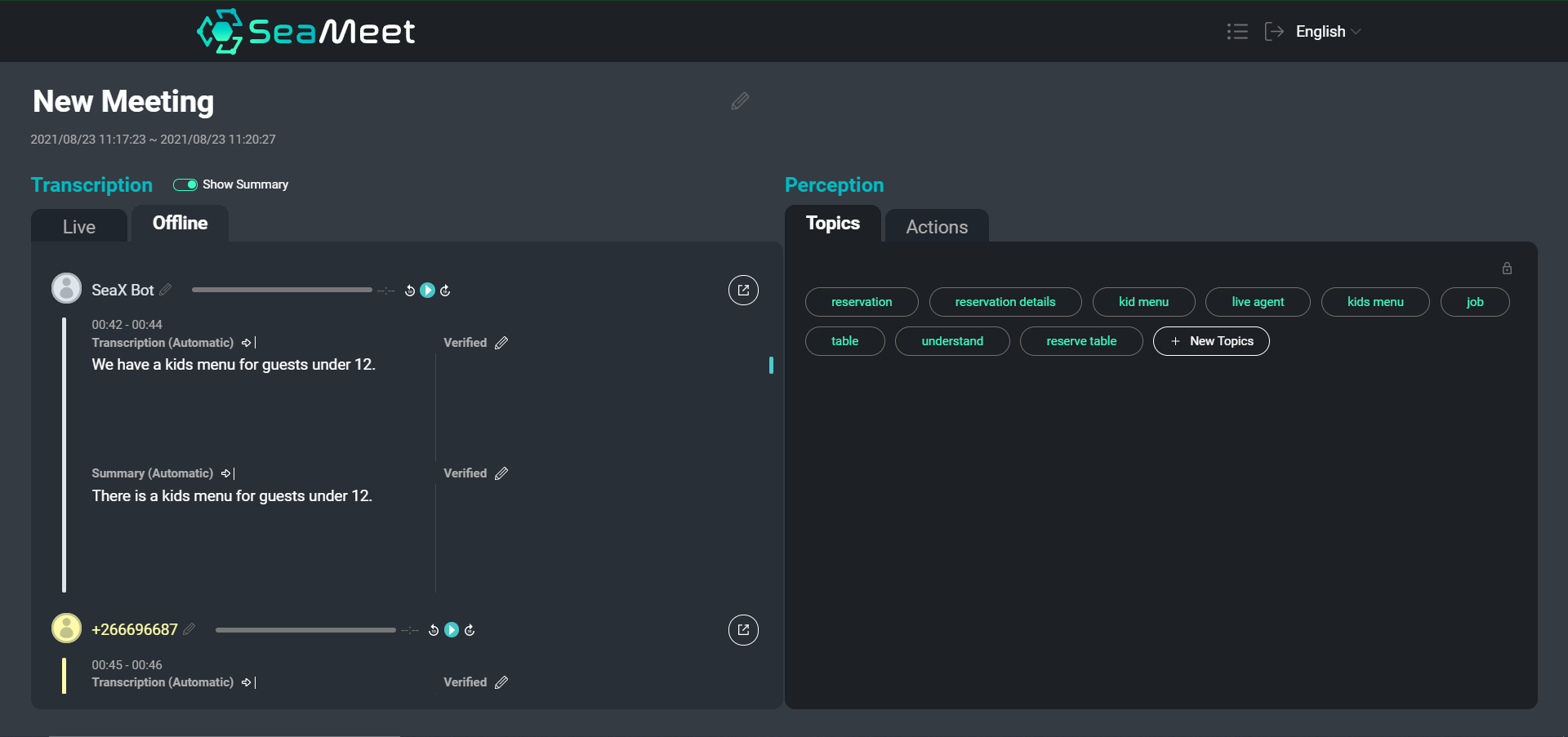
An overview of our SeaMeet interface, featuring user utterances with their short summaries on the left
While navigating a text transcription is certainly easier than digging through hours of recorded audio, for particularly long meetings it can still be time consuming to find specific content or get an overview of the conversation as a whole. We chose to provide two types of summaries in addition to the full transcription.
Summaries at the individual utterance level provide more concise, easy to read segments. Additionally, the short summaries help normalize the text by removing semantically empty segments and performing anaphora & co-reference resolution. We can then feed the summarized segments into downstream applications (such as topic abstraction) to improve the end results.
In addition to the short summaries, we also chose to provide a single long summary which aims to create a very general overview of the entire meeting. This summary functions like an abstract for the meeting, covering only the main talking points and conclusions.
The following is an example of the short summaries, where we fed each segment in the original transcript through the summarizer:
Kim: "Xuchen is muted because a lot of people are on the call."
Xuchen: "It's just bad reception."
Sam: "I sent a separate file with speech data for Tuesdays until 30 days."
Kim: "There will be edge cases where this doesn't work."
Xuchen: "The downside of training an already trained model is that you have to write rules for it."
Kim: "The classification doesn't do the classification that would get them an action."
Xuchen: "The trick here is that they want the auxiliary verb to be to be present, but also they would also want some person names."
Xuchen: "If there is a sentence with words, not many of them would help the actions."
And this example shows the entire meeting summarized into a single paragraph:
“Xuchen is muted because a lot of people are on the call. Sam sent a separate file with speech data for Tuesdays until 30 days. Xuchen has found some edge cases where the speaker is the assignee.”
At the core of both the short and long summarization components is a transformer-based summarization model. We fine tune the model on a dialogue dataset for abstractive summarization. The data contains textual excerpts of various lengths each paired with a hand written summary. For multilingual summarization, we use the same paradigm, but utilize a multilingual base model fine tuned on a translated version of the dataset. From the SeaMeet interface, the user also has the option to verify a machine-produced summary, or provide their own. We can then collect these user-inputted summaries and add them back to our training set to continually improve our models.
Topic abstraction
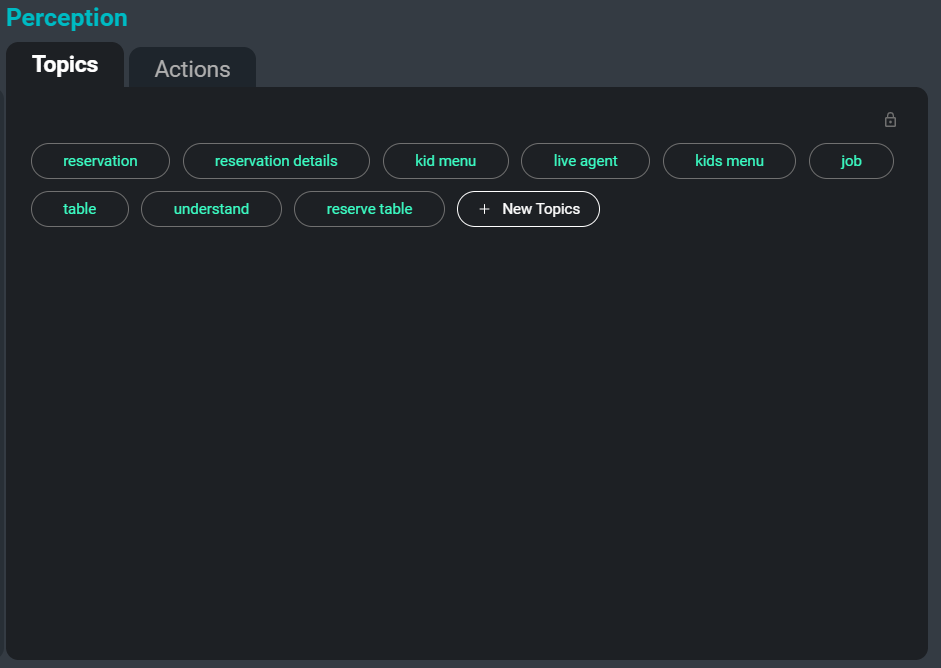
The SeaMeet interface, focused on the ‘Topics’ tab on the right hand side
Another problem when dealing with large collections of transcriptions is organizing, categorizing, and searching them. By automatically abstracting keywords and topics from the transcript, we can provide users with an effortless way to track down certain meetings, or even specific sections of meetings where a relevant topic is under discussion. Additionally, these topics serve as another method of summarizing the most important and memorable information in a transcript.
Here is an example of keywords that would be extracted from the sample transcript:
auxiliary verb
speaker
speech data
separate file
updated versions
person names
trained model
write rules
The topic extraction task uses a combination of abstractive and extractive approaches. Abstractive refers to a text classification approach, where each input is classified into a set of labels seen during training. For this method we used a neural architecture trained on documents paired with a list of relevant topics. Extractive refers to a keyphrase search approach where relevant keyphrases are extracted from the provided text and returned as topics. For this approach, we use a combination of similarity metrics such as cosine similarity & TF-IDF in addition to word co-occurrence information to extract the most relevant keywords and phrases.
The abstractive and extractive techniques both have pros and cons, but by using them together we can take advantage of the strengths of each. The abstractive model is great at collecting distinct, but related details and finding a slightly more generic topic that suits them all. However, it can never predict a topic that it has not seen during training, and it is impossible to train on every conceivable topic that may come up in a conversation! The extractive models, on the other hand, can pull keywords and topics directly from the text, meaning that it is domain independent, and can extract topics it has never seen before. The drawback to this approach is that sometimes the topics are too similar or too specific. By using both we have found a happy medium between generalizable and domain-specific.
Action Item Extraction
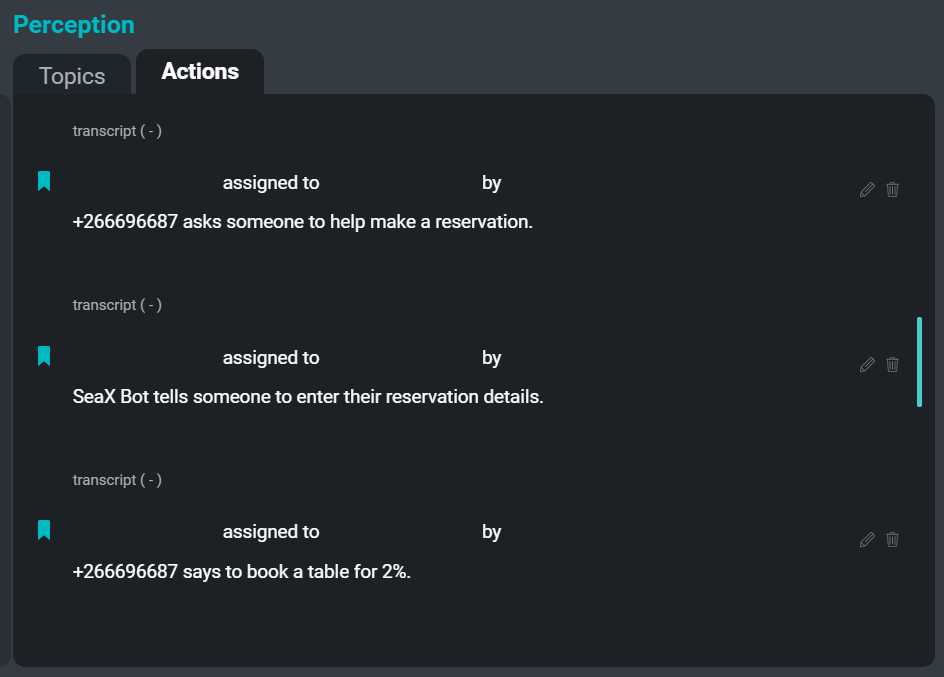
The SeaMeet UI, focused on the ‘Actions’ tab on the right hand side
The final pain point we set out to alleviate for users is the task of recording action items. Recording action items is a very common task that is assigned to an employee to do during a meeting. Writing down ‘who told whom to do what when’ can be extremely time consuming, and can cause the writer to be distracted and unable to fully participate in the meeting. By automating this process, we hope to alleviate some of that responsibility from the user so that everyone can devote their full attention to participating in the meeting.
The following is an example of some action items that could be extracted from the example transcript:
suggestion: "Sam says the team should have some updated versions."
statement: "Kim says there will definitely be edge cases where this doesn't work."
imperative: "Xuchen says someone has to write rules for it."
desire: "Xuchen says the team wants the auxiliary verb to be present, but also wants some person names."
The purpose of the Action Extractor system is to create short abstractive summaries of action items extracted from meeting transcriptions. The result of running the Action Extractor over a meeting transcription is a list of commands, suggestions, statements of intent, and other actionable segments that can be presented as to-dos or follow-ups for the meeting participants. In the future, the extractor will also capture the names of assignees & assigners as well as due dates tied to each action item.
The action extraction pipeline has two main components: a classifier and a summarizer. First, each segment is passed into a multi-class classifier and receives one of the following labels:
- Question
- Imperative
- Suggestion
- Desire
- Statement
- Non-actionable
If the segment receives any label other than ‘non-actionable’, it is sent to the summarization component along with the previous two segments in the transcript, which provide more context for the summarization. The summarization step is essentially the same as the stand-alone summarization component, however the model is trained on a bespoke dataset constructed specifically for summarizing action items with a desired output format.
SeaMeet Gets a Brain
This has been a big step towards creating our own unique product: training summarization plus topic and action extraction models to take our product even further, and designing a beautiful interface to tie everything together in a stunning package. This is the story so far, the start of Seasalt.ai’s journey to bringing the best business solutions to a rapidly evolving market and delivering to the world, SeaMeet: The Future of Modern Meetings.
