
After launching SeaVoice, one of the fastest and most accurate text-to-speech and speech-to-text bots on Discord, we wanted to understand how users were actually interacting with the services. In this blog we’ll discuss our findings after reviewing several weeks of real speech-to-text user data.
SeaVoice: A Text-to-Speech & Speech-to-Text Discord Bot
Discord, being a platform primarily used for a combination of audio and text-based chatting, is a fantastic testing ground for voice intelligence and natural language processing services. We deployed the SeaVoice Bot, equipped with text-to-speech and speech-to-text commands, to Discord in August of 2022. To learn more about how the bot works, or see a short video demo, you can visit the SeaVoice Bot wiki. In November of the same year, we released a new version with significant backend improvements (as described in our blog post: SeaVoice Discord Bot: Backend & Stability Improvements) that allow us to record anonymous data on how users are interacting with the SeaVoice bot. In our last blog (TTS Discord Bot Case Study) we analyzed 1 month of user data from the text-to-speech command. As a follow up, in this post we’ll be taking a look at about 3 weeks worth of speech-to-text user data.
SeaVoice STT Usage
At the time of writing, the SeaVoice Bot has been added to nearly 900 servers! About 260 servers totalling over 600 participants have actually tried out the STT command at least once. In the past 3 weeks we have hosted nearly 1,800 STT sessions and output a total of over half a million transcription lines.
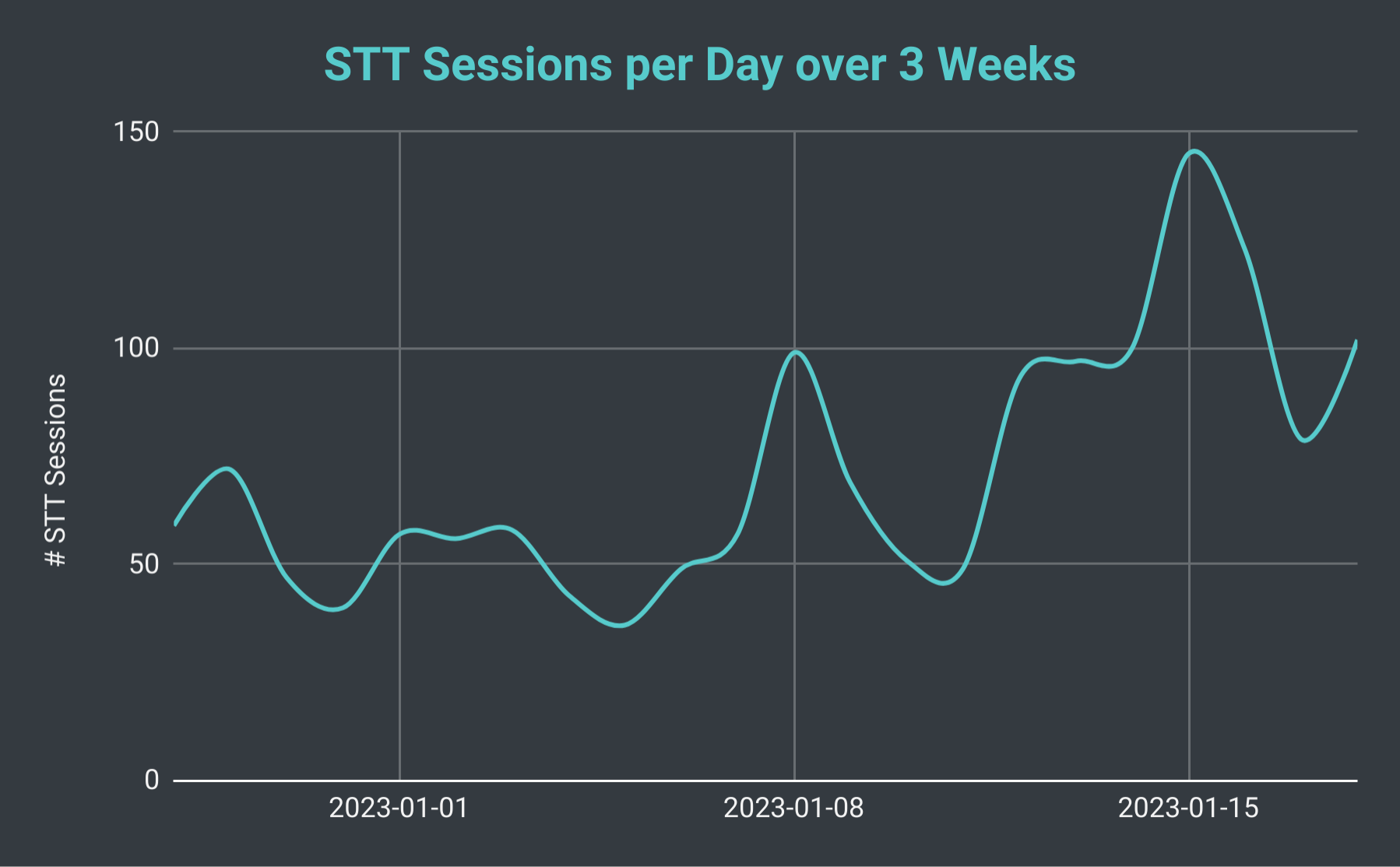
SeaVoice Discord Bot daily speech-to-text sessions over 3 weeks.
If we look at the total number of STT sessions per day, we’ve found that it can fluctuate from as little as 40 to over 140 (with an average of about 70). We can also consider the total number of transcription lines we are producing. On the slowest day, we produce as few as 10 thousand lines, however, on a busy day we have produced upwards of 40 thousand lines. To put that into perspective, on January 18th, we hosted 102 STT sessions with a total of just under 30 thousand transcription lines; that amounted to nearly 40 hours of recording time.
We also found that while most sessions are used for shorter conversations (median of 57 lines per session), there are a significant number of very long sessions that draw the average up to 650 lines per session. Our longest session was over 30 thousand lines, more than an average day’s worth! Finally we also took a look at how many users tend to be in each session and found that there are typically 4 to 5 users in each session - however we did once use the bot to support live transcription at a virtual seminar which had 45 participants!
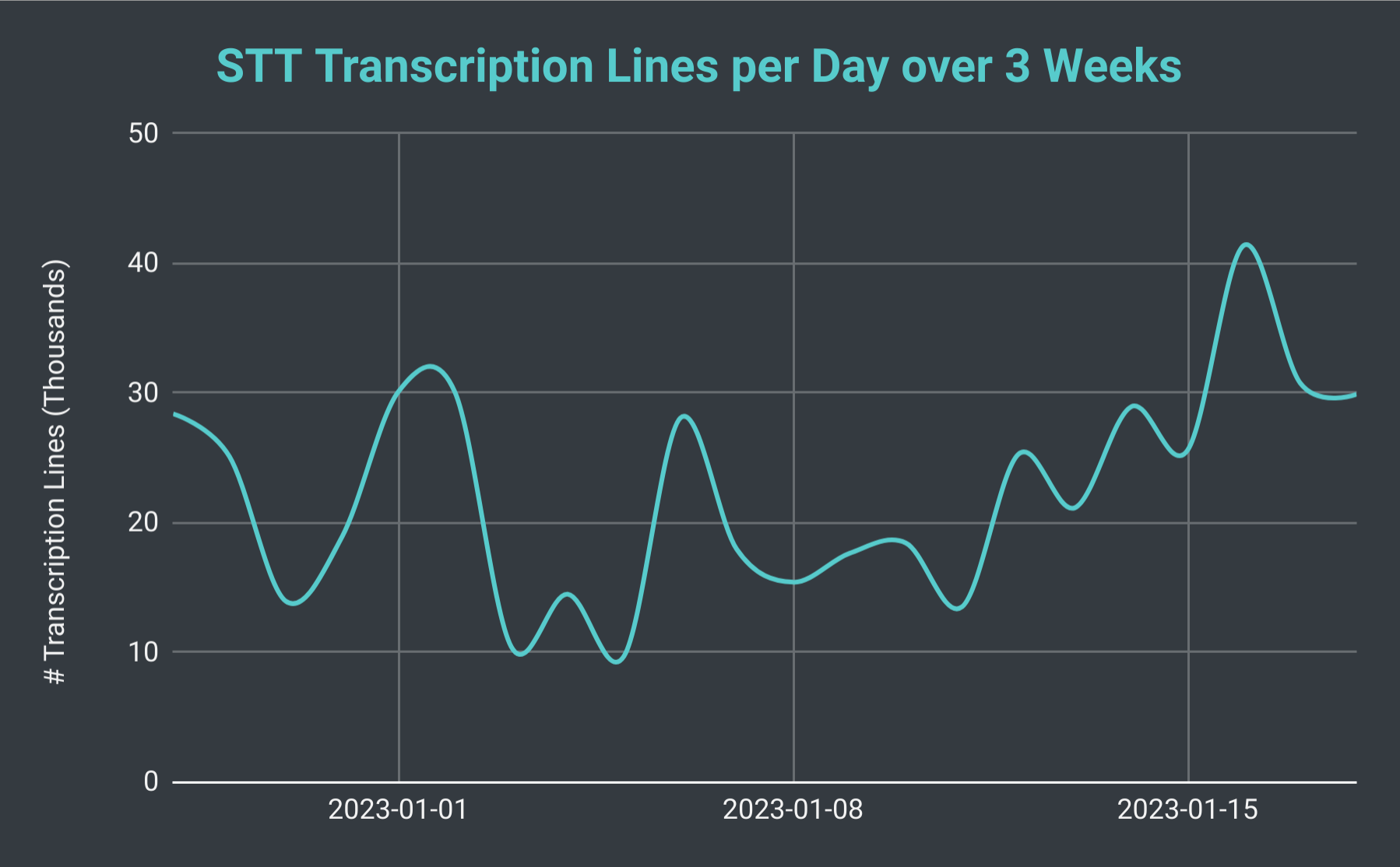
SeaVoice Discord Bot lines transcribed per day over 3 weeks.
While the majority of servers have not used the STT session more than a few times, there are quite a few that use the service extensively. Since we started recording the STT usage data in late December, the average total number of sessions per server is about 7; however, our #1 server has logged 131 sessions - That’s an average of over 6 sessions per day! That same server has transcribed over 150 thousand lines of speech in just 3 weeks! Perhaps more impressive than that, our #1 user is from the same server and has had over 60 thousand lines of their own speech transcribed!
Observations
Why People Use Speech-to-Text

A SeaVoice Discord bot user expresses excitement about the persisted audio and transcription files.
So our first question after seeing the usage data is: why are the frequent users utilizing speech-to-text in the first place?
We looked through the database to find some explanations. However, it proved more difficult to find concrete explanations of why users were utilizing the STT service as opposed to the TTS service. Apparently people feel the need to explain to the others in the chat why they are using TTS, but less so with STT. Regardless, I did find some interesting transcriptions that gave some insight into why users decide to utilize the STT service.
Why users utilize STT:
- “This is why the transcript’s used for because I can look at things that I missed.”
- “[user] is hard of hearing, so he gets a bot that transcribes it”
- “[user] raids with them and they use it to transcribe stuff, but then [user] was like, oh, we can use that for ******* D and D stuff, too”
- “I can’t wait to go back and read some of these transcripts later […] I want to go listen to that recording and look at that transcript again”
- “If we have our meetings here, then we can feed like the transcript of the meeting into AI”
- “During a meeting with people, that’s great to actually see a transcript”
- “[people] who aren’t in the chat or people who are in the community, but not part of the voice chat, but they decide to look and read”
So in general, it seems that most users enjoy the convenience of having a live transcription that can help them keep track of the conversation and fill any gaps that they missed. This is particularly the case for users who have a hearing impairment or audio/connection difficulties. For some users the biggest perk is keeping a permanent audio and text record of their conversation; this could be particularly applicable for use cases like maintaining a Dungeons & Dragons session log or keeping record of important meetings.
Because a lot of users didn’t explicitly say why they were using the STT service, it also seemed useful to get a sense of what they were doing while utilizing the bot. Reviewing the transcriptions from users gave me hints as to what activities they were doing while transcribing:
What users are doing while utilizing STT:
- Just chatting
- Gaming:
- Casual gaming
- Advanced gaming (ex/ coordinating group MMO, Massive Multiplayer Online, raids)
- Role playing games (Dungeons & Dragons)
- Streaming / recording content
- Discussing school / professional / volunteer work
The vast majority of transcriptions fall into the “just chatting” and “casual gaming” categories. As we saw above, I think most users in this case utilize the bot to improve the accessibility of the Discord voice channel and/or enjoy the convenience of seeing the live transcription to fill any gaps they missed in the conversation. In some cases (like when used for MMO raids), the gaming discussions are very complex and users are coordinating with each other in real-time; live transcriptions could prove extremely useful to the success of the team as users can reference the transcripts as they’re playing.
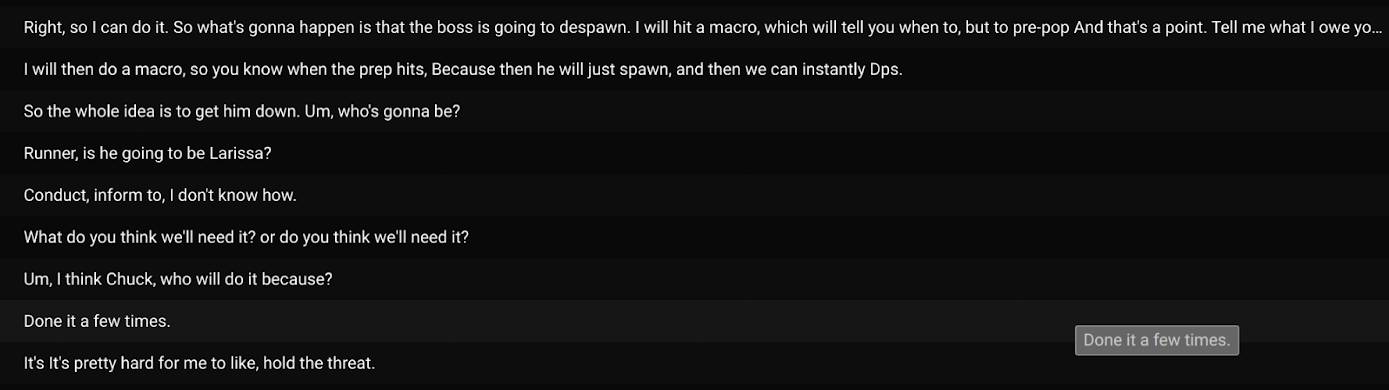
Example of complex discussion during an MMO raid.
It also seems that a lot of users are using the bot to transcribe more serious conversations such as school, professional and/or volunteer community meetings. We also had our bot used to transcribe an online tech conference, UnTechCon. In these cases the final recording and transcription files may prove very helpful to users for review after the meeting. One last interesting example I found was a user recording content for their stream. Because the final transcript comes with timestamps, users could potentially upload the transcript file as subtitles for their recorded audio or video content.
A SeaVoice user expresses thanks for making Discord voice channels more accessible.
But regardless of the exact reason they use the STT service, many users expressed excitement that they were able to participate in the voice channel conversations when they otherwise would not be able to. We believe that the STT service makes Discord voice channels more accessible, and that is the main reason our regular users keep utilizing the service.
Commentary about the SeaVoice Discord Bot
Another interesting topic found in the logs was commentary about the bot itself. Thankfully, we saw several very positive comments about the bot and its performance.

A SeaVoice comments on the transcription accuracy.
We also found several bits of constructive feedback.

A SeaVoice suggests improvement for British accents.

A user compares SeaVoice’s performance on accented English to Siri’s.
Most of the constructive comments had to do with the bot not performing well on non-American accented English; in particular users mentioned British and Scottish accents. For the future of our STT services, we could put significant effort into improving our speech recognition for various accents of English. Of course, English isn’t the only language our users speak, so we also plan to add more language support to the bot. In fact, we are currently finalizing our Taiwanese Mandarin STT and TTS integrations, and will be releasing an updated version of the bot shortly.
Privacy, Data Sensitivity, & Potentially Offensive Content
AI development is surrounded by a torrent of ethical dilemmas. Our models need massive amounts of real user data to perform well, but how do we collect that data ethically while respecting our users’ privacy? Models learn only based on the data they are provided and therefore have (potentially unforeseen) biases; so how can we make sure our models serve all our users equally well? Furthermore, our models have no concept of social acceptability and may produce results that some users find offensive. As one of our users put it so eloquently: “Is it racist if the bot does it though, that’s the question”.

A SeaVoice user points out a problematic inaccurate transcription.
The reason I bring up these points is because of a few concerning transcriptions in the logs. The first issue is that the bot occasionally transcribes offensive content. In the example above, the bot accidentally transcribed someone’s username as a racial slur. Obviously this an error on the bot’s end which may be offensive to our users and should be investigated. But this leads to more questions: where do we draw the line between offense and harm?

A SeaVoice user comments on trying to censor certain words from the transcription.
Well, to start we’ve decided to give that power to the users. One of the next features we will work on is configurable censorship of TTS and STT. This will allow servers to optionally apply censors for swear words, sexual content, racial slurs, etc.

A SeaVoice user warns another participant to be conscious that what they say will end up in the transcript.
Interestingly, another related issue we saw was users self-censoring themselves to avoid having certain things appear in the transcript. This was surprisingly common, and I saw many cases where users explained that they didn’t want the bot to transcribe what they were about to say so they stopped and then restarted the STT. This is a completely valid concern on the user’s end if for example they don’t want the bot to transcribe some sensitive information.
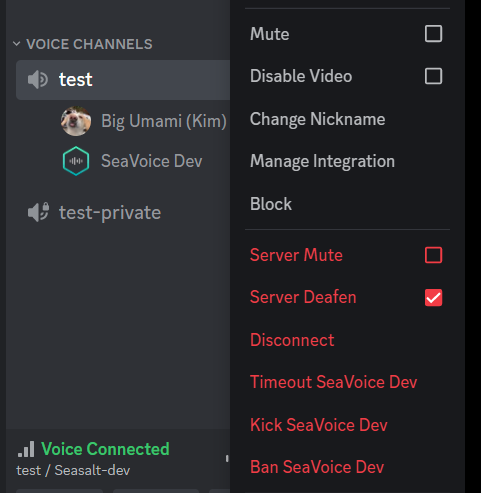
How to pause the STT by deafening the bot.
I’m not sure that there’s any way we can improve the user experience in this case, but I would advise users that they can “deafen” the bot temporarily to stop sending any audio to the bot. In this case, the bot will receive zero audio data until it is un-deafened, so the user can essentially pause the STT session without stopping and starting a new one.

A SeaVoice user comments on another participant’s discomfort with the bot.
Finally, the last issue we saw is that some users feel so uncomfortable with the bot transcribing that they actively avoid speaking in the voice channel while the bot is present. This is the complete opposite of our goal, which is to make Discord voice channels more accessible for everyone. While we hope that users will accept our privacy policy and trust us to use their data responsibly, we absolutely respect everyone’s right to privacy. As such, the next feature we will be implementing is an STT opt-out setting. This will allow any user to exclude themselves from the STT recording and transcription, and their audio data will not be accessed or collected in any way by the bot.
We hope that these planned features will allow us to continue making voice channels more accessible for everyone while giving users the agency to interact with the SeaVoice Bot on a level they are comfortable with. Moving forward we will continue to make an effort to proactively address these challenging issues in order to make SeaVoice the best it can be!
Thank you for your interest in our Discord Bot and thanks to our users for your continued support! You can learn more about our STT product on our SeaVoice Speech-to-Text Homepage. For a one-on-one demo of any of our Voice Intelligence products, fill out the Book a Demo Form.
If you haven’t tried out the SeaVoice bot yet, you can learn more about our bot and add it to your server from the SeaVoice Discord Bot Wiki. Also feel free to join our Official SeaVoice Discord Server.
 Subscribe
Subscribe